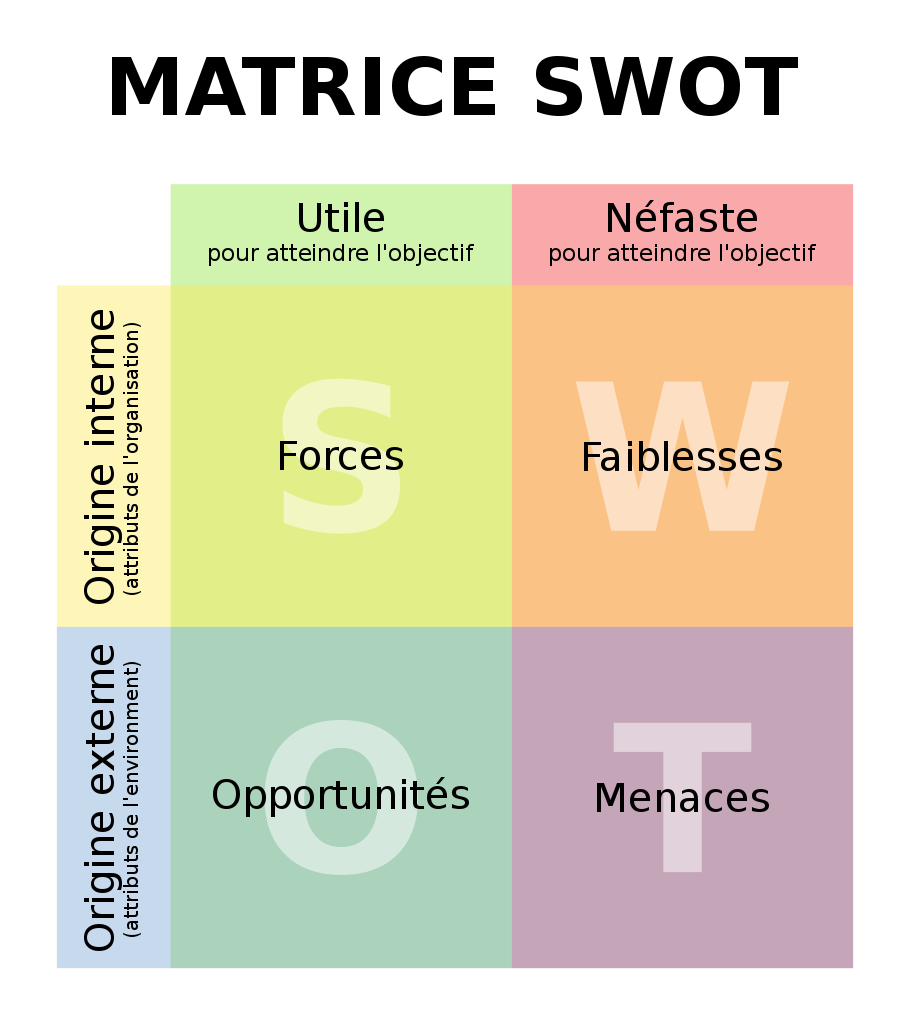
Matrice pour analyse des forces, faiblesses, opportunités et menaces d’un projet donné. Illustration: Xhienne, [CC BY-SA 2.5], Wikimedia Commons.Des données ou des algorithmes de recommandation peuvent-ils vraiment résoudre une problématique aussi complexe qu’une baisse de la consommation de contenus culturels? Bien sûr que non. La définition actuelle de la découvrabilité laisse pourtant entendre que la solution repose sur le contenu mis en ligne:
Potentiel pour un contenu, disponible en ligne, d’être aisément découvert par des internautes dans le cyberespace, notamment par ceux qui ne cherchaient pas précisément le contenu en question.
C’est une vision qui rend attrayante une solution aussi improbable que des métadonnées pour influencer Google. Mais surtout, une telle démarche élude l’étape la plus importante d’un projet qu’est la réflexion stratégique.
Comprendre une problématique multidimensionnelle
Une analyse stratégique permet pourtant d’identifier les facteurs internes (forces, faiblesses) et externes (opportunités, menaces) qui peuvent faciliter ou entraver la réalisation des objectifs souhaités. En voici des exemples:
Force (facteur interne): la connaissance de l’environnement technologique préconisé est suffisamment maîtrisée par la direction pour communiquer clairement sur les résultats tangibles attendus (ce que ça peut faire) et dissiper le fantasme du techno solutionnisme (ce que ça ne fait pas).
Menace (facteur externe): des pratiques industrielles et modèles d’affaires rendent des contenus indisponibles ou introuvables, comme l’affirme Philippe Falardeau dans cet article sur la possible fermeture d’un distributeur de films.
Rechercher des résultats concrets
Voici une définition plus précise de la découvrabilité et qui m’apparaît encourager une démarche stratégique:
La découvrabilité est le résultat potentiel de stratégies et moyens mis en œuvre, dans un environnement technologique donné, afin de favoriser des liens entre les intérêts de publics cibles et une offre qu’ils ne connaissent pas ou ne cherchent pas.
Elle comprend les éléments clés d’un questionnement préalable à la recherche d’une solution:
Le but: problème ou besoin concret (achat, visite, développement de compétences)?
Les publics cibles: quels sont-ils et quels sont leurs profils d’intérêts?
L’environnement technologique choisi: quelles sont les particularités de l’espace numérique choisi pour favoriser la découverte? Quelles sont les expertises requises?
***
Il serait essentiel de redéfinir la découvrabilité afin que chaque initiative numérique du domaine des arts et de la culture entreprenne une analyse stratégique. C’est en réalisant une telle démarche, en amont de la recherche d’une solution, que les organisations peuvent développer leur capacité d’adaptation et d’innovation.
Wikidata améliore-t-il la découvrabilité sur Google? Non.
Contrairement à une hypothèse que j’ai parfois évoquée il y a plusieurs années, puis maintes fois remise en cause, Wikidata n’est pas une solution de découvrabilité sur Google. C’est l’une des bases de connaissances permettant de valider une entité, et non de fournir une réponse. Ce n’est pas un moyen de promouvoir une information pour quiconque interroge Google, et encore moins pour qui ne la cherche pas.
Verser des données dans Wikidata ne rend donc pas un objet culturel plus visible ou découvrable parmi les résultats du moteur de recherche. Cependant, c’est une initiative à fort potentiel de créativité et de transformation numérique si l’on poursuit un tout autre but que la promotion d’une offre, soit la réutilisation de données interopérables et interconnectables, partout sur la planète.
Wikidata pour le Web des données
Par contre, comme je l’ai précisé dans un billet sur le choix d’un environnement technologique, contribuer à Wikidata peut favoriser la découverte de données sur cette plateforme. La maîtrise du langage d’interrogation SPARQL est cependant une courbe d’apprentissage plutôt abrupte pour les non-spécialistes. Même l’assistant de recherche est inaccessible pour qui n’a pas l’habitude de composer des requêtes destinées à des bases de données.
