Quelle est la probabilité que des données ouvertes et liées fassent découvrir une chose qu’on ne connaît ou ne cherche pas? Le potentiel de découvrabilité d’une offre culturelle sous forme de données avec les technologies du Web sémantique est très faible. Pourtant, l’Appel de projets pour le développement culturel numérique dans la francophonie canadienne privilégie la « production et la diffusion la plus large possible de métadonnées (idéalement sous forme de données ouvertes et liées) ». Les arguments qui soutiennent cette orientation gagneraient à être partagés et discutés au sein de comités scientifiques et techniques.
Continuer la lecture de Quel est le potentiel de découvrabilité des données ouvertes et liées?Archives par mot-clé : stratégie

Redéfinir la découvrabilité pour une pensée stratégique
Potentiel pour un contenu, disponible en ligne, d’être aisément découvert par des internautes dans le cyberespace, notamment par ceux qui ne cherchaient pas précisément le contenu en question.
C’est une vision qui rend attrayante une solution aussi improbable que des métadonnées pour influencer Google. Mais surtout, une telle démarche élude l’étape la plus importante d’un projet qu’est la réflexion stratégique.
Comprendre une problématique multidimensionnelle
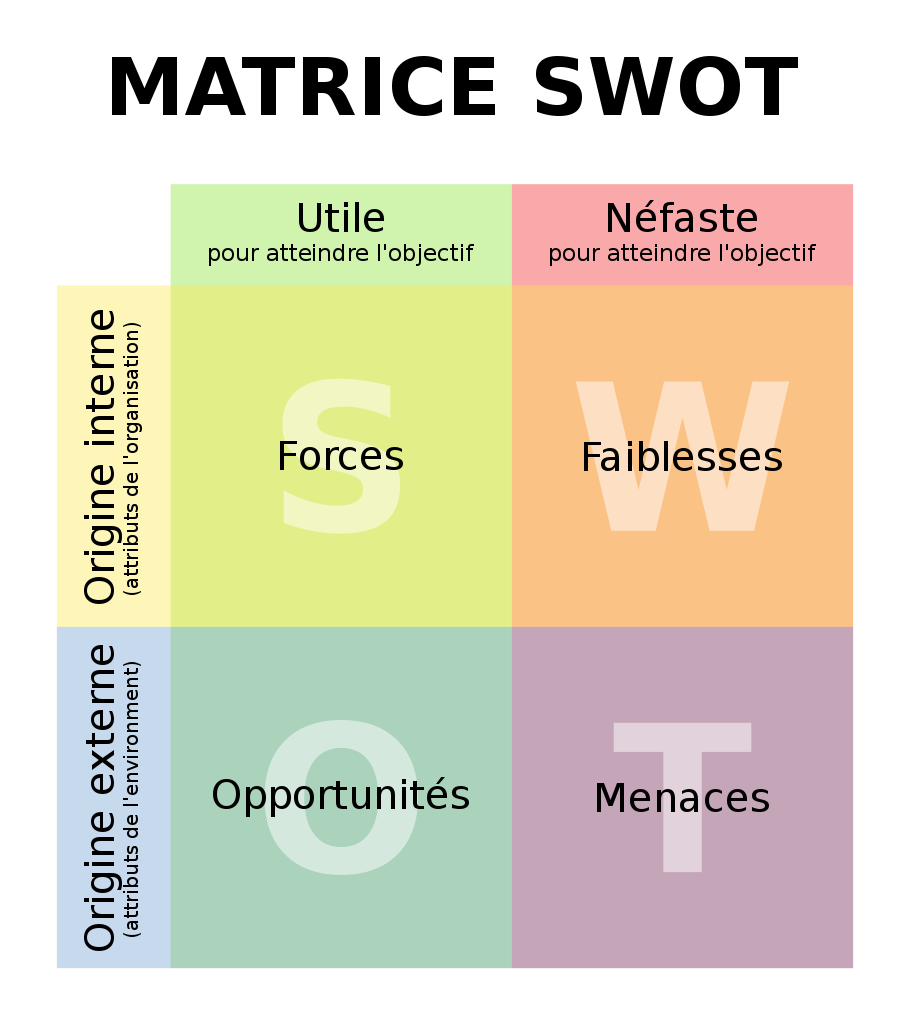
Une analyse stratégique permet pourtant d’identifier les facteurs internes (forces, faiblesses) et externes (opportunités, menaces) qui peuvent faciliter ou entraver la réalisation des objectifs souhaités. En voici des exemples:
Force (facteur interne): la connaissance de l’environnement technologique préconisé est suffisamment maîtrisée par la direction pour communiquer clairement sur les résultats tangibles attendus (ce que ça peut faire) et dissiper le fantasme du techno solutionnisme (ce que ça ne fait pas).
Menace (facteur externe): des pratiques industrielles et modèles d’affaires rendent des contenus indisponibles ou introuvables, comme l’affirme Philippe Falardeau dans cet article sur la possible fermeture d’un distributeur de films.
Rechercher des résultats concrets
Voici une définition plus précise de la découvrabilité et qui m’apparaît encourager une démarche stratégique:
La découvrabilité est le résultat potentiel de stratégies et moyens mis en œuvre, dans un environnement technologique donné, afin de favoriser des liens entre les intérêts de publics cibles et une offre qu’ils ne connaissent pas ou ne cherchent pas.
