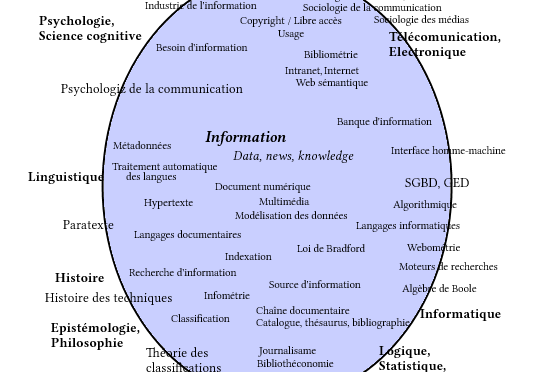
En culture comme en commerce, les initiatives de mise en commun de données numériques, constituent de nouveaux « milieux documentaires ». Au Québec, pourtant, les compétences et méthodes du domaine des sciences de l’information sont rarement sollicitées. Les institutions d’enseignement et les associations professionnelles concernées devraient pourtant reconnaître, dans ces projets, les notions et enjeux entourant les systèmes documentaires classiques.

Voici quelques lectures récentes illustrant des défis que pourraient relever les spécialistes intéressés par ces nouveaux milieux documentaires.
Taxonomie pour des contenus en mutation
▣ Dominic Tardif. « Ces livres qui se dérobent aux étiquettes ». Le Devoir, 9 janvier 2021.
Cet article introduit certains défis actuels de l’élaboration d’un modèle de métadonnées qui permette de faire des liens entre les ressources de bases de données différentes.
Tout choix est subjectif; il n’y a donc pas de donnée neutre. Un modèle de classement ou de catégorisation peut être porteur d’exclusion, notamment de ce qui peut apparaître inclassable (personne non genrée, pratiques artistiques hybrides…) car il impose le choix d’un descriptif parmi un nombre limité d’options.
Que faire des œuvres qui n’ont pas été pensées et créées dans le cadre d’une pratique déjà bien étiquetée? Et surtout, comment documenter l’intention?
Ça devient un problème à partir du moment où des livres ne reçoivent pas la reconnaissance qu’ils devraient avoir parce qu’on les juge à partir de critères qui n’ont rien à voir avec leur projet littéraire.
Clara Dupuis-Morency, autrice et enseignante en littérature.
Comment, alors, respecter la création, anticiper les biais et éviter que la perspective d’une culture dominante n’occulte celles d’autres cultures?
Un catalogage qui se satisferait de distinguer les textes de fiction des textes entretenant un rapport plus immédiat au réel serait donc inefficace.
ibid.
Algorithmes de recommandation personnalisée
▣ The NYT Open Team. « We Recommend Articles With a Little Help From Our Friends (Machine Learning and Reader Input) ». NYT Open, 14 janvier 2021.
Ce billet publié par l’équipe des produits numériques du New York Times met en lumière le travail d’indexation et de catalogage requis par le développement d’un algorithme de recommandation. Il souligne l’importance d’intégrer la pensée humaine aux processus automatisés de traitement documentaire.
Le nettoyage des données et l’amélioration de la qualité descriptive des métadonnées sont des opérations essentielles à l’exploitation d’une base de données. Elles le sont également dans le cas d’un programme d’apprentissage automatique ayant pour objectif l’entraînement ou le bon fonctionnement d’un algorithme de recommandation.
When we took a deeper look at a few of the incorrect labels, we could often understand why the model assigned the label, but saw that correcting the mistake requires human judgement. It takes knowledge of history and society, as well as the ability to recognize context to intuit that some articles are better suited for some interest categories than others.
The NYT Open Team
(…)
Readers trust The Times to curate content that is relevant to them, and we take this trust seriously. This algorithm, like many other AI-based decision-making systems, should not make the final call without human oversight.
ibid.
De taxonomie à ontologie: un défi de taille!
▣ Heather Hedden. « Hierarchies in Taxonomies, Thesauri, Ontologies, and Beyond ». The Accidental Taxonomist, 20 janvier 2021.
À lire avant de convertir une taxonomie (ou tout autre vocabulaire contrôlé) en ontologie. Il s’agit bien de référentiels ayant des rôles différents et la problématique réside principalement dans les caractéristiques spécifiques de ces différents modes d’organisation des connaissances. Par exemple: l’adaptation de la structure hiérarchique d’une taxonomie à la structure en graphe d’une ontologie de domaine.