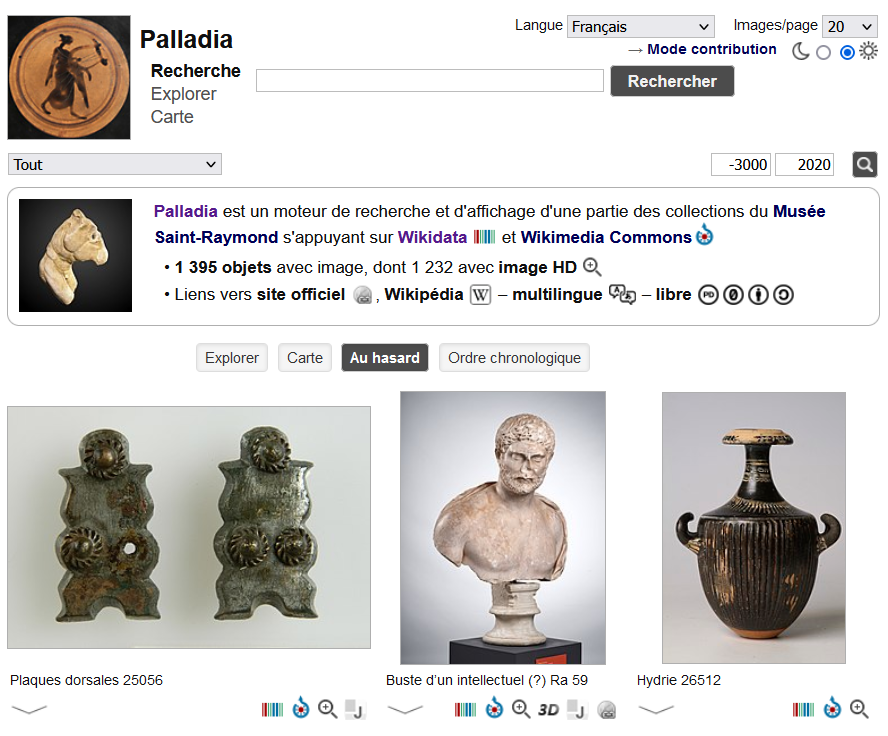
Les organisations versant leurs données dans Wikidata devraient offrir, sur leurs propres sites, des interfaces de recherche avec des requêtes pré-construites. L’exemple présenté ci-dessous est un projet réalisé par le Musée de Saint-Raymond à Toulouse (France) en partenariat avec Wikimedia France.
Palladia, moteur de recherche d’une partie des collections du Musée de Saint-Raymond (France) qui est présente sur Wikidata et Wikimedia Commons.
Cette réutilisation des données dans les deux sens — dans l’environnement ouvert et collaboratif de Wikidata et dans la perspective spécifique d’une institution — présente de précieux avantages:
Impulsion d’une véritable transformation
Un projet de données ouvertes et liées peut contribuer à la transformation d’une organisation dans un contexte numérique. Il ne s’agit pas d’informatisation, mais d’un projet fédérateur qui peut transformer les rapports à l’information et à la communication. Si c’est un choc culturel pour certaines institutions, c’est potentiellement un environnement d’apprentissage et, au final, une véritable transformation numérique pour toute forme d’organisation.
Modernisation d’un système de gestion documentaire
Des données liées offrent un énorme potentiel de découverte et de connaissance car elles ne sont pas figées dans un modèle où les relations sont prédéfinies. Ceci accorde à une base de données en graphe (appelée aussi graphe de données liées) la capacité d’effectuer du raisonnement, ce que la technologie des bases de données classiques n’offre pas.
Contournement des défis du Web sémantique
Wikidata réduit considérablement les coûts, délais et expertises requises pour la réalisation d’un projet de données ouvertes et liées en fournissant, entre autres, la plateforme et l’ontologie. Bien plus complexe qu’un vocabulaire, une ontologie est la spécification d’une conceptualisation, à l’aide de types d’objets, de leurs propriétés et de leurs différents types de relations. C’est un exercice d’abstraction réalisé par un petit nombre de spécialistes
Interopérabilité accrue des données
L’ontologie qui permet de modéliser les données pour Wikidata n’est pas conçue pour représenter le concepts propres à chaque domaine de connaissance. C’est un avantage: alors qu’une base de données classique est conçue pour répondre aux besoins et usages d’un domaine ou discipline, Wikidata ne cloisonne pas la connaissance et favorise, de ce fait, les interconnexions.
Petit rappel
Une base de données classique et un graphe de données liées ne sont pas exploitables pour les moteurs de recherche comme Google.
Deux grands défis d’un projet de données
Un projet de données liées comporte des défis qui doivent impérativement être identifiés et analysés en amont de toute conception ou acquisition de technologie. Voici deux de ces défis:
Expérience de recherche
Des données liées doivent permettre d’offrir des fonctions de recherche différentes de (et supérieures à) celles d’une base de données classique.
Une recherche par auteur, titre et sujet n’apportera pas de nouvelles connaissances. Les critères d’une recherche avancée ne sont pas de bons moyens pour faire découvrir une collection à qui ne cherche rien en particulier.
Mobilisation des utilisateurs(trices)
Changer le comportement de personnes qui accèdent à de l’information en posant simplement une question (Google, ChatGPT) ou de façon passive (flux des réseaux sociaux) est très certainement l’un des plus grands défis des nouvelles base de données en ligne.
Comment faire d’un site une destination préférée pour chercher ou découvrir de l’information? Hélas, nombreux sont les projets qui ne reposent que sur une campagne de promotion pour modifier des habitudes devenues des réflexes.
Wikidata: oui, mais pour des résultats concrets
Le versement de données dans Wikidata ne devrait pas être promu comme une bonne pratique de référencement web et de découvrabilité sur Google.
Cependant, un projet avec Wikidata peut faire converger deux buts: développer une culture de la donnée et amorcer une véritable transformation numérique impliquant de nouveaux modes d’organisation et de collaboration.
De façon générale, les initiatives visant à promouvoir une offre culturelle afin de favoriser sa « découvrabilité » concernent les moteurs de recherche comme Google ou des plateformes en ligne, existantes ou à concevoir. Ce sont cependant deux types de projets différents pour lesquels le type d’information à produire détermine des activités, compétences et ressources nécessaires différentes.
Google: rédiger et communiquer
Afin de fournir des réponses sous forme d’extraits, Google exploite le texte de pages HTML bien conçues et avec du bon contenu. Des données, même encodées sous forme de balises, n’ont pas les qualités d’interprétabilité et d’expressivité d’un texte. Ceci est d’autant plus important que, depuis plus d’une décennie, l’algorithme de Google est entré dans le domaine du langage humain. Alphabet, la compagnie propriétaire du moteur de recherche, expérimente Bard, une technologie similaire à ChatGPT.
Pour atteindre les objectifs d’une stratégie numérique, il y aurait donc intérêt à améliorer le contenu rédactionnel du site en tenant compte des intérêts des publics cibles et des principes d’optimisation. On ne répétera jamais assez que la connaissance du marché est la clé de la relation entre une offre culturelle et ses publics cibles.
Balises Schema.org et fonctionnalités de Google
Pour générer des aperçus détaillés liées à des offres culturelles, Google n’utilise que deux éléments du langage de balisage Schema.org: Book et Event.
La balise Book s’applique au livre, mais son usage est cependant limité aux fournisseurs proposant un large choix de livres. Cette préférence pour des intermédiaires commerciaux concerne aussi la deuxième balise, Event, qui décrit un événement. Il n’est généralement pas nécessaire de la produire car les données sont collectées auprès des billetteries et exploitées uniquement durant une courte période précédant la date du spectacle.
Un contenu rédactionnel riche et pérenne, sur un site bien conçu, est donc essentiel pour se démarquer et se positionner auprès de clientèles ciblées.
Plateformes: documenter et organiser
La production et l’utilisation de données et métadonnées convient à des projets qui ont pour objectif de faciliter la gestion et l’utilisation de l’information. En voici des exemples:
Ajouter des données dans Wikidata les rend découvrables et réutilisables sur cette plateforme. Celle-ci offre également la possibilité de partager et lier des données sans avoir à maîtriser l’architecture complexe du Web sémantique.
Des projets sont également réalisés en exploitant des données de Wikidata en complémentarité avec d’autres sources de données.
D’autres projets centrés sur les données concernent l’adoption d’un modèle de métadonnées pour des plateformes et des catalogues en ligne. Dans un domaine tel que la musique, par exemple, le référencement d’œuvres selon un modèle uniforme sert à harmoniser les données produites par différents acteurs de l’industrie utilisant les mêmes systèmes ou plateformes.