Elle comprend les éléments clés d’un questionnement préalable à la recherche d’une solution:
- Le but: problème ou besoin concret (achat, visite, développement de compétences)?
- Les publics cibles: quels sont-ils et quels sont leurs profils d’intérêts?
- L’environnement technologique choisi: quelles sont les particularités de l’espace numérique choisi pour favoriser la découverte? Quelles sont les expertises requises?
***
Il serait essentiel de redéfinir la découvrabilité afin que chaque initiative numérique du domaine des arts et de la culture entreprenne une analyse stratégique. C’est en réalisant une telle démarche, en amont de la recherche d’une solution, que les organisations peuvent développer leur capacité d’adaptation et d’innovation.
Comment améliorer la découvrabilité sur Google?
Pour améliorer la découvrabilité sur Google, mieux vaut utiliser les données là où elles sont vraiment utiles et comprendre les différents types de résultats présentés par le moteur de recherche. En effet, de nouvelles fonctionnalités transforment peu à peu la liste de liens classiques en une interface qui fournit des réponses et des suggestions pour amener les internautes à préciser leurs intentions.
Continuer la lecture de Comment améliorer la découvrabilité sur Google?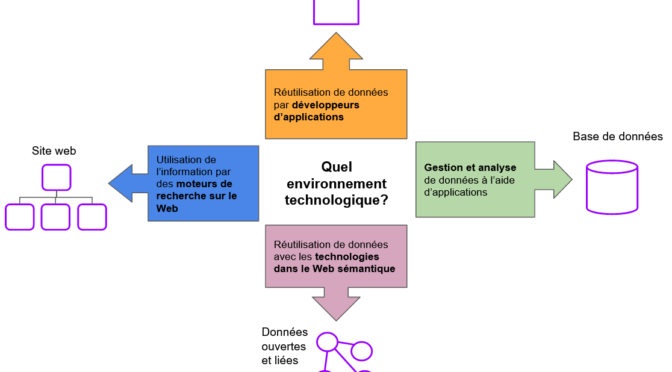
Découvrabilité: oui, mais dans quel environnement technologique?
Favoriser la découverte d’une offre pour atteindre un objectif c’est bien, mais dans quel environnement technologique? La réponse à cette question, rarement abordée, pourrait pourtant aiguiller certains projets ciblant les moteurs de recherche vers de meilleures pratiques de conception et de rédaction pour le Web plutôt que vers la création de métadonnées.
Continuer la lecture de Découvrabilité: oui, mais dans quel environnement technologique?
L’angle mort de la promotion de l’offre culturelle sur le Web
![Planche dPlanche de l’Encyclopédie de Diderot et d’Alembert: taille de la plume pour l’écriture. Morburre, [CC BY-SA 3.0], Wikimedia Commonse l’Encyclopédie de Diderot et d’Alembert: Taille de la plume pour l’écriture.](https://fr.wikipedia.org/wiki/Fichier:Ecriture-TaillePlume-Encyclopedie.jpg)
Or, ce ne sont plus les balises Schema.org insérées dans le code ni les articles de Wikipédia qui facilitent le travail des moteurs de recherche en les rendant intelligents. C’est, à présent, le traitement automatique du langage naturel. Celui-ci permet aux algorithmes d’évaluer l’information présente sur une page web et lisible par les humains.
Plus l’information offerte par le texte est riche et contextualisée par des liens vers d’autres pages web, plus elle a de valeur pour nous et, par conséquent, pour les moteurs de recherche dont l’objectif est de nous offrir les meilleurs résultats possibles.
Un travail de spécialistes
Après quelques années d’accompagnement d’entrepreneurs culturels, je peux affirmer que rares sont les non-initiés sachant manier avec aisance des notions et des mécanismes qui demeurent complexes, même pour des spécialistes du Web. Ce billet sur les définitions divergentes de ce qu’est une ontologie permet de mesurer le défi d’établir une compréhension commune et claire d’une notion pourtant fondamentale des systèmes documentaires. Et pour celles et ceux qui persévèrent, les concepts et pratiques nouvellement acquis sont trop éloignés de leurs activités pour qu’ils soient en mesure de les intégrer aux opérations et de se livrer à la veille technique qui s’impose en permanence.
Structurer de l’information pour une variété d’usages et de systèmes, c’est un travail de spécialistes. Le rôle de créateurs de contenu consiste à documenter cette information et à raconter comment elle s’insère dans notre monde. Ils peuvent se faire aider afin de produire l’information répondant le mieux aux intérêts des publics cibles et de fournir des liens nécessaires aux humains et aux machines pour apporter du contexte, favorisant ainsi la découverte.
Voici les étapes qu’il faudrait suivre afin d’améliorer la valeur informative de la page web consacrée à une offre culturelle:
1- Stratégie: quelle information, à quels publics, pour quels résultats
Mieux un contenu est documenté, plus il est susceptible de pouvoir réponse à une question. Il est donc important de baser la conception du contenu d’une page sur une solide connaissance des publics cibles. D’où la nécessité d’une stratégie et d’une concertation entre les producteurs, diffuseurs et toutes autres parties concernées. Toutefois, l’élaboration d’une stratégie de ce type requiert une formation préalable mobilisant divers spécialistes.
