Quelle est la probabilité que des données ouvertes et liées fassent découvrir une chose qu’on ne connaît ou ne cherche pas? Le potentiel de découvrabilité d’une offre culturelle sous forme de données avec les technologies du Web sémantique est très faible. Pourtant, l’Appel de projets pour le développement culturel numérique dans la francophonie canadienne privilégie la « production et la diffusion la plus large possible de métadonnées (idéalement sous forme de données ouvertes et liées) ». Les arguments qui soutiennent cette orientation gagneraient à être partagés et discutés au sein de comités scientifiques et techniques.
Continuer la lecture de Quel est le potentiel de découvrabilité des données ouvertes et liées?Archives par mot-clé : référencement
Wikidata: pour Google ou pour le Web des données?
Wikidata améliore-t-il la découvrabilité sur Google? Non.
Contrairement à une hypothèse que j’ai parfois évoquée il y a plusieurs années, puis maintes fois remise en cause, Wikidata n’est pas une solution de découvrabilité sur Google. C’est l’une des bases de connaissances permettant de valider une entité, et non de fournir une réponse. Ce n’est pas un moyen de promouvoir une information pour quiconque interroge Google, et encore moins pour qui ne la cherche pas.
Verser des données dans Wikidata ne rend donc pas un objet culturel plus visible ou découvrable parmi les résultats du moteur de recherche. Cependant, c’est une initiative à fort potentiel de créativité et de transformation numérique si l’on poursuit un tout autre but que la promotion d’une offre, soit la réutilisation de données interopérables et interconnectables, partout sur la planète.
Wikidata pour le Web des données
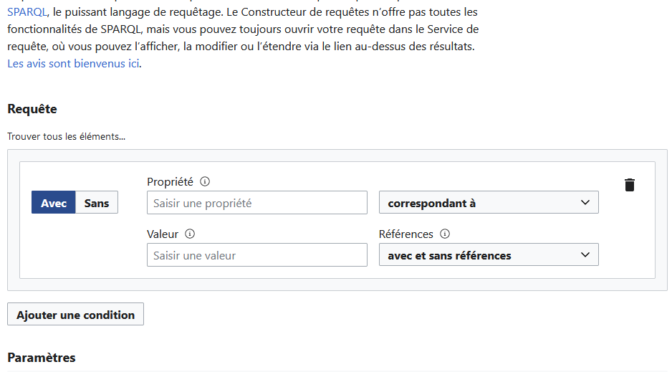
Par contre, comme je l’ai précisé dans un billet sur le choix d’un environnement technologique, contribuer à Wikidata peut favoriser la découverte de données sur cette plateforme. La maîtrise du langage d’interrogation SPARQL est cependant une courbe d’apprentissage plutôt abrupte pour les non-spécialistes. Même l’assistant de recherche est inaccessible pour qui n’a pas l’habitude de composer des requêtes destinées à des bases de données.
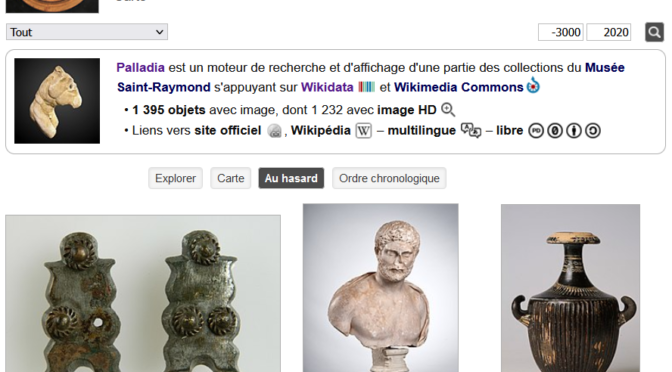
Les organisations versant leurs données dans Wikidata devraient offrir, sur leurs propres sites, des interfaces de recherche avec des requêtes pré-construites. L’exemple présenté ci-dessous est un projet réalisé par le Musée de Saint-Raymond à Toulouse (France) en partenariat avec Wikimedia France.
