Pour améliorer la découvrabilité sur Google, mieux vaut utiliser les données là où elles sont vraiment utiles et comprendre les différents types de résultats présentés par le moteur de recherche. En effet, de nouvelles fonctionnalités transforment peu à peu la liste de liens classiques en une interface qui fournit des réponses et des suggestions pour amener les internautes à préciser leurs intentions.
Ces transformations devraient inciter quiconque s’intéresse à la découvrabilité à pratiquer une veille technique (de quoi Google a-t-il besoin maintenant?) et stratégique (pourquoi privilégierait-il ceci?). Ceci n’est apparemment pas le cas: on cherchera en vain de véritables spécialistes de Google au sein des diverses initiatives et comités sur la découvrabilité. Sans être une experte, je m’astreins à rester attentive aux changements.
Voici quelques explications qui permettront de rectifier des interprétations erronées et de réaliser des sites web plus efficaces.
Graphe de connaissances (Knowledge Graph)
Le Knowledge Graph est la base de données factuelles de Google qui est souvent désignée en français par l’expression « graphe de connaissances ». Un graphe est une façon de représenter des liens entre les données relatives à un domaine ou un sujet. Google peut ainsi répondre à une recherche sur une entité nommée en présentant des données extraites de son graphe de connaissances.
Voici un exemple de graphe de données sur une entité fournit par Google dans un brevet publié en 2022.
En culture, les données du graphe proviennent de sites web, ainsi que de sources publiques et privées choisies par Google comme des réseaux de billetterie, des plateformes d’écoute musicale, des distributeurs du domaine de l’édition et des entreprises de média de masse. Lorsque Google identifie, dans une recherche, une entité faisant partie de son graphe de connaissances, il utilise certaines données pour produire une fiche d’information.
L’illustration ci-dessous contient les résultats d’une recherche sur une illustratrice: «Julie Rocheleau illustration ». Nous avons, à gauche, la liste de liens classiques et, à droite, une fiche d’information. Cette fiche peut accompagner la liste de liens lorsque la question n’est pas suffisamment précise, comme dans ce cas-ci. Ainsi, ces informations extraites du graphe offrent des pistes pour raffiner une recherche.
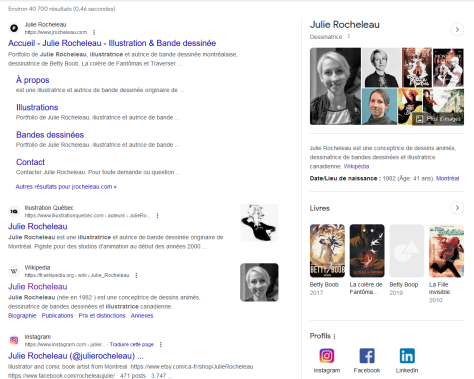
La fiche d’information est utile pour quiconque cherche une chose ou une personne spécifique. Mais ce n’est évidemment pas le meilleur moyen pour faire découvrir ce que nous ne connaissons ou ne cherchons pas! Et si ceci n’était pas suffisant, voici d’autres raisons pour lesquelles il n’est pas judicieux d’espérer exercer un contrôle sur ce type de résultat:
- La génération d’une fiche d’information, autre qu’un profil d’entreprise, dépend de plusieurs facteurs comme la présence de l’entité sur différents sites de qualité et le domaine d’activité; mais elle n’est pas automatique et reste à la discrétion de l’algorithme.
- Seule une entreprise peut créer sa propre fiche par l’entremise de Google Profil d’entreprise, bien que l’algorithme puisse aussi en générer de son propre chef.
- Seule une fiche d’entreprise peut contenir un lien vers son site web; une fiche d’artiste n’a donc pas de lien vers un site.
- Le contenu d’une fiche n’est pas pérenne: le graphe à partir duquel elle est générée peut perdre des attributs. Ceci signifie que des liens ou des images peuvent disparaître suite à un changement tel que la refonte du site où était principalement documentée l’entité sujet de la fiche. Cette mésaventure peut arriver malgré l’existence d’un article sur Wikipédia.