2- Documentation: les choses et les relations entre ces choses
L’adaptation de nos contenus culturels à l’environnement numérique commence par l’écriture. Tous les éditeurs de sites web doivent à présent mieux organiser et documenter leurs contenus pour les rendre plus repérables. Pour Google, « documenter » signifie: bien décrire un contenu et fournir du contexte en faisant des liens entre des concepts. Plus la documentation est exhaustive et clairement libellée, plus elle a de la valeur pour les utilisateurs — et plus la page web de l’offre culturelle devient une source d’information de qualité.
3- Balises: signaler certains types de contenus
Certains types de contenus — comme les vidéos, par exemple — peuvent apparaître sous forme d’extraits, dans la liste de résultats de Google (résultats enrichis). L’utilisation de balises permettant de catégoriser des contenus n’est donc pertinente que pour un petit nombre d’offres. Les modèles descriptifs recommandés sont ceux qui concernent les projets de développement des services du moteur de recherche. De plus, les consignes à suivre évoluent en fonction du résultat des expérimentations et de l’avancement du traitement automatique du langage.
Nous devons, alors, éviter de développer des fonctionnalités qui deviennent rapidement obsolètes ou, pire, qui réduisent notre capacité d’innovation en l’encadrant dans la logique d’affaires d’une plateforme. Il faut donc que nous demeurions extrêmement vigilants afin que nos projets nous apportent une réelle valeur et ne tombent pas dans le solutionnisme technologique.
4- Wikipédia: création d’article utile, mais non essentielle
Wikipédia facilite l’identification d’un concept ou objet spécifique, mais ce sont les pages web qui sont les sources primaires pour Google. Contrairement à la croyance courante, la production d’une fiche de réponse (appelée « knowledge panel ») résulte du traitement du contenu provenant de différentes pages web. Celles-ci sont qualifiées par le moteur de recherche pour l’information qu’elles offrent. En analysant certains brevets déposés par Google, on peut déduire que son utilisation de l’encyclopédie n’est ni constante, ni déterminante. Créer un article Wikipédia n’est donc pas une activité essentielle dans un plan de découvrabilité, même si cela peut accroître la notoriété d’un sujet lorsqu’il contient des connaissances utiles et des liens vers d’autres articles.
L’écriture: une « solution » à la portée de tous!
Adapter nos contenus culturels à l’environnement numérique commence donc par une technique millénaire: l’écriture. Nous pourrions beaucoup mieux documenter nos offres culturelles sur nos sites web sans nécessairement plonger dans des domaines de connaissance complexes. Il suffit d’apprendre à décrire des choses et les relations entre ces choses pour des systèmes qui, eux-même, apprennent à lire afin de fournir la meilleure information à leurs utilisateurs. Bref, avant de se lancer dans la modélisation de données ou le web sémantique, il serait temps de revenir aux stratégies de communication, ainsi qu’aux bonnes pratiques de rédaction web.
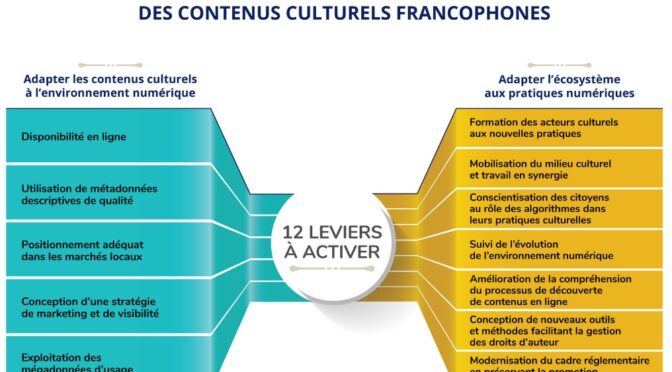
Deux leviers à ajouter au rapport de la mission franco-québécoise sur la découvrabilité
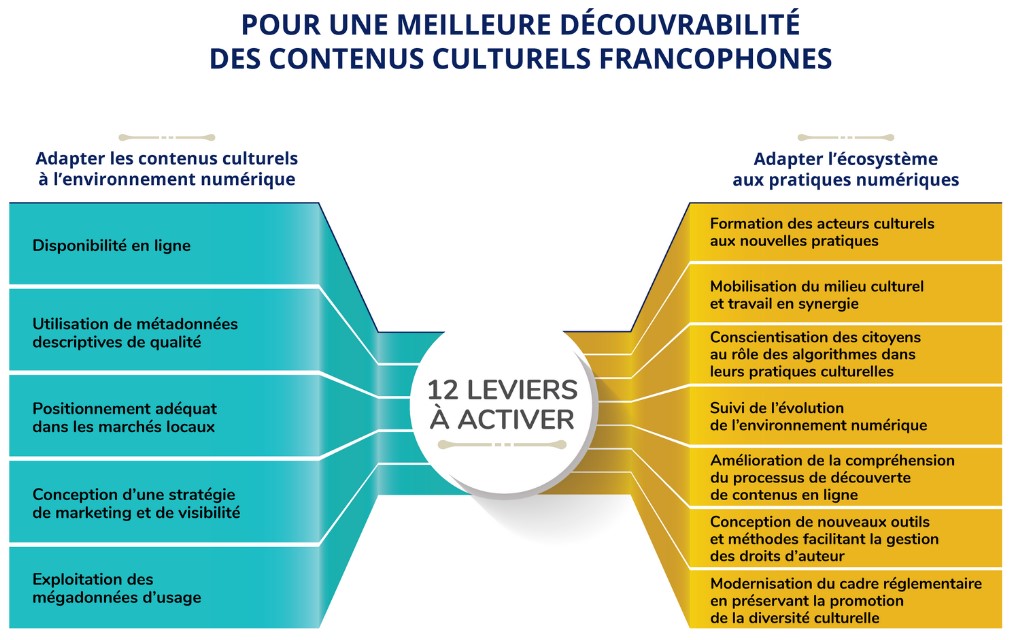
Le rapport sur la découvrabilité en ligne des contenus culturels francophones résulte d’une mission conjointe des ministères de la Culture du Québec et de la France. Il dresse un bon état des lieux d’un ensemble de phénomènes et d’actions, sans égarer le lecteur dans les détails techniques. Un excellent exercice de synthèse, donc, réalisé par Danielle Desjardins, auteure de plusieurs rapports pour le secteur culturel et collaboratrice du site de veille du Fonds des médias du Canada.
