Le Guide des bonnes pratiques: découvrabilité et données en culture, récemment publié par le Ministère de la Culture et des Communications du Québec, est un bel effort de synthèse. Il faut cependant plus qu’un exercice de rédaction pour transmettre à des non-initiés des connaissances sur des systèmes dont le fonctionnement et les interdépendances sont complexes, changeants et trop souvent, incompris.
Wikipédia et Wikidata: des vases communicants?
Dans ce document, plusieurs affirmations concernant Wikipédia et Wikidata, ainsi que leur utilisation par les moteurs de recherche risquent cependant d’être incorrectement interprétées.
lI est aussi dans l’intérêt d’une ou d’un artiste, peu importe son domaine, de fournir les informations à Wikidata à propos, par exemple, de ses œuvres et de son parcours sous forme de données pour alimenter Wikipédia.
Cette injonction (page 15) est un raccourci qui donne à croire qu’il suffit de saisir ou verser des données dans Wikidata pour alimenter Wikipédia. Or, il serait plus exact de dire que pour chaque article créé dans Wikipédia, un élément Wikidata existe, mais l’inverse n’est pas possible (des éléments Wikidata n’ont pas d’articles correspondants dans Wikipédia). Par exemple, pour l’article sur le chorégraphe Jean-Pierre Perreault, on a l’élément Q3169633. Pour documenter davantage l’élément, dans Wikidata, des libellés ont été ajoutés (par exemple: nom, prénom, occupation, identifiant ISNI).
Le contenu, la donnée et les moteurs de recherche
Il est important de saisir la différence et les rôles spécifiques que peuvent jouer le contenu (article) et la donnée (élément) dans des projets visant à améliorer la repérabilité et la découverte.
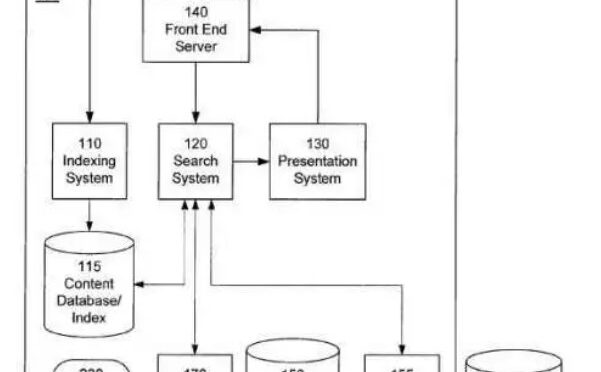
Les moteurs de recherche pourront par la suite les mettre en valeur lors de recherches d’internautes, notamment dans les cartes enrichies qui apparaissent souvent lorsqu’une recherche est réalisée sur Google.
Ici (page 15), encore, cette affirmation pourrait laisser croire que les moteurs de recherche puisent de l’information à même ces bases de connaissances. Ce raccourci ne tient pas compte du rôle central des sites web pour des moteurs de recherche dont le fonctionnement repose sur l’indexation de documents (pages web) et l’analyse du contenu (texte).
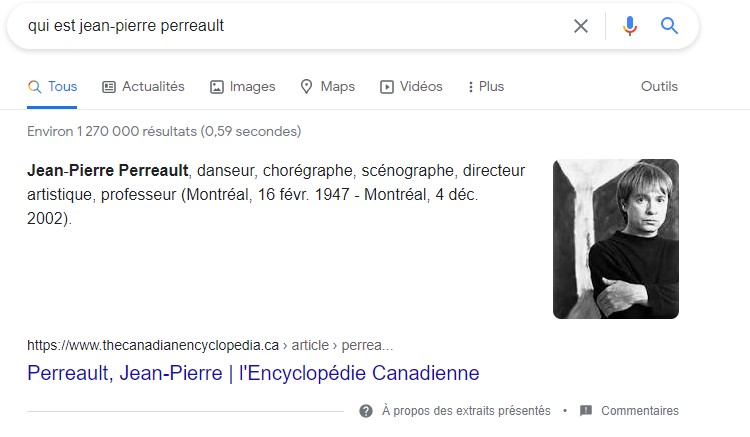
Par exemple, la recherche « Jean-Pierre Perreault » sur Google produit une fiche d’information qui résulte de la reconnaissance d’entités nommées dans des pages web. L’ambiguïté résultant d’une homonymie entre le chorégraphe et un professeur n’a pas été résolue pour la recherche d’images.