L’adoption de normes et de bonnes pratiques communes pour produire des données permet également d’optimiser des stratégies de promotion et de collecter de l’information plus précise sur la consommation.
On ne devrait cependant pas imposer un seul modèle de métadonnées pour tous les systèmes. Par exemple, une bibliothèque et une librairie ne décrivent pas un livre de la même façon en raison de leurs missions et activités spécifiques. De plus, un modèle est fait de choix et d’exclusions, ce qui soulève d’importants enjeux de diversité culturelle et de décolonisation.
Rédiger un texte ou produire des données?
La rédaction et les données répondent à des usages et des objectifs spécifiques. Un texte descriptif permet de communiquer de l’information de façon expressive, alors que des données permettent d’organiser et de réutiliser de l’information. Ces deux types de production numérique ne doivent pas être confondus :
Rédaction – Par exemple, votre projet repose sur la transmission d’information rédigée à l’intention de vos publics sur un site web, un réseau social, un média numérique ou Wikipédia (dans le respect de ses principes fondateurs).
Données et métadonnées – Par exemple, votre projet repose sur l’organisation, le tri et la représentation de l’information dans un catalogue en ligne, une base de données classique, des graphes de données liées avec les technologies du Web sémantique ou un projet comme Wikidata.
Rédaction
(Méta)données
Attention d’une audience
Réutilisation de l’information
Récit, narration
Entités, éléments factuels
Composition éditoriale
Structure logique
Créativité, style, ton
Standardisation
Signification indépendante du contexte
Signification dépendante du contexte
Tableau – Quel type de production choisir selon l’objectif ou l’usage
Un texte à propos d’une création musicale a un plus grand potentiel d’attention et de séduction que des données brutes, surtout pour une personne ne connaissant ni l’œuvre ni ses interprètes. Par conséquent, sur une page web, il aura beaucoup plus de valeur pour l’algorithme de Google, qui pourra l’analyser, le contextualiser et en utiliser les extraits répondant aux questions des utilisateurs.
Comme on l’a vu plus précédemment, les données jouent un rôle central dans une plateforme d’écoute en continu car elles permettent d’en enrichir les fonctionnalités (recherche, tri, recommandation, etc.). Elles ne jouent cependant pas celui d’une campagne de promotion.
En conclusion
Le problème de la découvrabilité, c’est de mettre la solution avant le diagnostic et la stratégie. C’est peut-être aussi, comme le dit Jean-Robert Bisaillon, le résultat du « récupérationnisme politique ». L’emballement qui pousse les individus et organisations à produire des données dans le but d’influencer les moteurs de recherche tient en effet du solutionnisme et nuit au développement d’expertise.
Il faut apprendre à la fois à rédiger pour des publics cibles et à prendre soin des données, là où elles sont utiles. Toute initiative de promotion d’offres culturelles doit reposer sur une réflexion stratégique et une méthodologie de projet spécifique. Également, il ne peut y avoir de progrès sans un suivi constant des technologies numériques que l’on envisage de mettre en œuvre afin de promouvoir l’accès à la connaissance et à la culture. Pour cela, il est nécessaire que les programmes de soutien prévoient des budgets et échéanciers conséquents.
Orienter toute initiative de découvrabilité vers la production de données relève de la pensée magique selon laquelle la technologie est la solution à toute problématique, aussi systémique et complexe soit-elle.
Dans le domaine culturel plus particulièrement, ce solutionnisme est porté par l’espoir d’accroître la visibilité des offres afin d’en encourager la consommation. Ceci a pour conséquence que nous avons des projets numériques sans planification stratégique et dont la méthodologie de réalisation n’est pas adaptée au domaine de l’information.
À ceci s’ajoutent les mécanismes de découvrabilité mentionnés dans de nombreux documents, conférences et vidéos, sans être clairement expliqués. De quels systèmes ou applications parle-t-on? Comment fonctionnent-ils? Quels résultats peut-on en attendre? Mystère…
La méthodologie, talon d’Achille de la découvrabilité
La « découvrabilité » n’est un pas un enjeu de données, mais de maturité des connaissances sur le Web et les différents systèmes qui s’y trouvent. Il y a très peu d’expertise réelle, tant au sein des équipes de projet qu’au sein des ministères et responsables de programmes, sur des sujets comme le fonctionnement de Google, les enjeux du choix d’une norme ou d’un modèle de données et les méthodologies de conception de structures d’information.
On n’a pas encore invité les spécialistes des diverses plateformes, technologies et sciences de l’information à constituer et actualiser une base de connaissances partagées sur ces questions. Par ailleurs, les enjeux de découvrabilité et les nouveaux milieux documentaires ne sont toujours pas des sujets d’intérêt pour le Congrès des professionnel.le.s de l’information.
En conséquence, la méthodologie est le talon d’Achille de la plupart des projets. Lorsque ceux-ci débutent avec des maquettes de pages web ou des interfaces de recherche, on s’interroge sur la prédominance de l’apparence visuelle sur la conception des structures d’information.
Sans une étape préalable d’analyse stratégique, la production de données comme solution-miracle de visibilité est un projet risqué. Celui-ci comporte de nombreux angles morts tels que les préférences et comportements des publics, les changements démographiques ou une vue d’ensemble des productions ou offres d‘un secteur donné. Surtout, l’absence d’objectifs concrets et mesurables comme l’augmentation de la vente de billets ou l’acquisition d’une nouvelle clientèle est un problème récurrent: comment être sûr d’améliorer ce qui n’a pas d’abord été mesuré?
Au final, tout miser sur la production de données ne compense pas l’obsolescence de modèles industriels et commerciaux pré-numériques, ni ne prend en compte la transformation des usages.
Halte au solutionnisme!
Bien identifier un problème ou définir un besoin est un projet en soi. Cette étape essentielle est pourtant souvent escamotée, faute de budget et d’échéancier adéquat. Il est alors difficile de cerner le périmètre du projet, en écartant des options non nécessaires tout en tenant compte des contraintes de l’organisation.
Avant de se lancer dans la production de données et métadonnées, il faut donc impérativement se questionner sur le but du projet afin de l’aiguiller vers l’environnement technologique approprié et, enfin, avoir une bonne visibilité sur le type de travail à réaliser dans cet environnement. Par exemple, la création d’une base de données, d‘éléments de Wikidata et d’un jeu de données ouvertes relèvent de technologies distinctes qui n’ont pas de langages et de structures communes. Ce sont donc des types de projet différents ne visant pas les mêmes objectifs et ne faisant pas appel aux mêmes expertises.
Et mes données, alors ?!?
Dans le prochain article, nous verrons où les données et métadonnées sont vraiment utiles et comment des contenus bien rédigés sont souvent plus efficaces en terme de découvrabilité.
