Les formations, référentiels, trousses à outils, programmes de financement et experts en découvrabilité abondent. Tous peuvent se saisir des termes et notions qui circulent sans avoir une compréhension approfondie du Web. C’est, à mon avis, préoccupant car il n’existe pas de traité sur ce qu’il faut faire, dans le numérique, pour qu’une information soit vue. À la différence du génie ou de la médecine, par exemple, il n’y a pas de socle commun de connaissances pour les divers métiers du Web. Un projet numérique est souvent une tour de Babel de concepts. Que des non-spécialistes du numérique, comme des directions d’entreprises, soit dépassés n’est pas étonnant.
Voici une proposition pour améliorer les connaissances des personnes, organisations et instances gouvernementales sur un concept aussi vague que la découvrabilité. Tous les secteurs d’activité sont concernés, bien qu’à certains égards, je fais référence à la culture puisque le concept ne semble pas soulever autant d’intérêt dans d’autres domaines.
- D’abord, mettre sur pied un comité scientifique et pédagogique qui sera chargé d’inventorier et sélectionner les connaissances qui serviront de base à la création du matériel. Il s’agit, plus concrètement d’élaborer un programme qui s’étend sur des domaines d’expertise différents et d’en assurer la mise à jour.
- Ensuite, différents publics cibles doivent être identifiés en fonction de leurs profils professionnels, secteurs de pratique et pouvoir décisionnel.
- Enfin, proposer des parcours de formation en fonction d’objectifs concrets afin de réinvestir les connaissances acquises: répondre à un besoin précis ou résoudre un problème. Il ne s’agit pas de former des spécialistes du traitement documentaire ou de l’analyse de données.
Voici quelques éléments de discussion pour un comité scientifique et pédagogique.
Solutionnisme technologique
Lorsque nos formations et projets sont focalisés sur des solutions technologiques, nous nous rendons encore plus dépendants de systèmes que nous ne maîtrisons pas. Nous n’activons pas les transformations que les organismes nés à l’ère numérique n’ont pas eu à faire. Comment dépasser la couche superficielle du problème pour investiguer davantage nos pratiques industrielles et sectorielles? Comment éviter le piège de l’outil providentiel pour développer une pensée stratégique adaptée à un monde numérique?
Découvrabilité: du concret
Les définitions habituelles de la découvrabilité sont vaguement théoriques et rarement mises en contexte. Ce terme est fréquemment invoqué en réponse aux problématiques liées à la visibilité et à l’appétit du public pour des offres culturelles. À quelles intentions ou objectifs fait-on référence? S’agit-il de contrôler ou d’influencer ce qui est présenté sur les écrans des utilisateurs?
Technologies: connaissances de base
Où se passe la découvrabilité? Plateformes de contenus sur abonnement, sites web, réseaux sociaux, bases de données, jeux de données ouvertes, bases de données en graphes: ces technologies ne sont pas des vases communicants. Il est essentiel d’identifier et décrire clairement les caractéristiques et usages spécifiques des différents environnements technologiques qui peuvent être ciblés par des initiatives numériques. Piloter un projet sans bien connaître les particularités des environnements concernés n’est scientifiquement pas acceptable.