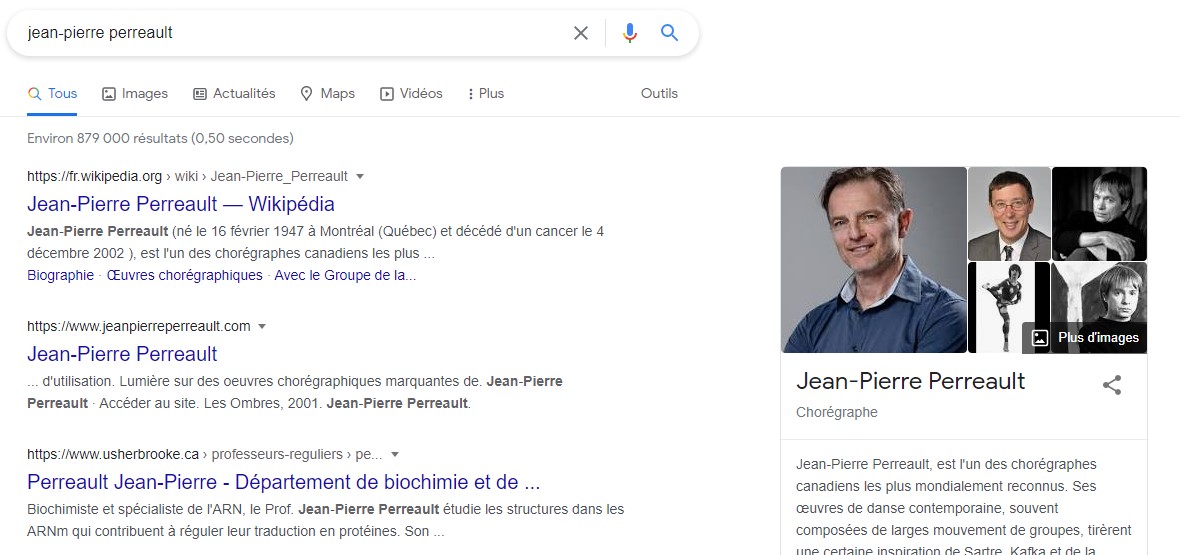
Par contre, la recherche « qui est Jean-Pierre Perreault » fait appel à l’analyse du texte contenu dans les pages web qui ont été indexées par le moteur de recherche. Le résultat est enrichi, c’est-à-dire qu’il s’agit d’une réponse fournie directement à partir d’un texte extrait d’un site web dont la structure et le contenu réunissent les conditions d’autorité, expertise et fiabilité.
Base de connaissances pour la reconnaissance d’entités
Voici un autre raccourci (page 16) qui peut laisser croire que verser des données dans Wikidata est une solution au manque de visibilité des contenus culturels québécois sur le Web. Ceci peut avoir pour conséquence l’appauvrissement graduel de la valeur informationnelle des sites web, alors qu’il faudrait plutôt guider et soutenir l’adoption de meilleures pratiques pour leur conception.