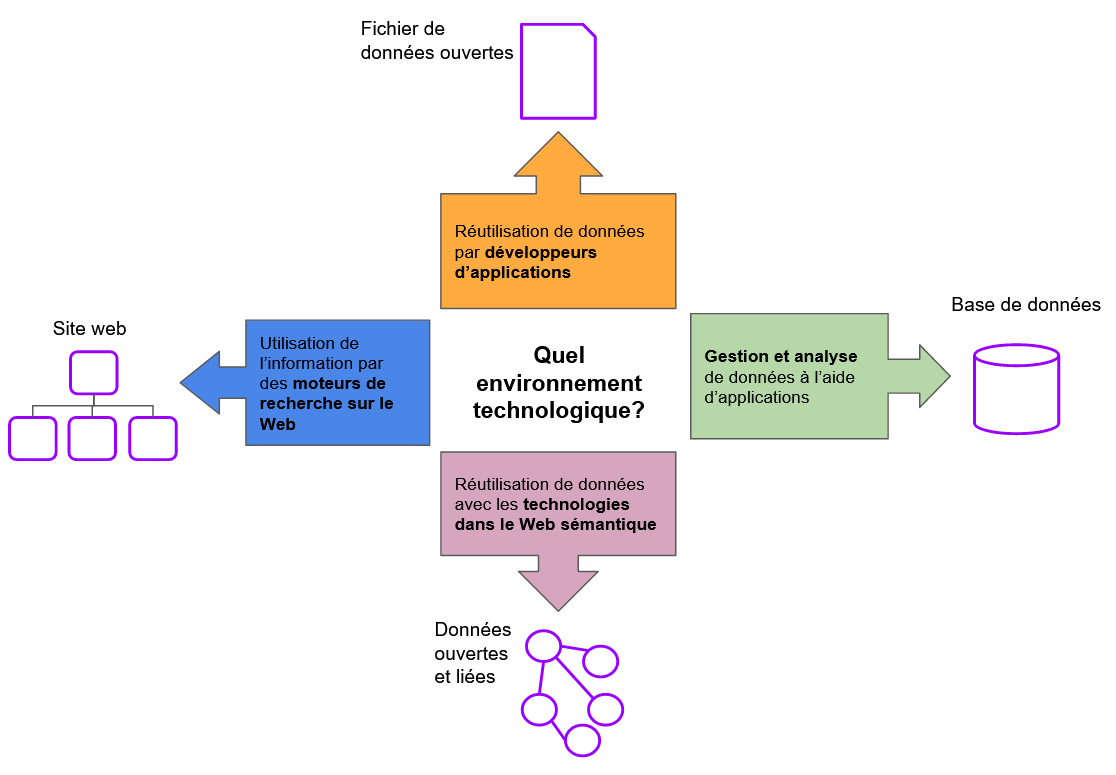
Découvrabilité: quel type de projet? Quatre environnements technologiques et types de projets numériques pertinents.
Favoriser la découverte d’une offre pour atteindre un objectif c’est bien, mais dans quel environnement technologique? La réponse à cette question, rarement abordée, pourrait pourtant aiguiller certains projets ciblant les moteurs de recherche vers de meilleures pratiques de conception et de rédaction pour le Web plutôt que vers la création de métadonnées.
Recherchée: méthodologie de projet
Parmi les écueils qui constituent des risques pour la réussite d’un projet, j’ai déjà élaboré sur le but et le solutionnisme technologique. Le but (résultat mesurable) est fréquemment confondu avec les moyens (découvrabilité). L’énonciation d’un but fait partie d’un exercice stratégique. Celui-ci est escamoté, de même que l’identification des besoins, lorsque des moyens technologiques semblent apporter une réponse simple à une situation pourtant complexe.
Ces écueils pourraient être évités en adoptant une démarche de réalisation de projet qui débute avec une réflexion stratégique. Ce sujet devrait figurer au premier plan des différents coffres à outils proposés, en culture comme dans tous les domaines.
Voici à présent, un troisième écueil qui peut apporter son lot de problèmes: la méconnaissance d’un univers où se croisent, sans nécessairement se connecter, divers domaines d’expertise.
Ce que nous désignons généralement comme « le numérique » rassemble des environnements technologiques qui ont des langages, structures, normes et, surtout, des objectifs et usages bien spécifiques. Voici les environnements que l’on peut retrouver dans des projets
Web (pages)
Celui des moteurs de recherche: c’est à dire les sites et plateformes développés avec les standards du Web et et dont le contenu est accessible et indexable. Seul le contenu de type HTML est exploité pour répondre aux demandes des utilisateurs. Dans cet objectif, des métadonnées comme des identifiants internationaux (par exemple: ISNI) ou locaux (par exemple: numéros uniques d’œuvres) présentent beaucoup moins d’intérêt, pour les algorithmes, qu’une bonne description à la Wikipédia. Ces métadonnées seront, par contre, très importantes dans des environnements centrés sur les données, comme les trois suivants.
Celui des jardins clos, au contenu non accessible aux moteurs de recherche, car il n’est volontairement pas ouvert et conforme aux standards du Web. On y trouve les plateformes accessibles aux détenteurs de compte (payants ou gratuit), comme les réseaux sociaux et les sites d’écoute musicale.
Web sémantique (données ouvertes et liées)
Il s’agit d’une extension du Web qui utilise des technologies, standards et infrastructures différentes de celles du Web auquel nos navigateurs nous permettent d’accéder. Ce type de contenu qui n’est pas du HTML ne peut être indexé, interprété et utilisé par les moteurs de recherche à titre de résultat.
Contribuer à Wikidata peut intéresser des initiatives de données ouvertes et liées qui ne souhaiteraient pas développer leurs propres infrastructure et modèle de représentation.
Base de données relationnelles
Même si celle-ci peut servir à alimenter des pages web, une base données n’est pas « dans le Web » et donc, inaccessible à des moteurs de recherche comme Google. Par contre, un bon modèle de données et des métadonnées appropriées à la mission et aux utilisateurs cibles participent à la conception d’interfaces de recherche et de découverte.
Données ouvertes
Libérer des données est, en soi, un projet comprenant plusieurs étapes importantes afin de rendre celles-ci disponibles sous forme de fichier(s). Ce type de démarche est réalisé en amont d’un projet de données ouvertes et liées. Si des métadonnées permettent de décrire un jeu de données, les données elles-mêmes ne font pas partie du contenu exploitable par les moteurs de recherche.
Quel est l’environnement concerné?
Il est important de bien cerner le problème, ou d’identifier et prioriser les besoins, avant de développer une stratégie et de se pencher sur les outils technologiques. Ceci réduira considérablement les risques et coûts associés à des choix qui ne pas alignés sur le résultat attendu, notamment en raison de l’incompatibilité de plateformes, langages, applications et usages.
Voici, des types de projets qui correspondent aux environnements technologiques présentés précédemment:
Site web
Promotion et visibilité de l’information par l’entremise de moteurs de recherche commerciaux.
Données ouvertes
Réutilisation de données pour la recherche ou le développement d’applications.
Données ouvertes et liées
Réutilisation de données avec les technologies du Web sémantique: bases de connaissances interconnectées, fonctions avancées d’analyse et de recherche.
Base de données relationnelle
Gestion et utilisation de données, comme celles d’un catalogue d’enregistrements musicaux, par exemple, par des applications.
Il est possible que plus d’un environnement technologique soit concerné par un projet. Dans ce cas, il est impératif de rechercher des expertises, planifier des budgets et gérer des projets qui seront spécifiques à chacun des environnements.
* * *
Il est plus que temps d’améliorer la littératie numérique de tous les acteurs participant à des projets. Et plus précisément, connaître les particularités des différents environnements technologiques. C’est une mise à niveau qui devrait logiquement concerner les bailleurs de fonds, les prestataires de services de conception et les spécialistes des sciences de l’information. Dans ce contexte, on devrait se demander s’il est souhaitable que les acteurs du domaine culturel soient les seuls à faire des apprentissages essentiels à la transformation numérique de tout l’écosystème.
Le Guide des bonnes pratiques: découvrabilité et données en culture, récemment publié par le Ministère de la Culture et des Communications du Québec, est un bel effort de synthèse. Il faut cependant plus qu’un exercice de rédaction pour transmettre à des non-initiés des connaissances sur des systèmes dont le fonctionnement et les interdépendances sont complexes, changeants et trop souvent, incompris.
Wikipédia et Wikidata: des vases communicants?
Dans ce document, plusieurs affirmations concernant Wikipédia et Wikidata, ainsi que leur utilisation par les moteurs de recherche risquent cependant d’être incorrectement interprétées.
lI est aussi dans l’intérêt d’une ou d’un artiste, peu importe son domaine, de fournir les informations à Wikidata à propos, par exemple, de ses œuvres et de son parcours sous forme de données pour alimenter Wikipédia.
