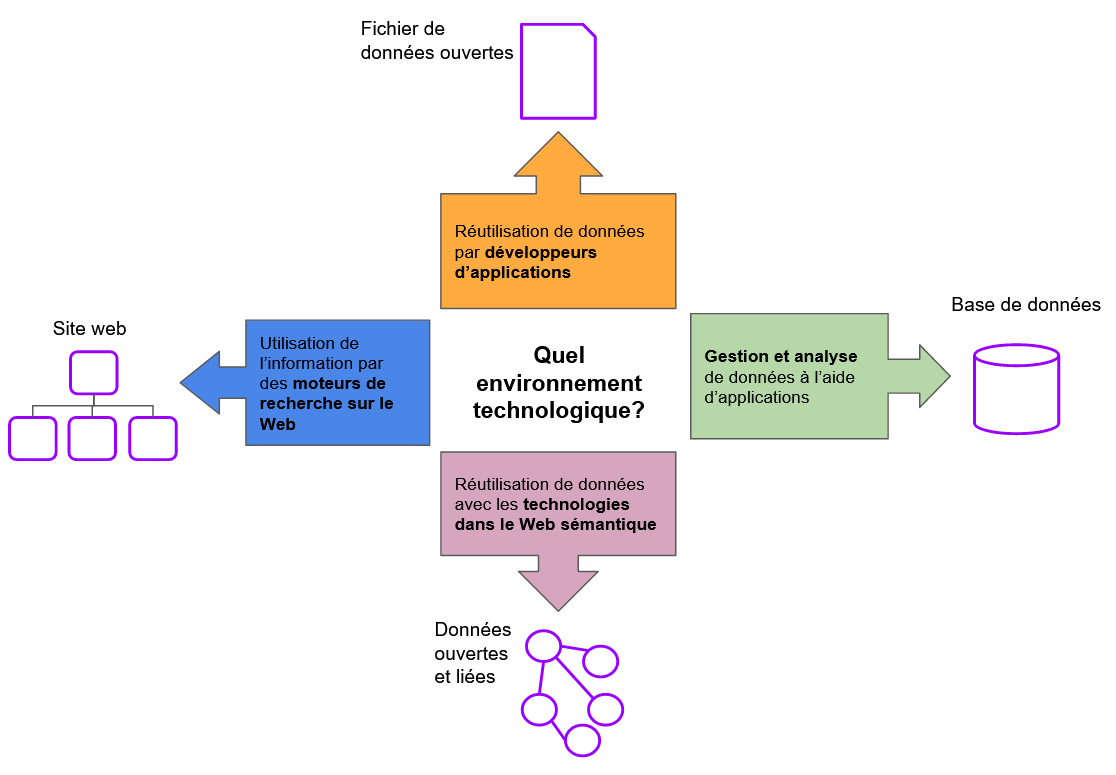
De façon générale, les initiatives visant à promouvoir une offre culturelle afin de favoriser sa « découvrabilité » concernent les moteurs de recherche comme Google ou des plateformes en ligne, existantes ou à concevoir. Ce sont cependant deux types de projets différents pour lesquels le type d’information à produire détermine des activités, compétences et ressources nécessaires différentes.
Google: rédiger et communiquer
Afin de fournir des réponses sous forme d’extraits, Google exploite le texte de pages HTML bien conçues et avec du bon contenu. Des données, même encodées sous forme de balises, n’ont pas les qualités d’interprétabilité et d’expressivité d’un texte. Ceci est d’autant plus important que, depuis plus d’une décennie, l’algorithme de Google est entré dans le domaine du langage humain. Alphabet, la compagnie propriétaire du moteur de recherche, expérimente Bard, une technologie similaire à ChatGPT.
Pour atteindre les objectifs d’une stratégie numérique, il y aurait donc intérêt à améliorer le contenu rédactionnel du site en tenant compte des intérêts des publics cibles et des principes d’optimisation. On ne répétera jamais assez que la connaissance du marché est la clé de la relation entre une offre culturelle et ses publics cibles.
Balises Schema.org et fonctionnalités de Google
Pour générer des aperçus détaillés liées à des offres culturelles, Google n’utilise que deux éléments du langage de balisage Schema.org: Book et Event.
La balise Book s’applique au livre, mais son usage est cependant limité aux fournisseurs proposant un large choix de livres. Cette préférence pour des intermédiaires commerciaux concerne aussi la deuxième balise, Event, qui décrit un événement. Il n’est généralement pas nécessaire de la produire car les données sont collectées auprès des billetteries et exploitées uniquement durant une courte période précédant la date du spectacle.
Un contenu rédactionnel riche et pérenne, sur un site bien conçu, est donc essentiel pour se démarquer et se positionner auprès de clientèles ciblées.