Cependant, dans le schéma des 12 leviers à activer pour une meilleure découvrabilité des contenus culturels francophones (voir plus haut), il manque à mon avis deux éléments essentiels:
- Est-ce aux acteurs culturels que revient la charge de rendre l’information concernant leurs créations ou leurs offres numériquement opérationnelle?
- Quel espace numérique offre les meilleures conditions de repérabilité, d’accessibilité et d’interopérabilité de l’information ?
Premier levier: mises à niveau des métiers du Web
Il est important de sensibiliser les acteurs culturels à l’adoption de pratiques documentaires telles que l’indexation de ressources en ligne. Ceci dit, la mise en application des principes, ainsi que le choix de modèles de représentation de contenus en ligne, sont des compétences qui ne s’acquièrent pas comme on apprend à se servir d’un logiciel. On ne peut pas attendre de toute personne et organisation du secteur culturel de tels efforts d’apprentissage. D’autant plus que la production de l’information pour le numérique fait appel à des méthodes et savoirs relevant des domaines du langage et de la représentation des connaissances autant que des technologies numériques.
Si les données structurées sont perçues comme des solutions pouvant accroître la visibilité d’offres culturelles sur nos écrans, elles appartiennent à des domaines de pratiques pas suffisamment maîtrisés au sein des métiers du Web. C’est pourtant bien vers des spécialistes en développement, intégration, référencement et optimisation que se tournent les acteurs culturels cherchant à rendre le contenu de leurs sites web plus interprétable par des machines. Or, à ma connaissance, il n’existe actuellement pas de formation et de plan de travail tenant compte de l’interdépendance des volets sémantiques, technologiques et stratégiques du web des données.
Il devient de plus en plus impératif d’identifier les connaissances à développer ou à approfondir chez les divers spécialistes contribuant à la conception de sites web aux contenus plus repérables. Il serait également souhaitable de soutenir un réseau de veille interdisciplinaire ayant pour objectif de contextualiser et d’analyser l’évolution de l’écosystème numérique.
Exemple: dans la foulée d’une étape importante de ses capacités d’interprétation (traitement automatique du langage), Google a mis à jour, cet été, ses directives d’évaluation de la qualité de l’information. Il va sans dire que c’est important.
Deuxième levier: modernisation des sites web
Dans le Web des moteurs de recherche intelligents, la reconnaissance des entités passe par l’indexation de pages web et l’analyse des contenus. Les sites web devraient donc être des sources d’information de première qualité, tant pour les internautes que pour les moteurs de recherche.
Est-il normal de ne pas trouver toute l’information, riche et détaillée, sur le site de référence d’une entreprise culturelle? Pour le bénéfice des projets numériques, il est vital de concevoir des contenus pertinents pour les machines, lesquelles évaluent à présent la qualité des sources d’information afin de générer la meilleure réponse à retourner à l’utilisateur.
Pour une productrice ou un artiste, il est beaucoup plus stratégique de faire de son site web une source primaire, en attribuant une page spécifique à la description de chaque œuvre, que de créer un article sur Wikipédia. Rappelons que Wikipédia n’est pas une source primaire pour les moteurs de recherche. De plus, l’usage du vocabulaire (Schema.org) ne leur fournit qu’un signal faible sur la nature d’une offre.
Un savoir commun, entre information et informatique
L’adaptation des contenus culturels à l’environnement numérique repose, avant tout, sur de meilleurs sites web. Ces espaces offrent les conditions optimales d’autonomie, repérabilité, accessibilité et interopérabilité. Leur modernisation requiert des acteurs clés, que sont les spécialistes du Web, une mise à niveau rapide de leurs connaissances et de leurs pratiques.
Finalement, afin d’opérer cette mise à niveau et de développer ces savoirs communs, il faut bien entendu insister sur l’interdisciplinarité entre les métiers du web et, notamment, le domaine des sciences de l’information.

Découvrabilité: des métadonnées, oui, mais dans quel but?

Retour sur des notes prises en lisant des propositions de projets numériques.
À la recherche de la stratégie perdue
L’absence de réflexion stratégique est le talon d’Achille de la plupart des propositions de projets et de plans de découvrabilité. Pourtant, qu’il s’agisse de baliser des types de contenu à l’intention des moteurs de recherche ou de décrire des ressources dans un catalogue en ligne, la production de métadonnées utiles s’appuie sur la connaissance des publics cibles et des résultats recherchés.