Réponses provenant de contenus web
Sur Google, d’autres types de résultats sont visiblement exploités par les stratégies de contenu d’entreprises commerciales de toutes tailles. En voici trois qui peuvent accroître la découvrabilité de ce que vous souhaitez faire connaître:
- Résultats ou extraits enrichis (Rich snippets);
- Extraits optimisés;
- Questions connexes (« D’autres personnes ont également demandé »).
1. Résultats ou extraits enrichis (Rich snippets)
Les résultats ou extraits enrichis sont des aperçus, sous forme d’images et de brèves descriptions, offerts par Google pour certains types de contenus comme une recette, un livre ou un produit de consommation. Voici le résultat d’une recherche de bandes dessinées pour adultes.
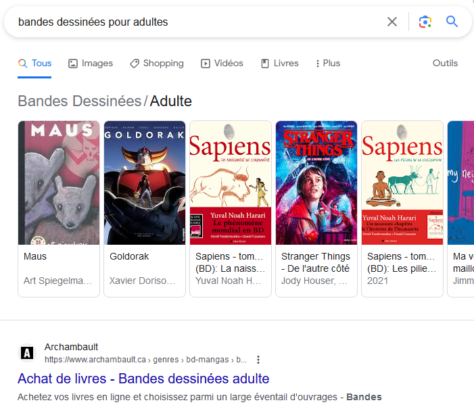
Il est possible d’influencer la probabilité que le moteur de recherche présente une page comme résultat enrichi par l’intégration de balises Schema.org dans le code HTML de la page. Cependant, la génération d’extraits enrichis demeure tributaire des choix de Google pour favoriser les types d’offres et de partenaires qui correspondent au développement de ses affaires.
L’information concernant les bandes dessinées provient de ce que Google appelle des « fournisseurs proposant un large choix de livres ». En d’autres termes, dans la chaîne du livre comme dans d’autres industries, le moteur privilégie les sites d’agrégation comme sources de données. Par conséquent, les autrices, auteurs et maisons d’édition ont plus intérêt à enrichir leurs sites web qu’à fournir une information indifférenciée sous forme de données.
2. Extraits optimisés
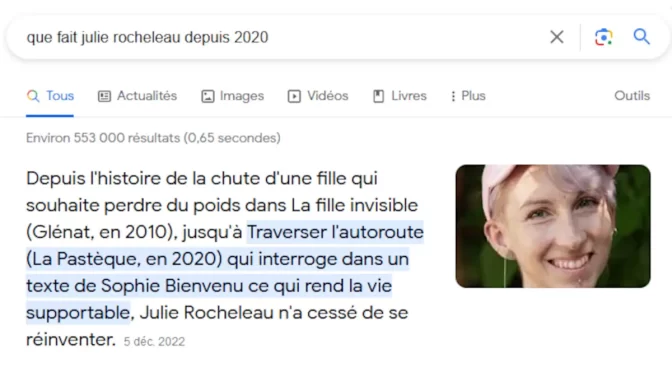
Un extrait optimisé précède parfois la liste de liens résultant d’une question posée dans Google. Il s’agit d’un extrait d’une page web que l’algorithme juge la plus utile pour y répondre à la question d’une . Une vidéo peut également être proposée selon l’interprétation de la requête. Voici un exemple d’extrait obtenu à la suite de cette recherche précise : « que fait Julie Rocheleau depuis 2020 ».
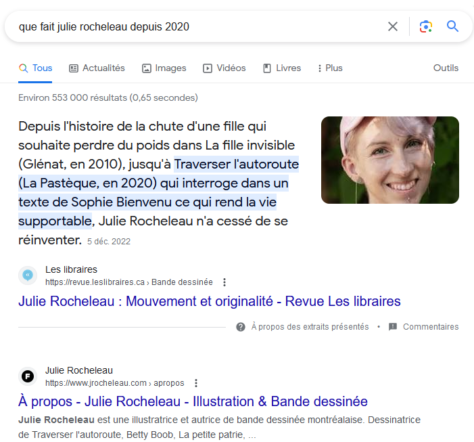
Trois facteurs principaux sont pris en compte pour sélectionner un extrait parmi toutes les pages web mentionnant le même sujet:
- Le profil de l’internaute – Il comprend des éléments tels que langue utilisée, localisation, historique de navigation et intérêts. C’est, entre autres, pour cette raison que Google déconseille d’utiliser les résultats d’une recherche afin d’évaluer l’efficacité générale d’une page web. Plusieurs utilisateurs pourraient tous obtenir des résultats différents.
