![Planche dPlanche de l’Encyclopédie de Diderot et d’Alembert: taille de la plume pour l’écriture. Morburre, [CC BY-SA 3.0], Wikimedia Commonse l’Encyclopédie de Diderot et d’Alembert: Taille de la plume pour l’écriture.](https://fr.wikipedia.org/wiki/Fichier:Ecriture-TaillePlume-Encyclopedie.jpg)
Or, ce ne sont plus les balises Schema.org insérées dans le code ni les articles de Wikipédia qui facilitent le travail des moteurs de recherche en les rendant intelligents. C’est, à présent, le traitement automatique du langage naturel. Celui-ci permet aux algorithmes d’évaluer l’information présente sur une page web et lisible par les humains.
Plus l’information offerte par le texte est riche et contextualisée par des liens vers d’autres pages web, plus elle a de valeur pour nous et, par conséquent, pour les moteurs de recherche dont l’objectif est de nous offrir les meilleurs résultats possibles.
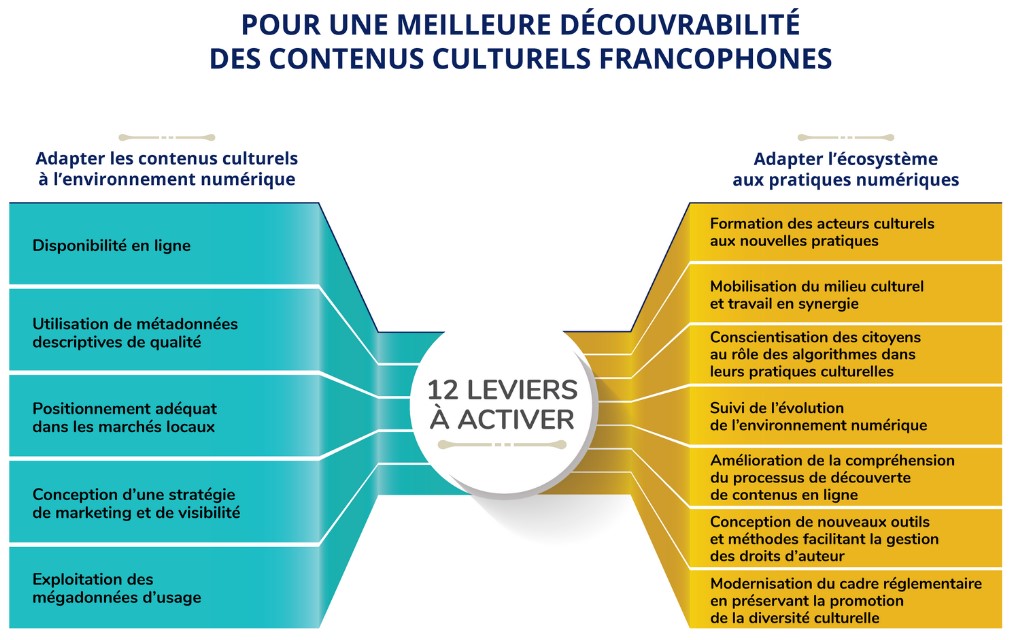
Un travail de spécialistes
Après quelques années d’accompagnement d’entrepreneurs culturels, je peux affirmer que rares sont les non-initiés sachant manier avec aisance des notions et des mécanismes qui demeurent complexes, même pour des spécialistes du Web. Ce billet sur les définitions divergentes de ce qu’est une ontologie permet de mesurer le défi d’établir une compréhension commune et claire d’une notion pourtant fondamentale des systèmes documentaires. Et pour celles et ceux qui persévèrent, les concepts et pratiques nouvellement acquis sont trop éloignés de leurs activités pour qu’ils soient en mesure de les intégrer aux opérations et de se livrer à la veille technique qui s’impose en permanence.