Cette injonction (page 15) est un raccourci qui donne à croire qu’il suffit de saisir ou verser des données dans Wikidata pour alimenter Wikipédia. Or, il serait plus exact de dire que pour chaque article créé dans Wikipédia, un élément Wikidata existe, mais l’inverse n’est pas possible (des éléments Wikidata n’ont pas d’articles correspondants dans Wikipédia). Par exemple, pour l’article sur le chorégraphe Jean-Pierre Perreault, on a l’élément Q3169633. Pour documenter davantage l’élément, dans Wikidata, des libellés ont été ajoutés (par exemple: nom, prénom, occupation, identifiant ISNI).
Le contenu, la donnée et les moteurs de recherche
Il est important de saisir la différence et les rôles spécifiques que peuvent jouer le contenu (article) et la donnée (élément) dans des projets visant à améliorer la repérabilité et la découverte.
Les moteurs de recherche pourront par la suite les mettre en valeur lors de recherches d’internautes, notamment dans les cartes enrichies qui apparaissent souvent lorsqu’une recherche est réalisée sur Google.
Ici (page 15), encore, cette affirmation pourrait laisser croire que les moteurs de recherche puisent de l’information à même ces bases de connaissances. Ce raccourci ne tient pas compte du rôle central des sites web pour des moteurs de recherche dont le fonctionnement repose sur l’indexation de documents (pages web) et l’analyse du contenu (texte).
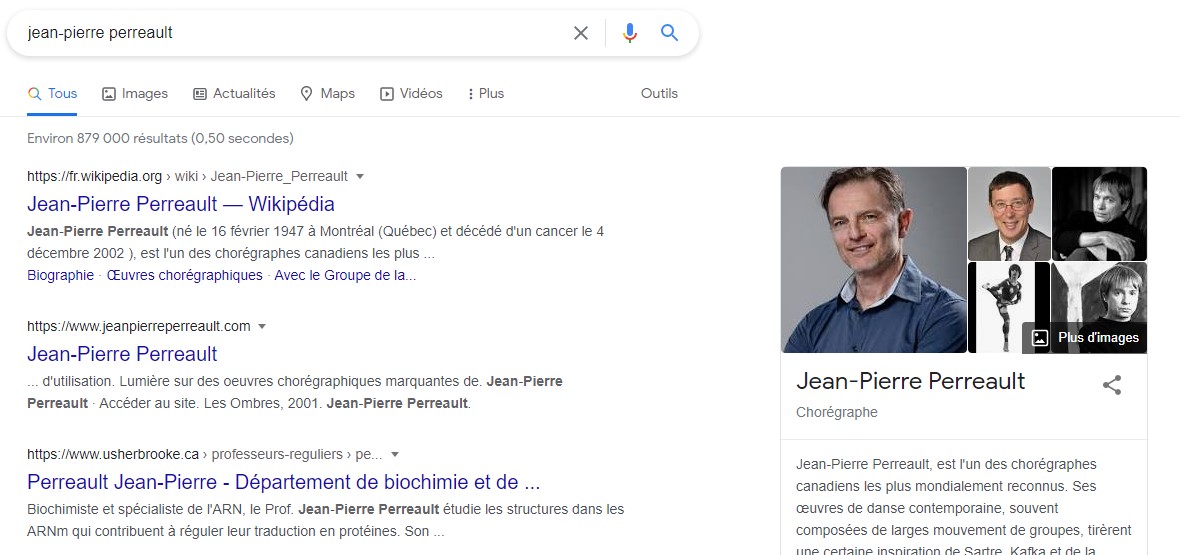
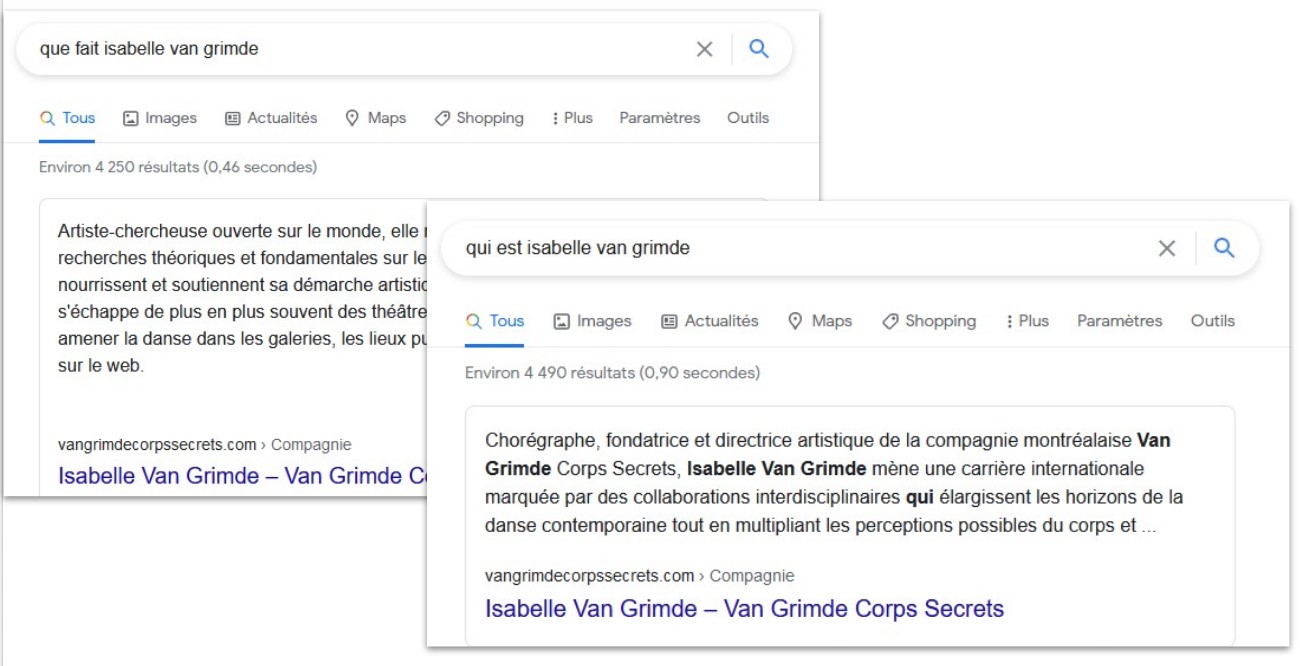
Par exemple, la recherche « Jean-Pierre Perreault » sur Google produit une fiche d’information qui résulte de la reconnaissance d’entités nommées dans des pages web. L’ambiguïté résultant d’une homonymie entre le chorégraphe et un professeur n’a pas été résolue pour la recherche d’images.
Résultat d’une recherche sur « Jean-Pierre Perreault », avec Google.
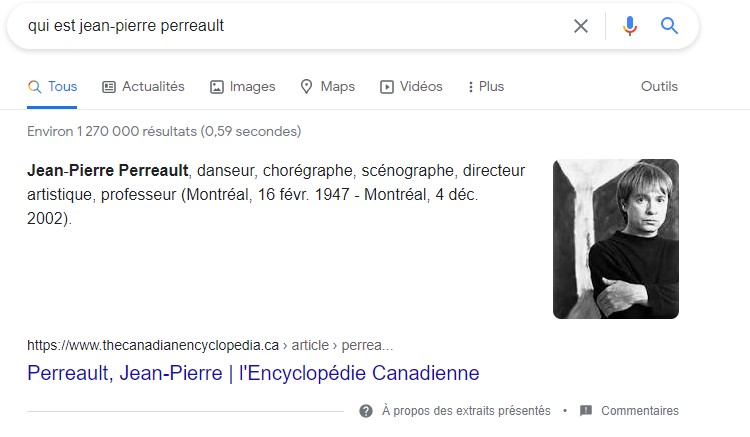
Par contre, la recherche « qui est Jean-Pierre Perreault » fait appel à l’analyse du texte contenu dans les pages web qui ont été indexées par le moteur de recherche. Le résultat est enrichi, c’est-à-dire qu’il s’agit d’une réponse fournie directement à partir d’un texte extrait d’un site web dont la structure et le contenu réunissent les conditions d’autorité, expertise et fiabilité.