- L’intention exprimée – Elle peut être plus ou moins facile à interpréter par Google selon le degré de précision de la requête et sa rédaction (syntaxe, termes employés, …). Il est également possible que le moteur ne trouve pas de page utile dans la langue de la personne. Il arrive par contre qu’un extrait soit traduit par Google et libellé comme tel. La liste de liens classiques demeure le résultat par défaut.
- Les pages web – Essentiellement celles qui, présentant le sujet recherché, sont bien construites (concordance entre URL, balise de titre, meta description…) et bien rédigées (longueur du texte, respect de la hiérarchie des titres…). Malheureusement, ces qualités sont beaucoup plus rares que nous le croyons.
L’extrait précède un lien qui mène directement à la page d’origine de l’information. Si vous souhaitez éviter la tendance zéro clic , il serait préférable de rédiger un texte qui soit à la fois une réponse claire et l’amorce d’explications plus détaillées susceptibles de déclencher la visite.
Conseil aux développeurs : Google utilise également des éléments d’information tirés de listes ou de tableaux en format HTML. Ces tableaux de données auraient de meilleures chances d’être interprètés et utilisés s’ils étaient présentés dans un élément <table> plutôt que dans une série de <div>.
3. Questions connexes
À la suite d’un extrait optimisé, on trouve souvent, dans la liste de liens, un bloc intitulé « Questions connexes » ou encore « D’autres personnes ont également demandé ». Ce bloc sera affiché lorsqu’on rédigé une demande suffisamment claire pour être bien interprétée comme dans l’exemple ci-dessous: comment créer une bande dessinée en ligne.
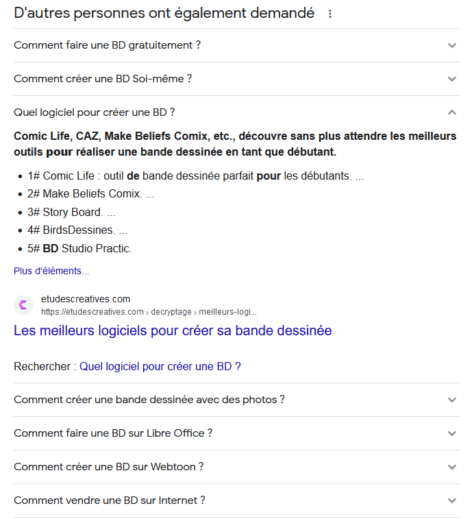
Les réponses à ces questions connexes proviennent des extraits optimisés. Elles sont sélectionnées en fonction de leur proximité avec la requête de l’internaute. La version linguistique utilisée ainsi que la localisationde l’utilisateur sont les principaux facteurs de sélection des questions et réponses.
Pour rédiger des textes plus pertinents pour vos publics, vous pouvez donc vous inspirer de questions adressées à Google par des internautes sur des sujets associés à votre domaine. Une information pertinente et intéressante sera susceptible de générer des visites et de faire découvrir d’autres pages sur votre site.
Conclusion
Miser sur des données pour améliorer la découvrabilité sur Google n’est ni efficace, ni stratégique. Les extraits optimisés et questions connexes sont les types de résultats de recherche qui offrent le plus grand potentiel de découvrabilité, hors publicité payante.
Alors que Google a intégré l’IA dans son interface pour aider les utilisateurs à formuler leurs recherches, il devient important de remettre la rédaction d’information au cœur des stratégies numériques. Ceci nous oblige à développer une connaissance plus fine des publics et clientèles afin de documenter de manière pertinente et riche les divers aspects d’un domaine ou d’une pratique.


{kind=link}
{kind=link}