Comme il a été mentionné précédemment, en saisissant vos données dans Wikidata, vous vous assurez que les moteurs de recherche peuvent les trouver//
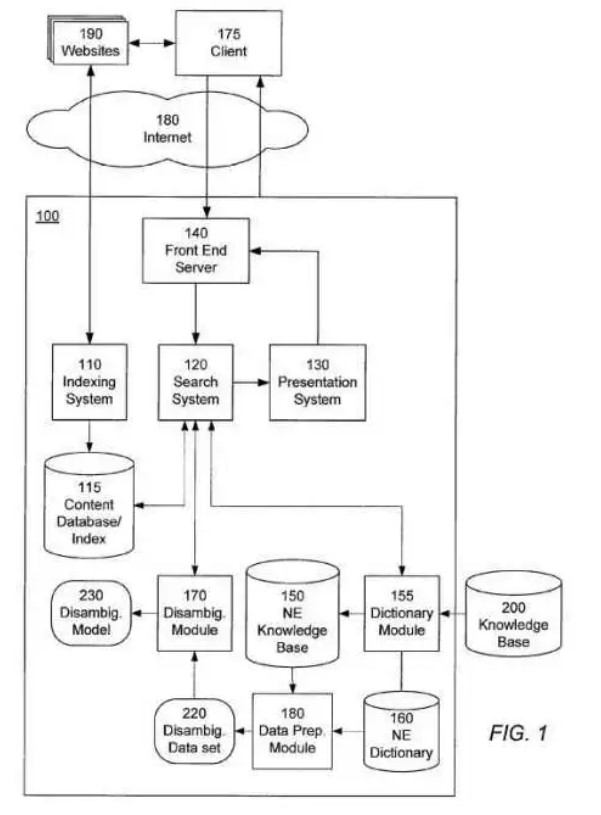
Pour un moteur comme Google, une base de connaissances externe comme Wikidata a pour fonction de faciliter la reconnaissance d’entités nommées (personnes, lieux, œuvres, événements, etc.) et d’aider le moteur de recherche à réduire toute ambiguïté. Le rôle d’une telle base de connaissances est illustré dans le schéma ci-dessous (numéro 200). Il s’agit d’une illustration fournie dans une demande de brevet déposée par Google en 2012. Ce document, ainsi que d’autres brevets, sont très bien commentés par l’expert Bill Slawski. La compagnie développait alors sa propre base d’entités nommées (numéro 150) qui, selon les observateurs, était probablement issue de Freebase dont l’acquisition a été complétée par Google en 2014.
Projets wiki: contribuer pour de bonnes raisons
Ces précisions n’ont pas pour objet de réduire l’enthousiasme des acteurs culturels et des autres citoyens pour les projets de la Fondation Wikimedia. Bien au contraire. Elles visent d’abord, à faire connaître un peu mieux ces systèmes auxquels sont souvent attribués des fonctionnements qui ne sont pas démontrés… mais porteurs de tant d’espérances. Leur objectif principal est d’encourager des usages et des initiatives moins orientés vers le marketing et la promotion, mais qui correspondent davantage à la mission et aux valeurs de Wikimedia et à un Web universel, libre de droit, ouvert et décentralisé.
Bravo Josée pour cet autre excellent billet!
Si tu me permets, j’aimerais me porter à la défense de certaines affirmations du Guide sur la découvrabilité.
Tout d’abord, s’il est vrai que chaque création d’article sur Wikipédia donne éventuellement lieu à la création d’un élément Wikidata, il est aussi vrai que les données de Wikidata peuvent « alimenter Wikipédia ». Il existe dans Wikipédia de nombreux « templates » qui permettent d’intégrer à des articles Wikipédia des informations provenant de Wikidata : des info-boîtes, des listes d’oeuvres, des notices d’autorité et des citations (Cite Q). En règle générale, la communauté de la version anglaise de Wikipedia est plutôt réticente à l’intégration de données provenant de Wikidata. Heureusement, la communauté de francophone de Wikipédia y est beaucoup plus réceptive!
« Les moteurs de recherche pourront par la suite les mettre en valeur lors de recherches d’internautes ». C’est aussi vrai, quoiqu’on ne peut établir de lien de cause à effet direct. Google affirme elle-même que son moteur de recherche indexe des base de données publiques (https://developers.google.com/search/docs/beginner/how-search-works) J’ai moi-même pu voir cela à l’oeuvre lorsque je créais de nouveaux éléments Wikidata : au fil de mes recherches pour trouver des références en appui à mes déclarations, Google me propose parfois un paneau de connaissances dérivé de mes déclarations Wikidata et m’invite à vérifer/m’approprier ce paneau (https://support.google.com/knowledgepanel/answer/7534902?hl=en). Cela démontre que Google surveille de près l’ajout de données dans Wikidata, mais qu’il n’y accorde pas automatiquement d’autorité. Il faut ajouter des références et/ou il faut s’approprier son paneau de connaissance (s’il s’agit effectivement d’une entité nommée sur laquelle on a autorité).