Résultat de la recherche « qui est Jean-Pierre Perreault », sur Google.
Base de connaissances pour la reconnaissance d’entités
Voici un autre raccourci (page 16) qui peut laisser croire que verser des données dans Wikidata est une solution au manque de visibilité des contenus culturels québécois sur le Web. Ceci peut avoir pour conséquence l’appauvrissement graduel de la valeur informationnelle des sites web, alors qu’il faudrait plutôt guider et soutenir l’adoption de meilleures pratiques pour leur conception.
Comme il a été mentionné précédemment, en saisissant vos données dans Wikidata, vous vous assurez que les moteurs de recherche peuvent les trouver//
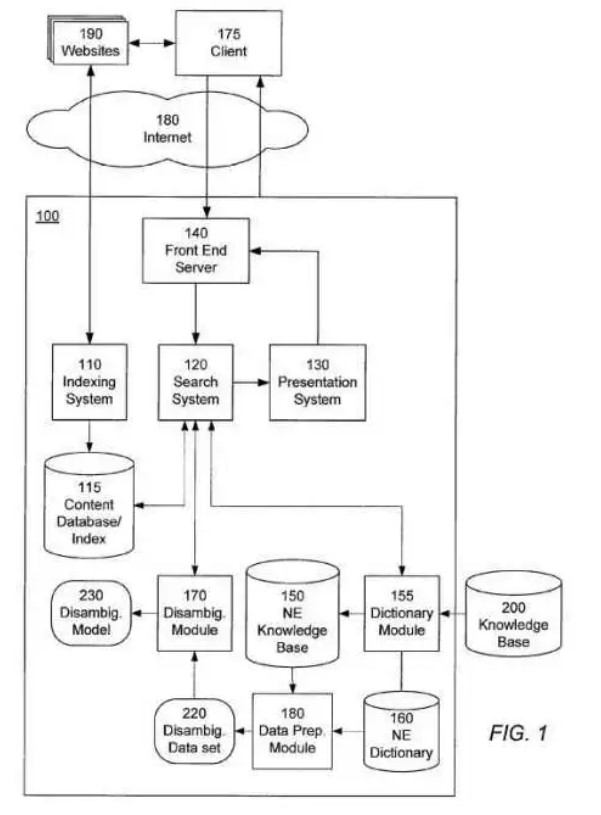
Pour un moteur comme Google, une base de connaissances externe comme Wikidata a pour fonction de faciliter la reconnaissance d’entités nommées (personnes, lieux, œuvres, événements, etc.) et d’aider le moteur de recherche à réduire toute ambiguïté. Le rôle d’une telle base de connaissances est illustré dans le schéma ci-dessous (numéro 200). Il s’agit d’une illustration fournie dans une demande de brevet déposée par Google en 2012. Ce document, ainsi que d’autres brevets, sont très bien commentés par l’expert Bill Slawski. La compagnie développait alors sa propre base d’entités nommées (numéro 150) qui, selon les observateurs, était probablement issue de Freebase dont l’acquisition a été complétée par Google en 2014.
Utilisation de bases de connaissances par Google pour réduire l’ambiguïté entre entités nommées. Illustration tirée d’une demande de brevet déposée par Google, en 2012. Explications et commentaires dans ce billet de l’expert Bill Slawski.
Projets wiki: contribuer pour de bonnes raisons
Ces précisions n’ont pas pour objet de réduire l’enthousiasme des acteurs culturels et des autres citoyens pour les projets de la Fondation Wikimedia. Bien au contraire. Elles visent d’abord, à faire connaître un peu mieux ces systèmes auxquels sont souvent attribués des fonctionnements qui ne sont pas démontrés… mais porteurs de tant d’espérances. Leur objectif principal est d’encourager des usages et des initiatives moins orientés vers le marketing et la promotion, mais qui correspondent davantage à la mission et aux valeurs de Wikimedia et à un Web universel, libre de droit, ouvert et décentralisé.
Variabilité des textes extraits du site web en fonction de l’interprétation de l’intention de la recherche.
Je le répète: il faut retomber en amour avec nos sites web. Nous devons réinvestir le domaine du langage sur ces espaces numériques privilégiés que sont nos sites web.
L’hypertexte en réseau
Le World Wide Web dont c’est aujourd’hui l’anniversaire, est cette application de l’Internet qui permet de relier des éléments d’information pour former un hypertexte. Nos site web sont des espaces numériques privilégiés parce des standards universels et libres nous offrent la possibilité de publier et partager des contenus, indépendamment des règles des plateformes commerciales et sociales. Sur nos sites web, nous détenons un contrôle stratégique: décider de la façon de documenter une chose et faire des liens qui la place dans un écosystème de connaissances.
De quelles machines est-il question ici? Il s’agit des moteurs de recherche qui indexent les pages web, ce qui exclut les plateformes pour lesquelles il faut ouvrir une session (Spotify, Netflix, les réseaux sociaux). À celles-ci, on peut ajouter le Web sémantique qui est une extension du Web permettant de relier des données. Ce sont des espaces numériques différents et qui font appel à des structures, règles et technologies spécifiques. Le Web des moteurs de recherche est celui des contenus accessibles, repérables et interopérables.
Wikidata permet de valider l’identification d’entités spécifiques et de fournir de l’information factuelle, comme une date de naissance. Cependant, c’est le contenu d’un site web qui contient le texte de la réponse à une question. Les moteurs de recherche analysent et évaluent, à présent, le texte des pages web afin d’en interpréter le sens avec certitude.
Rédiger pour des moteurs plus intelligents
L’information collectée sur les sites est mise en relation avec un système d’organisation de la connaissance qui permet de mieux interpréter une chose et d’enrichir la « compréhension » qu’a une machine de cette chose:
Interprétation: de quoi est-il question?
Classification: de quel type de chose s’agit-il?
Contexte: à quels autres types de choses/personnes est-ce relié?
Il faut lire l’article ci-dessous pour constater la rapidité du développement des systèmes d’analyse du langage (ce à quoi servent les graphes de connaissance). Cette évolution est en marche, que ce soit chez Google ou tout autre entreprise tirant profit de l’extraction de l’information.
It is clear that Google is moving rapidly toward a quasi-human understanding of the world and all its algorithms will increasingly rely on its understanding of entities and its confidence in its understanding.
Nous devons prioriser l’amélioration de nos sites web afin de nous rendre plus intelligibles, comme personne physique ou morale. Ceci permet de résister à une centralisation de l’information qui aplanit la diversité des expressions et des perspectives et de relier les acteurs de nos écosystèmes sans l’intervention d’algorithmes.
***
Alors, quelle serait la valeur informationnelle de votre site selon votre moteur de recherche favori?
Diversité des disciplines et thèmes abordés par la science de l’information. Zythème, [CC BY-SA 3.0], Wikimedia CommonsEn culture comme en commerce, les initiatives de mise en commun de données numériques, constituent de nouveaux « milieux documentaires ». Au Québec, pourtant, les compétences et méthodes du domaine des sciences de l’information sont rarement sollicitées. Les institutions d’enseignement et les associations professionnelles concernées devraient pourtant reconnaître, dans ces projets, les notions et enjeux entourant les systèmes documentaires classiques.