La meilleure façon d’évaluer le résultat des efforts déployés pour qu’une offre ou un contenu rejoigne ses publics est de fixer des objectifs mesurables et réalistes. Et pour cela, il faut avoir élaboré une stratégie basée sur la connaissance du marché, des opportunités et des contraintes propres à l’organisation.
Les connexions entre votre offre et ses publics cibles
Les algorithmes des plateformes évoluent vers une personnalisation accrue des réponses qu’elles proposent en s’appuyant sur les profils de leurs utilisateurs. Nos sites web devraient faire de même en fournissant des éléments d’information qui « parlent » aux publics cibles et qui, conséquemment, facilitent le travail des moteurs de recherche.
Petit rappel: nous découvrons de l’information sur l’interface d’un moteur de recherche, mais c’est celui-ci qui la trouve. Et cela, en fonction d’un traitement algorithmique fondé sur :
- la popularité (ou l’autorité) des contenus;
- leur similarité avec le profil et l’historique de navigation de l’utilisateur.
Avant de tout miser sur des métadonnées
Voici quelques éléments clés sur lesquels réfléchir avant de déterminer les activités à réaliser dans le cadre d’un plan de découvrabilité:
- Peu importe les activités évoquées par le terme, la découvrabilité n’est mesurable qu’à l’aide des objectifs déterminés par la stratégie. Pas de stratégie: pas d’objectifs donc pas d’évaluation des résultats. Et cela s’applique autant à une stratégie de promotion qu’à des initiatives de mutualisation de données et de modélisation de connaissances pour le web sémantique.
- Les moteurs de recherche ne sont que l’un des vecteurs de la découverte. Celle-ci n’advient pas que par l’entremise de machines car la recommandation est encore largement sociale — réseaux sociaux, réseaux professionnels et académiques, bibliothécaires, libraires, médias et publications spécialisées. Les métadonnées ne sont que l’un des moyens à mettre en œuvre, au même titre qu’une page Facebook ou une chaîne YouTube, au service d’une stratégie.
- Se contenter d’intégrer des balises ne permet pas aux moteurs de recherche de fournir aux utilisateurs les réponses correspondant le plus à leurs profils ni de différencier une offre au sein d’une même catégorie, comme des événements, par exemple.
- Les deux cotés d’une même page :
- Métadonnées dans le code HTML: les modèles Schema.org permettent aux moteurs de recherche de catégoriser des types de contenu.
- Données dans le contenu d’une page web: certains éléments d’information repérables, tels que des entités nommées et des mots clés, facilitent la contextualisation et la personnalisation des résultats de recherche.
- Il faut se tenir bien informé de l’évolution du moteur de recherche et de ses consignes d’utilisation avant d’indexer des offres avec Schema.org. Les objectifs de Google varient dans le temps, selon les types de contenu et selon les ententes qu’il conclut avec certaines grandes sources de données, comme par exemple, des plateformes musicales.
- Un site web qui fournit de l’information structurée pour des machines et qui contribue à un écosystème de liens utiles pour des humains est un excellent investissement stratégique.
- Tous les acteurs de l’écosystème numérique d’une offre culturelle contribuent au rayonnement de celle-ci par l’information offerte sur leurs sites web . Ceux-ci participent également au déploiement d’un réseau d’hyperliens fournissant des données contextuelles aux moteurs de recherche et des parcours de découverte aux humains.
- Un bon plan de découvrabilité résulte d’une connaissance des publics cibles et de l’utilisation réfléchie et coordonnée de différents outils: référencement, modèles Schema.org, contributions à Wikipédia et Wikidata, publications sur des réseaux sociaux, campagnes de promotion et publicité.
Il n’existe pas de recette gagnante: une stratégie de visibilité et de rayonnement est spécifique à chaque projet. Le succès d’un plan découvrabilité dépend de choix qui sont alignés sur cette stratégie afin de publier la bonne information, dans le bon format, au bon endroit et pour le bon public.

Comment faire un plan de « découvrabilité » pour des résultats mesurables

Depuis peu, en culture, on retrouve un volet « découvrabilité » dans la plupart des appels à projets. S’agit-il d’une application technologique, de techniques de référencement ou d’une campagne de promotion numérique? L’absence d’explications concrètes et de description des compétences requises met les demandeurs (ainsi que les bailleurs de fonds!) dans une situation où ils ne disposent pas des guides nécessaires pour savoir ce qu’il faut faire, ni quels résultats escompter.
Un projet dans un projet
Assurer la repérabilité d’une nouvelle création ou d’une nouvelle offre est un projet à part entière, avec ses ressources, ses objectifs et ses réalisations. Il ne s’agit pas de mettre en commun ce que chacun aura produit de son côté, mais de produire des contributions s’alimentant les unes des autres. C’est pourquoi, dans nos velléités de transformation numérique, le travail en silo est un frein à la réussite de nos projets.
Les mots qui font des connexions
C’est l’information fournie à propos des choses qui est repérable — pas les choses en elles-mêmes. Cette distinction est extrêmement importante puisque c’est le choix des éléments descriptifs qui retient l’attention d’audiences cibles et qui permet aux moteurs de recherche de connecter des offres à des intentions et des profils d’utilisateurs.
Sous le couvert nébuleux de la découvrabilité, il existe en réalité des pratiques et des standards permettant de structurer l’information pour le Web afin d’en assurer la repérabilité, l’accessibilité et l’interopérabilité.