Enfin, Wikidata est une excellente base de connaissances pour la reconnaissance et la désambiguïsation des entités nommées. Grâce au nombreux liens externes qu’il est possible d’y saisir (VIAF, ISNI, des encyclopédies, des identifiants de médias sociaux, etc.), Wikidata peut agir d’identifiant passerelle et aider tant les humains que les machines à tisser des liens entre les traces qu’un artiste ou un organisme laisse sur le web.
Ceci dit, je suis cent pourcent d’accord avec ton propos à l’effet que Wikidata ne peut et ne doit pas se substituer à un site Web. Wikidata n’est pas une base de données primaire, mais plutôt une base de données secondaire qui tire notamment ses références de sites web. Il donc demeure impératif que les artistes et les organisme continue d’alimenter leur sites web en informations à propos de leur carrière et de leurs activités.
Frédéric
Bonjour Frédéric, je te remercie d’avoir partagé ton commentaire sur mon carnet. C’est plutôt rare, mais essentiel puisque la courte vie des publications sur les réseaux sociaux ne permet pas d’approfondir des discussions et d’en conserver les traces.
Les pages générées par des bases de données publiques, comme celles des collections de bibliothèques et de musées, constitue du contenu pour les moteurs de recherche.
Une personne qui fait l’objet d’une fiche d’information (modestement appelée knowledge panel, par Google) peut la revendiquer en prouvant qu’elle a un site web. Pour Google, il s’agit du « home of the entity ». Mais si celui-ci ne réunit pas les qualités de contenu recherchées, ce sont d’autres sites qui seront utilisés par l’IA pour fournir des réponses, comme démontré par l’exemple que j’ai fourni. J’attire ton attention, dans cet exemple, sur l’absence de la fiche d’information lorsque la question est précise. La fiche a pour objectif d’orienter l’utilisateur et d’interpréter son intention.
Je crois que nos divergences de vues –car il s’agit bien d’interprétations du fonctionnement d’applications et systèmes qu’il faut élaborer à partir des analyses provenant d’experts de différents domaines– reposent principalement sur les rôles que jouent les données et le contenu, tant pour les moteurs de recherche et que pour leurs utilisateurs.
Il est essentiel de réaliser que les données et le contenu sont fondamentalement différents dans leur création et dans leur consommation et usage. Le contenu est à propos d’un sujet ou d’une histoire alors que les données décrivent des entités (choses, personnes, concepts).
Des données peuvent fournir des réponses précises à des questions structurées (qui est l’auteur de Les Misérables, quelles sont les films de 2020) et sont essentielles pour opérer des catalogues en ligne. Mais des données peuvent-elles répondre de façon satisfaisante à l’intention d’un utilisateur? Google sait que nous préférons un mode narratif (ex: pourquoi 2001 odyssée de l’espace est un grand film? Comment devenir médiatrice culturelle?) et qui pourrait rapidement devenir interactif.
Des technologies avancées (MUM: Multitask Unified Model) permettent à Google de proposer une réponse qui est constituée à partir de plusieurs citations, extraites de pages web, en s’appyant sur des modèles de langage humain. C’est, entre autres, pour cette raison que je m’inquiète de la très faible qualité informative des sites web, du peu d’intérêt des bailleurs de fonds pour ce qui constitue la matière première des moteurs de recherche et de l’insuffisance du niveau de connaissances parmi les métiers du Web.
Au plaisir d’une conversation en personne. Ce serait vraiment utile et précieux, pour toute personne intéressée par ces questions, de pouvoir échanger et compléter ce casse-tête qu’est le Web des moteurs de recherche.
Josée