Voici quelques lectures récentes illustrant des défis que pourraient relever les spécialistes intéressés par ces nouveaux milieux documentaires.
Cet article introduit certains défis actuels de l’élaboration d’un modèle de métadonnées qui permette de faire des liens entre les ressources de bases de données différentes.
Tout choix est subjectif; il n’y a donc pas de donnée neutre. Un modèle de classement ou de catégorisation peut être porteur d’exclusion, notamment de ce qui peut apparaître inclassable (personne non genrée, pratiques artistiques hybrides…) car il impose le choix d’un descriptif parmi un nombre limité d’options.
Que faire des œuvres qui n’ont pas été pensées et créées dans le cadre d’une pratique déjà bien étiquetée? Et surtout, comment documenter l’intention?
Ça devient un problème à partir du moment où des livres ne reçoivent pas la reconnaissance qu’ils devraient avoir parce qu’on les juge à partir de critères qui n’ont rien à voir avec leur projet littéraire. Clara Dupuis-Morency, autrice et enseignante en littérature.
Comment, alors, respecter la création, anticiper les biais et éviter que la perspective d’une culture dominante n’occulte celles d’autres cultures?
Un catalogage qui se satisferait de distinguer les textes de fiction des textes entretenant un rapport plus immédiat au réel serait donc inefficace. ibid.
Ce billet publié par l’équipe des produits numériques du New York Times met en lumière le travail d’indexation et de catalogage requis par le développement d’un algorithme de recommandation. Il souligne l’importance d’intégrer la pensée humaine aux processus automatisés de traitement documentaire.
Le nettoyage des données et l’amélioration de la qualité descriptive des métadonnées sont des opérations essentielles à l’exploitation d’une base de données. Elles le sont également dans le cas d’un programme d’apprentissage automatique ayant pour objectif l’entraînement ou le bon fonctionnement d’un algorithme de recommandation.
When we took a deeper look at a few of the incorrect labels, we could often understand why the model assigned the label, but saw that correcting the mistake requires human judgement. It takes knowledge of history and society, as well as the ability to recognize context to intuit that some articles are better suited for some interest categories than others. The NYT Open Team
(…)
Readers trust The Times to curate content that is relevant to them, and we take this trust seriously. This algorithm, like many other AI-based decision-making systems, should not make the final call without human oversight. ibid.
À lire avant de convertir une taxonomie (ou tout autre vocabulaire contrôlé) en ontologie. Il s’agit bien de référentiels ayant des rôles différents et la problématique réside principalement dans les caractéristiques spécifiques de ces différents modes d’organisation des connaissances. Par exemple: l’adaptation de la structure hiérarchique d’une taxonomie à la structure en graphe d’une ontologie de domaine.
The problem is that the definitions and rules for hierarchies vary depending on the kind of knowledge organization system, so you cannot assume that a hierarchy in one system converts to a hierarchy in another system.
(…)
“Hierarchy” can have various types and uses. Not all kinds of hierarchies are reflected in even in taxonomies, which tend to be quite flexible. The rules are stricter when it comes to thesauri. Finally, in ontologies, there is only one kind of hierarchy. Heather Hedden, taxonomiste, ontologiste, autrice et formatrice.
Le concept de « graphe de connaissance » (knowledge graph), a été popularisé par Google, bien que des structures de données en graphes existaient auparavant dans différents domaines. Ce type de structure est souvent perçu comme une solution qui permette d’imposer un modèle descriptif assurant la visibilité et/ou l’interopérabilité de ressources informationnelles.
L’adoption d’un modèle descriptif unique entraîne cependant une uniformisation des perspectives qui conduit à l’aplatissement des connaissances. C’est également la source de problèmes rarement anticipés. Par exemple: l’adoption d’un vocabulaire commun dans toute l’organisation va-t-elle «pérenniser» vos données ou entraîner des réunions sans fin pour débattre de ses mises à jour des vocabulaires et des ontologies sont discutées?
If we instead listen to the problems information workers have, spend a day shadowing them in their jobs, and design solutions that integrate knowledge-tech in a lightweight way to automate tedium, then we have a shot at solving a larger set of problems, to benefit more of society. Mike Tung, CEO Diffbot.
Au-delà du solutionnisme technologique, il faut explorer les bénéfices issus du développement d’une véritable culture de l’information au sein des organisations. Cela signifie que la gestion et la qualité de l’information sont des responsabilités devant être partagées dans une organisation et non plus limitées au service des technologies de l’information.
Découvrabilité hors du Web des moteurs de recherche
OCLC, un organisme sans but lucratif au service des bibliothèques, rend compte d’un projet pilote sur la transformation des métadonnées de collections en données liées. Il nous rappelle que la découvrabilité recherchée n’est pas celle qui se mesure à l’aulne des résultats de Google ou des cotes de popularité des plateformes de contenus.
Les bases de données en graphe – il faut le répéter – ne sont pas indexées par les moteurs de recherche. Il existe d’autres espaces numériques où l’accès à la culture pourrait fournir des expériences de recherche et découverte pertinentes et efficaces. Exemple: naviguer à travers des collections qui proposent des connexions que des bases de données classiques n’arrivent pas à révéler.
Representing what is locally unique yet making local information legible to outsiders and creating a mechanism where differences can be understood, bridged, and linked is an important part of what public libraries using newer descriptive systems can surface.
À l’image des initiatives de la BnF et d’Europeana, le projet d’OCLC a permis à des institutions de se familiariser avec des méthodes et outils du web sémantique :
The Linked Data project demonstrated the amount of work involved in the transition to linked data, but also that the tools exist and that the workflows can be developed.
Pour une vision systémique du numérique
Les initiatives et projets qui visent à structurer l’information pour le numérique constituent de nouveaux milieux documentaires, hors des lieux habituels que sont les bibliothèques, centres de documentation et fonds d’archives. Les professionnels des sciences de l’information sont formés pour relever les défis inhérents aux « espaces» numériques que sont les sites web, les plateformes commerciales, le Web des données et, même, les jeux de données ouvertes. Il serait temps que la rencontre entre tous ces acteurs se réalise. La réussite de nos initiatives en dépend.
Planche de l’Encyclopédie de Diderot et d’Alembert: taille de la plume pour l’écriture. Morburre, [CC BY-SA 3.0], Wikimedia CommonsL’angle mort de la promotion de l’offre culturelle dans un monde numérique est la faible valeur informative de nos sites web. Quand une œuvre est mieux documentée dans une brochure que sur le site de son auteur, il est clair que les sciences du langage et de l’information n’ont pas été prises en compte dans sa conception.
Or, ce ne sont plus les balises Schema.org insérées dans le code ni les articles de Wikipédia qui facilitent le travail des moteurs de recherche en les rendant intelligents. C’est, à présent, le traitement automatique du langage naturel. Celui-ci permet aux algorithmes d’évaluer l’information présente sur une page web et lisible par les humains.
Plus l’information offerte par le texte est riche et contextualisée par des liens vers d’autres pages web, plus elle a de valeur pour nous et, par conséquent, pour les moteurs de recherche dont l’objectif est de nous offrir les meilleurs résultats possibles.
Un travail de spécialistes
Après quelques années d’accompagnement d’entrepreneurs culturels, je peux affirmer que rares sont les non-initiés sachant manier avec aisance des notions et des mécanismes qui demeurent complexes, même pour des spécialistes du Web. Ce billet sur les définitions divergentes de ce qu’est une ontologie permet de mesurer le défi d’établir une compréhension commune et claire d’une notion pourtant fondamentale des systèmes documentaires. Et pour celles et ceux qui persévèrent, les concepts et pratiques nouvellement acquis sont trop éloignés de leurs activités pour qu’ils soient en mesure de les intégrer aux opérations et de se livrer à la veille technique qui s’impose en permanence.