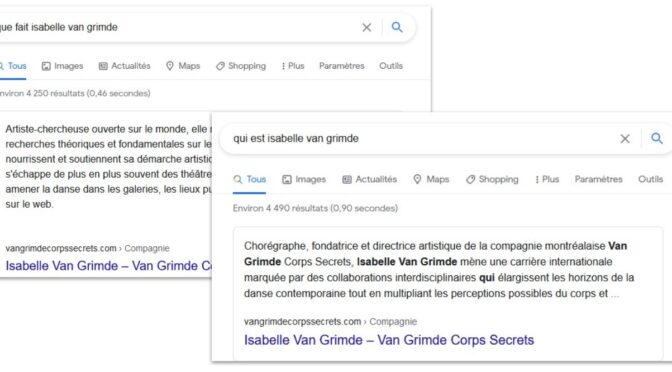
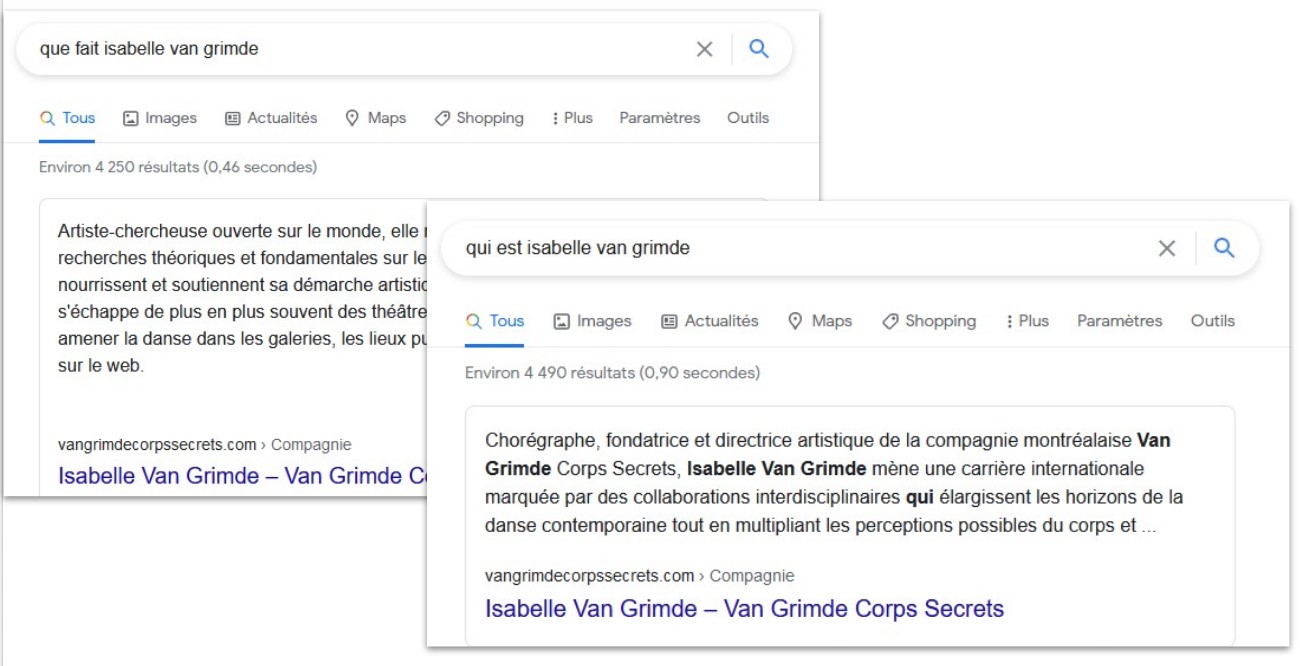
Comprendre Google
L’histoire et les évolutions récentes des applications du moteurs sont suivies et documentées par différentes communautés d’experts. Le fonctionnement du moteur de recherche doit être expliqué afin d’aligner des initiatives vers des objectifs réalistes. Alors que la plupart des initiatives visent à influencer les réponses de Google, ce serait l’occasion de définir de bonnes méthodes de conception et pratiques pour le Web.
Pas de culture sans publics
Ou plus généralement: pas de ventes dans clientèles. Sur les plateformes et moteurs de recherche, données et algorithmes sont pourtant mis à profit pour connaître et servir les utilisateurs. Chaînon manquant de la plupart des projets, la connaissance des publics, leurs usages et leurs comportements, ne doit pas être limitée à la production de statistiques. Quelles connaissances et méthodologies appropriées proposer à des non-spécialistes du marketing?
Curiosité, médiation, sérendipité
Quelles autres entités et dispositifs favorisent la découverte sur des temps plus ou moins longs? Quels autres chemins pourrait-on emprunter si des résultats immédiats n’étaient pas exigés?
* * *
Il est temps d’avoir des conversations sur ces sujets afin de développer les parcours d’apprentissage qui manquent à l’émergence d’une force collective, sur le Web et les différents canaux numériques. Comment assurer la cohérence de programmes, initiatives et développement professionnel sans un tronc commun de connaissances? Comment pérenniser des activités de veille et de transfert? Comment concevoir des projets qui sont interdépendants et ont donc, plus d’incidence sur la société et l’économie? Il ne faudrait plus attendre pour élaborer un schéma des connaissances partagées par tous les acteurs du numérique et transversales à tous les secteurs d’activités.

![Planche dPlanche de l’Encyclopédie de Diderot et d’Alembert: taille de la plume pour l’écriture. Morburre, [CC BY-SA 3.0], Wikimedia Commonse l’Encyclopédie de Diderot et d’Alembert: Taille de la plume pour l’écriture.](https://fr.wikipedia.org/wiki/Fichier:Ecriture-TaillePlume-Encyclopedie.jpg)




{kind=link}