Google ne parle pas web sémantique
Représenter des connaissances avec les technologies du web sémantique (URI, RDF…) et structurer de l’information pour des moteurs de recherche sont des projets différents qui n’ont pas les mêmes finalités.
Si votre objectif est de faire découvrir votre offre culturelle en vous servant, entre autres, des moteurs de recherche pour générer des visites, des visionnements ou des achats, le web sémantique ne vous sera d’aucune utilité!
Google n’exploite que le langage de balisage Schema.org…
Pour un plan de découvrabilité plus efficace
Voici les éléments de réflexion qui apporteront plus d’efficacité à votre plan de découvrabilité. La grande lacune de la plupart des plans de découvrabilité est l’absence ou la faiblesse de la stratégie — comment pousser les bons contenus aux bons publics, sur les bons canaux, pour atteindre des objectifs mesurables. Or, ce travail est essentiel à plusieurs titres:
1 – Connaître les publics et fixer des objectifs
À quels besoins et à quels publics votre offre est-elle susceptible de répondre? Les objectifs à atteindre doivent être déterminés en fonction des intérêts et comportements de ces publics cibles ainsi que de leurs possibles relations à l’offre.
2 – Différencier votre offre
Le vocabulaire Schema.org permet de fournir une description détaillée d’une offre culturelle. Google n’en utilise cependant que certains éléments. Baliser une offre de spectacle n’est pas suffisant pour permettre à celle-ci de se différencier de milliers d’autres offres. La connaissance des publics fournit les éléments d’information et le vocabulaire pouvant aider les moteurs de recherche à faire des connexions entre les intentions et profils des utilisateurs et les offres disponibles.
3 – Faire travailler des spécialistes ensemble
Les balises et le référencement par mots clés sont des outils complémentaires s’appuyant sur la stratégie de promotion. Accroître la découverte commence par la présentation de l’offre sur le site web . Ceci a pour but de faciliter le travail des moteurs de recherche et d’améliorer l’expérience de l’utilisateur avec leur interfaces.
4 – Relier les acteurs de l’écosystème
Si un site web est absolument essentiel et stratégique, d’autres présences numériques contribuent au rayonnement d’une offre. Une bonne stratégie met donc à contribution les acteurs de l’écosystème en identifiant des points d’entrée (réseau social, vidéo, site partenaire, etc.) et en multipliant ainsi les parcours de découverte.
5 – Ne pas compter uniquement sur Google
En se contentant de produire des métadonnées sous forme de balises Schema.org, on se conforme aux modèles et directives qui répondent avant tout aux objectifs d’affaires d’un géant du numérique. Bien que le balisage d’offres pour les moteurs de recherche fasse partie des bonnes pratiques web, Google ne garantit aucun résultat (longue lecture, mais excellent billet).
Attention: les métadonnées ne sont pas toujours utiles. Si vous souhaitez améliorer la valeur de votre site pour Google, corrigez les lacunes de conception et améliorez la valeur du contenu rédactionnel.
6 – Mesurer l’atteinte des objectifs
Finalement, la découverte d’offres culturelles sur un moteur de recherche est difficilement mesurable. Elle dépend de plusieurs facteurs extrêmement variables, comme le profil, l’intention présumée par l’algorithme et les usages antérieurs de chaque utilisateur. Ce sont donc les objectifs et indicateurs de mesure ayant été déterminés dans le plan stratégique qui permettront d’évaluer la réussite de celui-ci.
Utiliser des métadonnées sans tomber dans le solutionnisme
Ce ne sont pas les métadonnées qui produisent des résultats, mais les moyens déterminés par la stratégie. Il faut donc proposer des initiatives plus marquantes pour la diffusion et l’appréciation de nos offres culturelles. Par exemple, renouveler l’expérience de recherche sur un site en présentant l’information sous forme de fiches, de façon similaire à Google, mais selon d’autres règles que la popularité et la similarité.
Il n’existe pas de recette. Chaque projet étant unique, il doit se différencier pour se démarquer, et ce grâce au choix des canaux, plateformes, mots, images et liens adressés aux bons publics.
Surtout, il ne faut pas se contenter d’appliquer les consignes de Google. On doit également chercher à comprendre l’interaction complexe des systèmes et identifier les éléments stratégiques que nous pouvons contrôler.
Enfin, nous ne pouvons pas encourager le milieu culturel à se conformer à un système dont nous ne comprenons pas le fonctionnement et dénoncer, dans le même temps, la domination et l’opacité des GAFAM. Cette contradiction en dit long sur les connaissances qu’il nous reste à acquérir…
Comment rendre votre information repérable, accessible et interopérable
Ce billet s’inscrit dans la ligne du précédent, qui appelait à remplacer le terme fourre-tout de découvrabilité par les objectifs, beaucoup plus concrets, de repérabilité, accessibilité et interopérabilité.
Source de la référence: ce billet de Bill Slawski.
Nos sites web sont des ensembles d’informations structurées pouvant être repérées, consultées, utilisées et interconnectées sur la grande plateforme ouverte qu’est le Web. C’est pour cette raison que les nôtres sont au cœur de la découverte de contenus et d’offres diverses. Nous devrions consacrer prioritairement nos efforts à les moderniser. Parce qu’aujourd’hui, tout part de là.