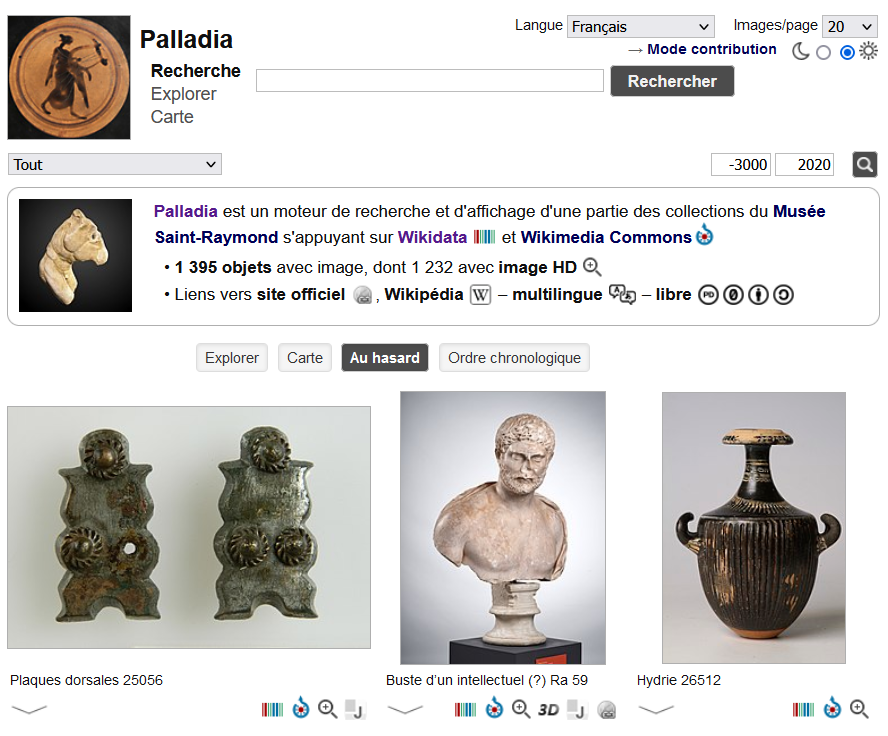
Pour s’en inspirer davantage, voici l’historique des projets Crotos et Palladia sur WikiArchives, avec un lien complémentaire vers un billet de Marie D. Martel datant de 2017 mais qui demeure tout à fait pertinent: #wikimania Le modèle d’une pratique professionnelle alternative à bâtir avec les GLAMs.
Cette réutilisation des données dans les deux sens — dans l’environnement ouvert et collaboratif de Wikidata et dans la perspective spécifique d’une institution — présente de précieux avantages:
Impulsion d’une véritable transformation
Un projet de données ouvertes et liées peut contribuer à la transformation d’une organisation dans un contexte numérique. Il ne s’agit pas d’informatisation, mais d’un projet fédérateur qui peut transformer les rapports à l’information et à la communication. Si c’est un choc culturel pour certaines institutions, c’est potentiellement un environnement d’apprentissage et, au final, une véritable transformation numérique pour toute forme d’organisation.
Modernisation d’un système de gestion documentaire
Des données liées offrent un énorme potentiel de découverte et de connaissance car elles ne sont pas figées dans un modèle où les relations sont prédéfinies. Ceci accorde à une base de données en graphe (appelée aussi graphe de données liées) la capacité d’effectuer du raisonnement, ce que la technologie des bases de données classiques n’offre pas.
Contournement des défis du Web sémantique
Wikidata réduit considérablement les coûts, délais et expertises requises pour la réalisation d’un projet de données ouvertes et liées en fournissant, entre autres, la plateforme et l’ontologie. Bien plus complexe qu’un vocabulaire, une ontologie est la spécification d’une conceptualisation, à l’aide de types d’objets, de leurs propriétés et de leurs différents types de relations. C’est un exercice d’abstraction réalisé par un petit nombre de spécialistes
Interopérabilité accrue des données
L’ontologie qui permet de modéliser les données pour Wikidata n’est pas conçue pour représenter le concepts propres à chaque domaine de connaissance. C’est un avantage: alors qu’une base de données classique est conçue pour répondre aux besoins et usages d’un domaine ou discipline, Wikidata ne cloisonne pas la connaissance et favorise, de ce fait, les interconnexions.
Petit rappel
Une base de données classique et un graphe de données liées ne sont pas exploitables pour les moteurs de recherche comme Google.
Deux grands défis d’un projet de données
Un projet de données liées comporte des défis qui doivent impérativement être identifiés et analysés en amont de toute conception ou acquisition de technologie. Voici deux de ces défis:
Expérience de recherche
Des données liées doivent permettre d’offrir des fonctions de recherche différentes de (et supérieures à) celles d’une base de données classique.
Une recherche par auteur, titre et sujet n’apportera pas de nouvelles connaissances. Les critères d’une recherche avancée ne sont pas de bons moyens pour faire découvrir une collection à qui ne cherche rien en particulier.