The problem is that the definitions and rules for hierarchies vary depending on the kind of knowledge organization system, so you cannot assume that a hierarchy in one system converts to a hierarchy in another system.
(…)
“Hierarchy” can have various types and uses. Not all kinds of hierarchies are reflected in even in taxonomies, which tend to be quite flexible. The rules are stricter when it comes to thesauri. Finally, in ontologies, there is only one kind of hierarchy.
Heather Hedden, taxonomiste, ontologiste, autrice et formatrice.
Culture de l’information et méthodes de travail
▣ Mike Tung. « From Knowledge Graphs to Knowledge Workflows ». Diffbot, 19 janvier 2021.
Le concept de « graphe de connaissance » (knowledge graph), a été popularisé par Google, bien que des structures de données en graphes existaient auparavant dans différents domaines. Ce type de structure est souvent perçu comme une solution qui permette d’imposer un modèle descriptif assurant la visibilité et/ou l’interopérabilité de ressources informationnelles.
L’adoption d’un modèle descriptif unique entraîne cependant une uniformisation des perspectives qui conduit à l’aplatissement des connaissances. C’est également la source de problèmes rarement anticipés. Par exemple: l’adoption d’un vocabulaire commun dans toute l’organisation va-t-elle «pérenniser» vos données ou entraîner des réunions sans fin pour débattre de ses mises à jour des vocabulaires et des ontologies sont discutées?
If we instead listen to the problems information workers have, spend a day shadowing them in their jobs, and design solutions that integrate knowledge-tech in a lightweight way to automate tedium, then we have a shot at solving a larger set of problems, to benefit more of society.
Mike Tung, CEO Diffbot.
Au-delà du solutionnisme technologique, il faut explorer les bénéfices issus du développement d’une véritable culture de l’information au sein des organisations. Cela signifie que la gestion et la qualité de l’information sont des responsabilités devant être partagées dans une organisation et non plus limitées au service des technologies de l’information.
Découvrabilité hors du Web des moteurs de recherche
▣ Greta Bahnemann, Michael Carroll, Paul Clough, Mario Einaudi, Chatham Ewing, Jeff Mixter, Jason Roy, Holly Tomren, Bruce Washburn, Elliot Williams. « Transforming Metadata into Linked Data to Improve Digital Collection Discoverability: A CONTENTdm Pilot Project. OCLC, 2021.
OCLC, un organisme sans but lucratif au service des bibliothèques, rend compte d’un projet pilote sur la transformation des métadonnées de collections en données liées. Il nous rappelle que la découvrabilité recherchée n’est pas celle qui se mesure à l’aulne des résultats de Google ou des cotes de popularité des plateformes de contenus.
Les bases de données en graphe – il faut le répéter – ne sont pas indexées par les moteurs de recherche. Il existe d’autres espaces numériques où l’accès à la culture pourrait fournir des expériences de recherche et découverte pertinentes et efficaces. Exemple: naviguer à travers des collections qui proposent des connexions que des bases de données classiques n’arrivent pas à révéler.
Representing what is locally unique yet making local information legible to outsiders and creating a mechanism where differences can be understood, bridged, and linked is an important part of what public libraries using newer descriptive systems can surface.
À l’image des initiatives de la BnF et d’Europeana, le projet d’OCLC a permis à des institutions de se familiariser avec des méthodes et outils du web sémantique :
The Linked Data project demonstrated the amount of work involved in the transition to linked data, but also that the tools exist and that the workflows can be developed.
Pour une vision systémique du numérique
Les initiatives et projets qui visent à structurer l’information pour le numérique constituent de nouveaux milieux documentaires, hors des lieux habituels que sont les bibliothèques, centres de documentation et fonds d’archives. Les professionnels des sciences de l’information sont formés pour relever les défis inhérents aux « espaces» numériques que sont les sites web, les plateformes commerciales, le Web des données et, même, les jeux de données ouvertes. Il serait temps que la rencontre entre tous ces acteurs se réalise. La réussite de nos initiatives en dépend.
Bonjour,
Vos commentaires et réflexions sont très inspirantes.
Votre conclusion : « Il serait temps que la rencontre entre tous ces acteurs se réalise. La réussite de nos initiatives en dépend « , est une proposition urgente !