Objectif: aider les moteurs à repérer et lier des entités
Les moteurs de recherche indexent le contenu des pages web. Grâce au développement de bases de connaissances structurées (Knowledge Graph), ceux-ci peuvent repérer dans chaque page des choses ayant une signification spécifique, comme des personnes, des lieux, des événements ou des œuvres. Ces choses sont appelées « entités nommées ». Les entités nommées qui sont repérées sont catégorisées et associées selon le modèle d’organisation propre à chacune des bases de connaissances des moteurs de recherche.
Nos sites web, lorsqu’ils sont bien conçus, alimentent ces bases de connaissances. C’est pour cette raison qu’il faut prioriser l’amélioration de la repérabilité des contenus sur nos sites avant de verser des données dans Wikidata. Cette base de connaissances, tout comme d’autres, sert à réduire l’ambiguïté entre des entités (homonymes) et à valider les liens entre elles. Elle ne remplace cependant pas les sources d’information interconnectées, classifiées et référencées que sont les sites web.
Stratégie: quoi, pour qui, avec quels objectifs?
L’amélioration des conditions de repérabilité de l’information ne produit pas de résultat immédiat, contrairement aux tactiques de référencement organique de pages. Elle s’inscrit dans la durée et doit s’appuyer sur des notions précises plutôt que sur des mythes.
La réflexion stratégique permet de déterminer les objectifs à atteindre, les questions auxquelles les données doivent répondre, les publics cibles et les caractéristiques des offres à mettre de l’avant. Les objectifs vérifiables et mesurables de la « découvrabilité » sont les indicateurs de succès qui ont été déterminés en amont dans la stratégie numérique.
Responsabilités: qui fait quoi?
Comme je l’ai déjà mentionné dans un autre billet, nous ne devons plus concevoir des sites web comme des documents, mais comme des plateformes de données. Il faut nous affranchir d’un modèle de conception hérité du document imprimé afin de concevoir le site en commençant par les modèles de données plutôt que par les modèles de pages. Viennent ensuite la définition des structures représentant le ou les domaine de connaissance, puis la représentation des types d’entités sous forme de nœuds et de liens pour former, finalement, des graphes. Tout ceci nous oblige à revoir la méthodologie de conception de sites et à faire appel à des compétences qui sont rarement sollicitées pour des projets web.
Il ne s’agit pas uniquement de savoir comment intégrer ce processus dans les activités d’un projet, mais aussi de savoir ce qui doit être fait à l’interne et ce qui doit, par contre, être confié à des spécialistes.
Il n’existe pas de recette toute faite, ni d’application, pour améliorer ainsi l’organisation de l’information. L’élaboration d’un modèle de données représentant différentes entités et les relations qui les définissent est un travail de spécialiste. De plus, la spécificité des offres, objectifs stratégiques, publics cibles et environnements technologiques soulèvent des questions auxquelles une présentation de 3 heures ne permet pas de fournir de réponses solides.
Trois étapes essentielles pour rendre l’information plus repérable et découvrable
J’utilise des outils simples pour accompagner des équipes dans leurs démarches d’amélioration de sites web et de description de contenus avec des données structurées. Cependant, les projets n’avanceraient pas si ces équipes étaient livrées à elles-même, sans ressources pour répondre aux nombreuses questions que la démarche permet de soulever.
Comment améliorer la découvrabilité de contenus culturels sur un site web? Les principes d’organisation et de rédaction des sujets des pages d’un site contribuent à la visibilité des contenus dans les résultats des moteurs recherche. Voici trois étapes essentielles d’une méthode conception web pour une information plus repérable et découvrable:
1. Organiser le site web autour des entités
L’organisation du site et la structure de l’information concernent les pages web lisibles par des humains et indexables par des machines (voir Structurer l’information autour d’entités repérables) et le code informatique de ces pages qui est interprétable par des machines (lire Schema.org n’est pas le moteur de recherche).
Vous pouvez évaluer en quelques points si la structure et le contenu des pages de votre site fournissent aux éléments d’information (entités nommées, métadonnées, mots clés) les meilleures conditions d’exploitation, pour des visiteurs et pour des moteurs de recherche.
- Arborescence (accès aux offres et contenus).
- Nomenclature (alignement de la taxonomie sur les publics cibles).
- URL unique et lisible pour chaque offre et contenu.
- Images (nomenclature de fichier, texte alternatif, résolutions).
- Description (caractéristiques, attributs distinctifs, expérience).
- Information à valeur ajoutée (liens vers d’autres sources d’information complémentaire).
2. Faire « du lien »
Comment évaluer le potentiel de rayonnement de vos contenus dans le numérique?
- En cartographiant l’écosystème composé de points et de liens qui jouent un rôle central dans leur visibilité et découverte.
- En identifiant les points (site web, réseaux sociaux, sites de partenaires) permettant d’établir des connexions pertinentes vers vos offres.
Vous reporterez ensuite, dans une grille, les points ainsi identifiés, puis dresser l’inventaire détaillé de l’information diffusée, de la fréquence des publications, des rôles et responsabilités de chacun. Vous serez alors en mesure de:
- Déterminer les points permettant de rejoindre différents publics (en d’autres termes, associer les bons canaux et contenus aux bons publics).
- Identifier les liens à créer ou à solidifier ainsi que les partenariats à développer.