Mobilisation des utilisateurs(trices)
Changer le comportement de personnes qui accèdent à de l’information en posant simplement une question (Google, ChatGPT) ou de façon passive (flux des réseaux sociaux) est très certainement l’un des plus grands défis des nouvelles base de données en ligne.
Comment faire d’un site une destination préférée pour chercher ou découvrir de l’information? Hélas, nombreux sont les projets qui ne reposent que sur une campagne de promotion pour modifier des habitudes devenues des réflexes.
Wikidata: oui, mais pour des résultats concrets
Le versement de données dans Wikidata ne devrait pas être promu comme une bonne pratique de référencement web et de découvrabilité sur Google.
Cependant, un projet avec Wikidata peut faire converger deux buts: développer une culture de la donnée et amorcer une véritable transformation numérique impliquant de nouveaux modes d’organisation et de collaboration.
Comment améliorer la découvrabilité sur Google?
Pour améliorer la découvrabilité sur Google, mieux vaut utiliser les données là où elles sont vraiment utiles et comprendre les différents types de résultats présentés par le moteur de recherche. En effet, de nouvelles fonctionnalités transforment peu à peu la liste de liens classiques en une interface qui fournit des réponses et des suggestions pour amener les internautes à préciser leurs intentions.
Continuer la lecture de Comment améliorer la découvrabilité sur Google?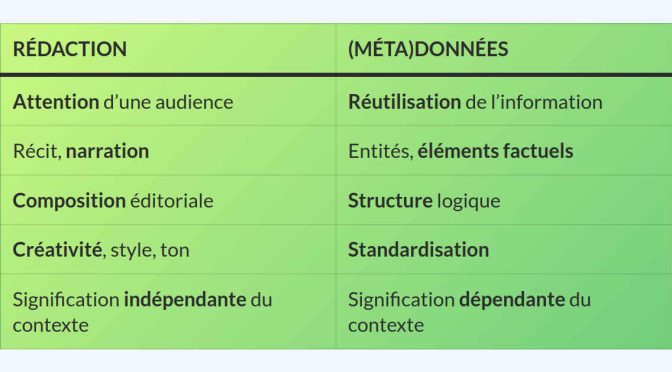
Découvrabilité: les données et métadonnées sont-elles toujours utiles?
De façon générale, les initiatives visant à promouvoir une offre culturelle afin de favoriser sa « découvrabilité » concernent les moteurs de recherche comme Google ou des plateformes en ligne, existantes ou à concevoir. Ce sont cependant deux types de projets différents pour lesquels le type d’information à produire détermine des activités, compétences et ressources nécessaires différentes.
Continuer la lecture de Découvrabilité: les données et métadonnées sont-elles toujours utiles?
Les données ne sont pas la panacée de la découvrabilité

Orienter toute initiative de découvrabilité vers la production de données relève de la pensée magique selon laquelle la technologie est la solution à toute problématique, aussi systémique et complexe soit-elle.
Continuer la lecture de Les données ne sont pas la panacée de la découvrabilité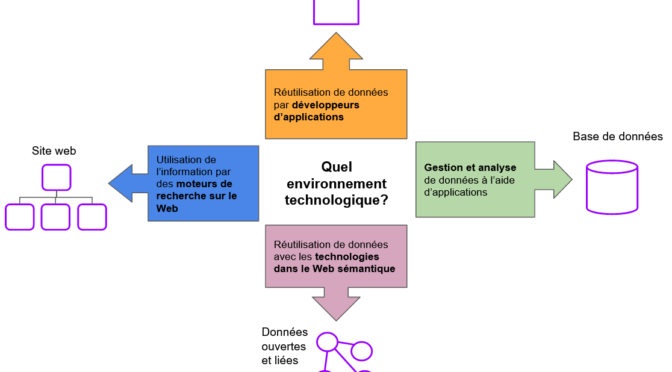
Découvrabilité: oui, mais dans quel environnement technologique?
Favoriser la découverte d’une offre pour atteindre un objectif c’est bien, mais dans quel environnement technologique? La réponse à cette question, rarement abordée, pourrait pourtant aiguiller certains projets ciblant les moteurs de recherche vers de meilleures pratiques de conception et de rédaction pour le Web plutôt que vers la création de métadonnées.
Continuer la lecture de Découvrabilité: oui, mais dans quel environnement technologique?
De données structurées à contenu structuré
Je le répète: il faut retomber en amour avec nos sites web. Nous devons réinvestir le domaine du langage sur ces espaces numériques privilégiés que sont nos sites web.