Structurer de l’information pour une variété d’usages et de systèmes, c’est un travail de spécialistes. Le rôle de créateurs de contenu consiste à documenter cette information et à raconter comment elle s’insère dans notre monde. Ils peuvent se faire aider afin de produire l’information répondant le mieux aux intérêts des publics cibles et de fournir des liens nécessaires aux humains et aux machines pour apporter du contexte, favorisant ainsi la découverte.
Voici les étapes qu’il faudrait suivre afin d’améliorer la valeur informative de la page web consacrée à une offre culturelle:
1- Stratégie: quelle information, à quels publics, pour quels résultats
Mieux un contenu est documenté, plus il est susceptible de pouvoir réponse à une question. Il est donc important de baser la conception du contenu d’une page sur une solide connaissance des publics cibles. D’où la nécessité d’une stratégie et d’une concertation entre les producteurs, diffuseurs et toutes autres parties concernées. Toutefois, l’élaboration d’une stratégie de ce type requiert une formation préalable mobilisant divers spécialistes.
2- Documentation: les choses et les relations entre ces choses
L’adaptation de nos contenus culturels à l’environnement numérique commence par l’écriture. Tous les éditeurs de sites web doivent à présent mieux organiser et documenter leurs contenus pour les rendre plus repérables. Pour Google, « documenter » signifie: bien décrire un contenu et fournir du contexte en faisant des liens entre des concepts. Plus la documentation est exhaustive et clairement libellée, plus elle a de la valeur pour les utilisateurs — et plus la page web de l’offre culturelle devient une source d’information de qualité.
3- Balises: signaler certains types de contenus
Certains types de contenus — comme les vidéos, par exemple — peuvent apparaître sous forme d’extraits, dans la liste de résultats de Google (résultats enrichis). L’utilisation de balises permettant de catégoriser des contenus n’est donc pertinente que pour un petit nombre d’offres. Les modèles descriptifs recommandés sont ceux qui concernent les projets de développement des services du moteur de recherche. De plus, les consignes à suivre évoluent en fonction du résultat des expérimentations et de l’avancement du traitement automatique du langage.
Nous devons, alors, éviter de développer des fonctionnalités qui deviennent rapidement obsolètes ou, pire, qui réduisent notre capacité d’innovation en l’encadrant dans la logique d’affaires d’une plateforme. Il faut donc que nous demeurions extrêmement vigilants afin que nos projets nous apportent une réelle valeur et ne tombent pas dans le solutionnisme technologique.
4- Wikipédia: création d’article utile, mais non essentielle
Wikipédia facilite l’identification d’un concept ou objet spécifique, mais ce sont les pages web qui sont les sources primaires pour Google. Contrairement à la croyance courante, la production d’une fiche de réponse (appelée « knowledge panel ») résulte du traitement du contenu provenant de différentes pages web. Celles-ci sont qualifiées par le moteur de recherche pour l’information qu’elles offrent. En analysant certains brevets déposés par Google, on peut déduire que son utilisation de l’encyclopédie n’est ni constante, ni déterminante. Créer un article Wikipédia n’est donc pas une activité essentielle dans un plan de découvrabilité, même si cela peut accroître la notoriété d’un sujet lorsqu’il contient des connaissances utiles et des liens vers d’autres articles.
L’écriture: une « solution » à la portée de tous!
Adapter nos contenus culturels à l’environnement numérique commence donc par une technique millénaire: l’écriture. Nous pourrions beaucoup mieux documenter nos offres culturelles sur nos sites web sans nécessairement plonger dans des domaines de connaissance complexes. Il suffit d’apprendre à décrire des choses et les relations entre ces choses pour des systèmes qui, eux-même, apprennent à lire afin de fournir la meilleure information à leurs utilisateurs. Bref, avant de se lancer dans la modélisation de données ou le web sémantique, il serait temps de revenir aux stratégies de communication, ainsi qu’aux bonnes pratiques de rédaction web.






{kind=link}