3. Décrire les entités
Cette grille permettra d’identifier les métadonnées qui rendent vos offres et contenus uniques et plus faciles à trouver. Vous pouvez à la fois:
- Trouver les mots pour différencier votre offre auprès de vos publics cibles.
- Fournir des métadonnées permettant aux moteurs de recherche de fournir des réponses personnalisées.
Ces activités devraient être réalisées en groupe, au sein d’une organisation ou, lorsqu’il s’agit d’une initiative collective, avec les représentants de différentes organisations.

{kind=link}
Découvertes culturelles: au-delà du marketing et du techno-solutionnisme

Notre focalisation sur le marketing et les solutions technologiques est-elle un risque pour la diversité culturelle ? L’absence de vision partagée et la course aux résultats peuvent-elles faire perdre aux acteurs de la culture la maîtrise stratégique des choix en matière de diffusion et d’accès ?
Nous espérons des solutions mécanistes qui accroîtront la consommation en imposant des offres culturelles à la façon des vieux modèles publicitaires. La mise en données de contenus culturels ne doit pas nous faire oublier qu’il appartient à chacun de réaliser la partie la plus stratégique d’un projet numérique : décider de la façon dont une chose (une œuvre, par exemple) doit être documentée et déterminer ce qui la relie à d’autres informations dans le web des données.
L’emploi du mot « initiative », de préférence à « projet », souligne l’importance de la démarche et des apprentissages, par rapport à la livraison d’un outil ou la modernisation d’un système. Voici comment nos initiatives pourraient être plus marquantes.
Miser sur l’éducation et l’accès à la culture
Le marketing peut entraîner la consommation de produits et services culturels, mais ce sont l’éducation et l’accès à la culture qui peuvent faire découvrir et apprécier la culture. Or, il faudrait une plus grande porosité entre les politiques et projets éducatifs et culturels pour miser sur l’environnement familial et social pour faire connaître la culture.
Il faudrait également donner un rôle plus actif, dans nos plans et initiatives numériques, aux médiateurs de proximité que sont les professionnels des bibliothèques publiques et scolaires.
Privilégier les initiatives qui favorisent la diversité
Nous cherchons, par tous les moyens, à ce que la culture locale soit vue et consommée, de préférence à d’autres offres. Nos propositions techniques partagent cependant les défauts des plateformes dominantes. Qu’il s’agisse de baliser des contenus pour les moteurs de recherche ou de créer de nouvelles bases de données interrogeables, la façon dont sont conçues ces « solutions » technologiques nuit à la diversité des offres culturelles.
- La centralisation des décisions et du traitement de l’information renforce l’uniformisation.
- La popularité comme principal critère de sélection défavorise les contenus de niche, les cultures et langues en situation minoritaire dans un répertoire, sur un territoire ou par rapport au reste du monde.
- L’uniformisation du traitement documentaire, par l’imposition d’une méthode de classification, de vocabulaires et de référentiels spécifiques, appauvrit la qualité de l’information. Par conséquent, elle en diminue l’intérêt et la valeur pour différents publics. Les initiatives de décolonisation des modèles descriptifs tentent de réparer les ravages du rouleau compresseur de l’uniformisation sur la citoyenneté culturelle des peuples autochtones.
- Les systèmes de recommandations et de personnalisation des offres culturelles reposent sur la similarité des produits et services ou sur la similarité des profils des utilisateurs.
Ne pas céder des choix stratégiques
À l’arrivée de l’informatique, nous avons confié l’organisation de l’information à des systèmes de bases de données, selon les termes d’entreprises. Il est temps de remettre, selon nos propres termes, cette intelligence dans nos sites web et, plus spécifiquement, dans nos catalogues, collections, répertoires, fonds et archives. Nous ne devrions pas abandonner la création de sens et de liens à des opérateurs de plateformes et à des fournisseurs de services.
Être trouvé ou découvert et laisser des traces numériques sont les fruits d’un travail de documentation. Celui-ci est trop souvent escamoté par la recherche d’une solution technologique. De plus, les façons de décrire des productions ou des offres culturelles offrent peu de possibilité de mettre celles-ci en relation avec des intérêts et des passions.
Par exemple, les catalogues et répertoires en ligne pourraient grandement améliorer l’expérience des utilisateurs en devenant des bases de connaissances interactives et interconnectées. Il serait ainsi possible d’intégrer de nouvelles informations et des liens vers d’autres ressources grâce aux contributions de chercheurs et d’amateurs.
Documenter: laisser des traces, créer du lien et faire sa marque
Documenter la culture et rendre cette information pertinente, attrayante et utile pour divers publics et usages sont la responsabilité de tous les acteurs du milieu culturel. Il manque une méthode de travail et des outils faciles à utiliser pour réaliser, en équipe ou avec des partenaires, l’évaluation de l’information publiée sur le web et le choix des métadonnées qui feront des liens entre les offres culturelles et les publics cibles.
C’est dans cette perspective qu’a été conçu un guide destiné aux artistes et aux organisations du milieu de la danse. Cette approche, en trois étapes (stratégie, information, technologie) repousse les choix technologiques à la toute dernière étape afin de remettre la documentation de la danse à ceux et celles qui la font.
Extraits du lancement du guide Bien documenter pour favoriser la découverte en ligne, réalisé pour la Fondation Jean-Pierre Perreault, dans le cadre de l’initiative La danse dans le web des données.