Structurer de l’information pour une variété d’usages et de systèmes, c’est un travail de spécialistes. Le rôle de créateurs de contenu consiste à documenter cette information et à raconter comment elle s’insère dans notre monde. Ils peuvent se faire aider afin de produire l’information répondant le mieux aux intérêts des publics cibles et de fournir des liens nécessaires aux humains et aux machines pour apporter du contexte, favorisant ainsi la découverte.
Voici les étapes qu’il faudrait suivre afin d’améliorer la valeur informative de la page web consacrée à une offre culturelle:
1- Stratégie: quelle information, à quels publics, pour quels résultats
Mieux un contenu est documenté, plus il est susceptible de pouvoir réponse à une question. Il est donc important de baser la conception du contenu d’une page sur une solide connaissance des publics cibles. D’où la nécessité d’une stratégie et d’une concertation entre les producteurs, diffuseurs et toutes autres parties concernées. Toutefois, l’élaboration d’une stratégie de ce type requiert une formation préalable mobilisant divers spécialistes.
2- Documentation: les choses et les relations entre ces choses
L’adaptation de nos contenus culturels à l’environnement numérique commence par l’écriture. Tous les éditeurs de sites web doivent à présent mieux organiser et documenter leurs contenus pour les rendre plus repérables. Pour Google, « documenter » signifie: bien décrire un contenu et fournir du contexte en faisant des liens entre des concepts. Plus la documentation est exhaustive et clairement libellée, plus elle a de la valeur pour les utilisateurs — et plus la page web de l’offre culturelle devient une source d’information de qualité.
3- Balises: signaler certains types de contenus
Certains types de contenus — comme les vidéos, par exemple — peuvent apparaître sous forme d’extraits, dans la liste de résultats de Google (résultats enrichis). L’utilisation de balises permettant de catégoriser des contenus n’est donc pertinente que pour un petit nombre d’offres. Les modèles descriptifs recommandés sont ceux qui concernent les projets de développement des services du moteur de recherche. De plus, les consignes à suivre évoluent en fonction du résultat des expérimentations et de l’avancement du traitement automatique du langage.
Nous devons, alors, éviter de développer des fonctionnalités qui deviennent rapidement obsolètes ou, pire, qui réduisent notre capacité d’innovation en l’encadrant dans la logique d’affaires d’une plateforme. Il faut donc que nous demeurions extrêmement vigilants afin que nos projets nous apportent une réelle valeur et ne tombent pas dans le solutionnisme technologique.
4- Wikipédia: création d’article utile, mais non essentielle
Wikipédia facilite l’identification d’un concept ou objet spécifique, mais ce sont les pages web qui sont les sources primaires pour Google. Contrairement à la croyance courante, la production d’une fiche de réponse (appelée « knowledge panel ») résulte du traitement du contenu provenant de différentes pages web. Celles-ci sont qualifiées par le moteur de recherche pour l’information qu’elles offrent. En analysant certains brevets déposés par Google, on peut déduire que son utilisation de l’encyclopédie n’est ni constante, ni déterminante. Créer un article Wikipédia n’est donc pas une activité essentielle dans un plan de découvrabilité, même si cela peut accroître la notoriété d’un sujet lorsqu’il contient des connaissances utiles et des liens vers d’autres articles.
L’écriture: une « solution » à la portée de tous!
Adapter nos contenus culturels à l’environnement numérique commence donc par une technique millénaire: l’écriture. Nous pourrions beaucoup mieux documenter nos offres culturelles sur nos sites web sans nécessairement plonger dans des domaines de connaissance complexes. Il suffit d’apprendre à décrire des choses et les relations entre ces choses pour des systèmes qui, eux-même, apprennent à lire afin de fournir la meilleure information à leurs utilisateurs. Bref, avant de se lancer dans la modélisation de données ou le web sémantique, il serait temps de revenir aux stratégies de communication, ainsi qu’aux bonnes pratiques de rédaction web.
Cependant, dans le schéma des 12 leviers à activer pour une meilleure découvrabilité des contenus culturels francophones (voir plus haut), il manque à mon avis deux éléments essentiels:
Est-ce aux acteurs culturels que revient la charge de rendre l’information concernant leurs créations ou leurs offres numériquement opérationnelle?
Quel espace numérique offre les meilleures conditions de repérabilité, d’accessibilité et d’interopérabilité de l’information ?
Premier levier: mises à niveau des métiers du Web
Il est important de sensibiliser les acteurs culturels à l’adoption de pratiques documentaires telles que l’indexation de ressources en ligne. Ceci dit, la mise en application des principes, ainsi que le choix de modèles de représentation de contenus en ligne, sont des compétences qui ne s’acquièrent pas comme on apprend à se servir d’un logiciel. On ne peut pas attendre de toute personne et organisation du secteur culturel de tels efforts d’apprentissage. D’autant plus que la production de l’information pour le numérique fait appel à des méthodes et savoirs relevant des domaines du langage et de la représentation des connaissances autant que des technologies numériques.
Si les données structurées sont perçues comme des solutions pouvant accroître la visibilité d’offres culturelles sur nos écrans, elles appartiennent à des domaines de pratiques pas suffisamment maîtrisés au sein des métiers du Web. C’est pourtant bien vers des spécialistes en développement, intégration, référencement et optimisation que se tournent les acteurs culturels cherchant à rendre le contenu de leurs sites web plus interprétable par des machines. Or, à ma connaissance, il n’existe actuellement pas de formation et de plan de travail tenant compte de l’interdépendance des volets sémantiques, technologiques et stratégiques du web des données.
Exemple: dans la foulée d’une étape importante de ses capacités d’interprétation (traitement automatique du langage), Google a mis à jour, cet été, ses directives d’évaluation de la qualité de l’information. Il va sans dire que c’est important.
Deuxième levier: modernisation des sites web
Dans le Web des moteurs de recherche intelligents, la reconnaissance des entités passe par l’indexation de pages web et l’analyse des contenus. Les sites web devraient donc être des sources d’information de première qualité, tant pour les internautes que pour les moteurs de recherche.
Est-il normal de ne pas trouver toute l’information, riche et détaillée, sur le site de référence d’une entreprise culturelle? Pour le bénéfice des projets numériques, il est vital de concevoir des contenus pertinents pour les machines, lesquelles évaluent à présent la qualité des sources d’information afin de générer la meilleure réponse à retourner à l’utilisateur.
Pour une productrice ou un artiste, il est beaucoup plus stratégique de faire de son site web une source primaire, en attribuant une page spécifique à la description de chaque œuvre, que de créer un article sur Wikipédia. Rappelons que Wikipédia n’est pas une source primaire pour les moteurs de recherche. De plus, l’usage du vocabulaire (Schema.org) ne leur fournit qu’un signal faible sur la nature d’une offre.
Un savoir commun, entre information et informatique
L’adaptation des contenus culturels à l’environnement numérique repose, avant tout, sur de meilleurs sites web. Ces espaces offrent les conditions optimales d’autonomie, repérabilité, accessibilité et interopérabilité. Leur modernisation requiert des acteurs clés, que sont les spécialistes du Web, une mise à niveau rapide de leurs connaissances et de leurs pratiques.
Finalement, afin d’opérer cette mise à niveau et de développer ces savoirs communs, il faut bien entendu insister sur l’interdisciplinarité entre les métiers du web et, notamment, le domaine des sciences de l’information.



![Planche dPlanche de l’Encyclopédie de Diderot et d’Alembert: taille de la plume pour l’écriture. Morburre, [CC BY-SA 3.0], Wikimedia Commonse l’Encyclopédie de Diderot et d’Alembert: Taille de la plume pour l’écriture.](https://fr.wikipedia.org/wiki/Fichier:Ecriture-TaillePlume-Encyclopedie.jpg)
{kind=link}