Continuer la lecture de De données structurées à contenu structuré
L’angle mort de la promotion de l’offre culturelle sur le Web
![Planche dPlanche de l’Encyclopédie de Diderot et d’Alembert: taille de la plume pour l’écriture. Morburre, [CC BY-SA 3.0], Wikimedia Commonse l’Encyclopédie de Diderot et d’Alembert: Taille de la plume pour l’écriture.](https://fr.wikipedia.org/wiki/Fichier:Ecriture-TaillePlume-Encyclopedie.jpg)
Or, ce ne sont plus les balises Schema.org insérées dans le code ni les articles de Wikipédia qui facilitent le travail des moteurs de recherche en les rendant intelligents. C’est, à présent, le traitement automatique du langage naturel. Celui-ci permet aux algorithmes d’évaluer l’information présente sur une page web et lisible par les humains.
Plus l’information offerte par le texte est riche et contextualisée par des liens vers d’autres pages web, plus elle a de valeur pour nous et, par conséquent, pour les moteurs de recherche dont l’objectif est de nous offrir les meilleurs résultats possibles.
Un travail de spécialistes
Après quelques années d’accompagnement d’entrepreneurs culturels, je peux affirmer que rares sont les non-initiés sachant manier avec aisance des notions et des mécanismes qui demeurent complexes, même pour des spécialistes du Web. Ce billet sur les définitions divergentes de ce qu’est une ontologie permet de mesurer le défi d’établir une compréhension commune et claire d’une notion pourtant fondamentale des systèmes documentaires. Et pour celles et ceux qui persévèrent, les concepts et pratiques nouvellement acquis sont trop éloignés de leurs activités pour qu’ils soient en mesure de les intégrer aux opérations et de se livrer à la veille technique qui s’impose en permanence.
Structurer de l’information pour une variété d’usages et de systèmes, c’est un travail de spécialistes. Le rôle de créateurs de contenu consiste à documenter cette information et à raconter comment elle s’insère dans notre monde. Ils peuvent se faire aider afin de produire l’information répondant le mieux aux intérêts des publics cibles et de fournir des liens nécessaires aux humains et aux machines pour apporter du contexte, favorisant ainsi la découverte.
Voici les étapes qu’il faudrait suivre afin d’améliorer la valeur informative de la page web consacrée à une offre culturelle:
1- Stratégie: quelle information, à quels publics, pour quels résultats
Mieux un contenu est documenté, plus il est susceptible de pouvoir réponse à une question. Il est donc important de baser la conception du contenu d’une page sur une solide connaissance des publics cibles. D’où la nécessité d’une stratégie et d’une concertation entre les producteurs, diffuseurs et toutes autres parties concernées. Toutefois, l’élaboration d’une stratégie de ce type requiert une formation préalable mobilisant divers spécialistes.
2- Documentation: les choses et les relations entre ces choses
L’adaptation de nos contenus culturels à l’environnement numérique commence par l’écriture. Tous les éditeurs de sites web doivent à présent mieux organiser et documenter leurs contenus pour les rendre plus repérables. Pour Google, « documenter » signifie: bien décrire un contenu et fournir du contexte en faisant des liens entre des concepts. Plus la documentation est exhaustive et clairement libellée, plus elle a de la valeur pour les utilisateurs — et plus la page web de l’offre culturelle devient une source d’information de qualité.
3- Balises: signaler certains types de contenus
Certains types de contenus — comme les vidéos, par exemple — peuvent apparaître sous forme d’extraits, dans la liste de résultats de Google (résultats enrichis). L’utilisation de balises permettant de catégoriser des contenus n’est donc pertinente que pour un petit nombre d’offres. Les modèles descriptifs recommandés sont ceux qui concernent les projets de développement des services du moteur de recherche. De plus, les consignes à suivre évoluent en fonction du résultat des expérimentations et de l’avancement du traitement automatique du langage.
Nous devons, alors, éviter de développer des fonctionnalités qui deviennent rapidement obsolètes ou, pire, qui réduisent notre capacité d’innovation en l’encadrant dans la logique d’affaires d’une plateforme. Il faut donc que nous demeurions extrêmement vigilants afin que nos projets nous apportent une réelle valeur et ne tombent pas dans le solutionnisme technologique.