Plateformes: documenter et organiser
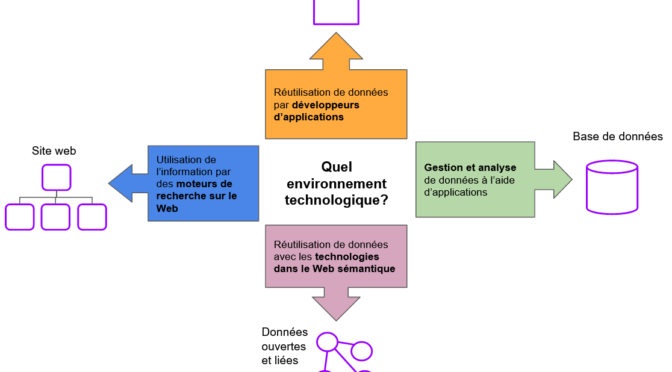
La production et l’utilisation de données et métadonnées convient à des projets qui ont pour objectif de faciliter la gestion et l’utilisation de l’information. En voici des exemples:
Ajouter des données dans Wikidata les rend découvrables et réutilisables sur cette plateforme. Celle-ci offre également la possibilité de partager et lier des données sans avoir à maîtriser l’architecture complexe du Web sémantique.
Des projets sont également réalisés en exploitant des données de Wikidata en complémentarité avec d’autres sources de données.
D’autres projets centrés sur les données concernent l’adoption d’un modèle de métadonnées pour des plateformes et des catalogues en ligne. Dans un domaine tel que la musique, par exemple, le référencement d’œuvres selon un modèle uniforme sert à harmoniser les données produites par différents acteurs de l’industrie utilisant les mêmes systèmes ou plateformes.
L’adoption de normes et de bonnes pratiques communes pour produire des données permet également d’optimiser des stratégies de promotion et de collecter de l’information plus précise sur la consommation.
On ne devrait cependant pas imposer un seul modèle de métadonnées pour tous les systèmes. Par exemple, une bibliothèque et une librairie ne décrivent pas un livre de la même façon en raison de leurs missions et activités spécifiques. De plus, un modèle est fait de choix et d’exclusions, ce qui soulève d’importants enjeux de diversité culturelle et de décolonisation.
Rédiger un texte ou produire des données?
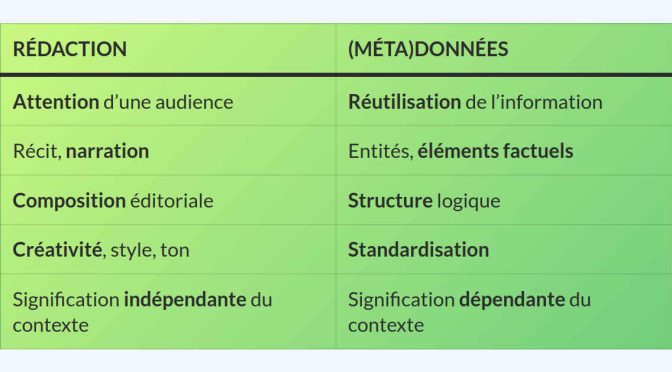
La rédaction et les données répondent à des usages et des objectifs spécifiques. Un texte descriptif permet de communiquer de l’information de façon expressive, alors que des données permettent d’organiser et de réutiliser de l’information. Ces deux types de production numérique ne doivent pas être confondus :
- Rédaction – Par exemple, votre projet repose sur la transmission d’information rédigée à l’intention de vos publics sur un site web, un réseau social, un média numérique ou Wikipédia (dans le respect de ses principes fondateurs).
- Données et métadonnées – Par exemple, votre projet repose sur l’organisation, le tri et la représentation de l’information dans un catalogue en ligne, une base de données classique, des graphes de données liées avec les technologies du Web sémantique ou un projet comme Wikidata.
| Rédaction | (Méta)données |
|---|---|
| Attention d’une audience | Réutilisation de l’information |
| Récit, narration | Entités, éléments factuels |
| Composition éditoriale | Structure logique |
| Créativité, style, ton | Standardisation |
| Signification indépendante du contexte | Signification dépendante du contexte |
Un texte à propos d’une création musicale a un plus grand potentiel d’attention et de séduction que des données brutes, surtout pour une personne ne connaissant ni l’œuvre ni ses interprètes. Par conséquent, sur une page web, il aura beaucoup plus de valeur pour l’algorithme de Google, qui pourra l’analyser, le contextualiser et en utiliser les extraits répondant aux questions des utilisateurs.
Comme on l’a vu plus précédemment, les données jouent un rôle central dans une plateforme d’écoute en continu car elles permettent d’en enrichir les fonctionnalités (recherche, tri, recommandation, etc.). Elles ne jouent cependant pas celui d’une campagne de promotion.
En conclusion
Le problème de la découvrabilité, c’est de mettre la solution avant le diagnostic et la stratégie. C’est peut-être aussi, comme le dit Jean-Robert Bisaillon, le résultat du « récupérationnisme politique ». L’emballement qui pousse les individus et organisations à produire des données dans le but d’influencer les moteurs de recherche tient en effet du solutionnisme et nuit au développement d’expertise.
Il faut apprendre à la fois à rédiger pour des publics cibles et à prendre soin des données, là où elles sont utiles. Toute initiative de promotion d’offres culturelles doit reposer sur une réflexion stratégique et une méthodologie de projet spécifique. Également, il ne peut y avoir de progrès sans un suivi constant des technologies numériques que l’on envisage de mettre en œuvre afin de promouvoir l’accès à la connaissance et à la culture. Pour cela, il est nécessaire que les programmes de soutien prévoient des budgets et échéanciers conséquents.











{kind=link}
{kind=link}