4- Wikipédia: création d’article utile, mais non essentielle
Wikipédia facilite l’identification d’un concept ou objet spécifique, mais ce sont les pages web qui sont les sources primaires pour Google. Contrairement à la croyance courante, la production d’une fiche de réponse (appelée « knowledge panel ») résulte du traitement du contenu provenant de différentes pages web. Celles-ci sont qualifiées par le moteur de recherche pour l’information qu’elles offrent. En analysant certains brevets déposés par Google, on peut déduire que son utilisation de l’encyclopédie n’est ni constante, ni déterminante. Créer un article Wikipédia n’est donc pas une activité essentielle dans un plan de découvrabilité, même si cela peut accroître la notoriété d’un sujet lorsqu’il contient des connaissances utiles et des liens vers d’autres articles.
L’écriture: une « solution » à la portée de tous!
Adapter nos contenus culturels à l’environnement numérique commence donc par une technique millénaire: l’écriture. Nous pourrions beaucoup mieux documenter nos offres culturelles sur nos sites web sans nécessairement plonger dans des domaines de connaissance complexes. Il suffit d’apprendre à décrire des choses et les relations entre ces choses pour des systèmes qui, eux-même, apprennent à lire afin de fournir la meilleure information à leurs utilisateurs. Bref, avant de se lancer dans la modélisation de données ou le web sémantique, il serait temps de revenir aux stratégies de communication, ainsi qu’aux bonnes pratiques de rédaction web.
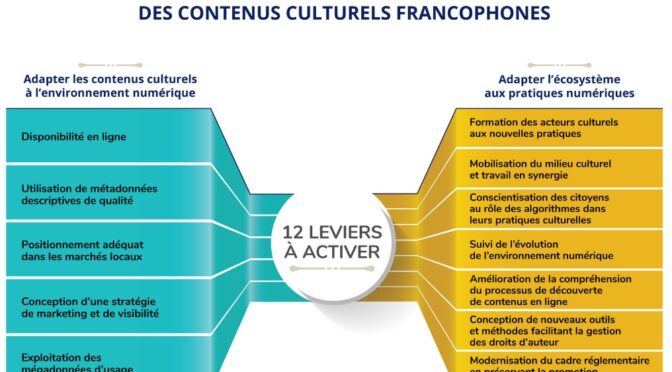
Deux leviers à ajouter au rapport de la mission franco-québécoise sur la découvrabilité
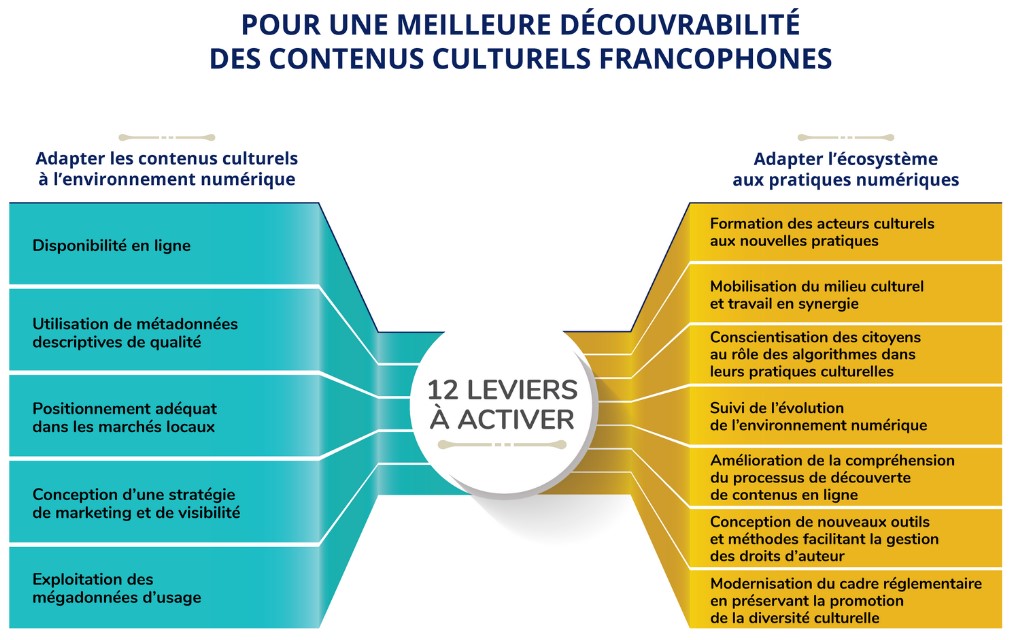
Le rapport sur la découvrabilité en ligne des contenus culturels francophones résulte d’une mission conjointe des ministères de la Culture du Québec et de la France. Il dresse un bon état des lieux d’un ensemble de phénomènes et d’actions, sans égarer le lecteur dans les détails techniques. Un excellent exercice de synthèse, donc, réalisé par Danielle Desjardins, auteure de plusieurs rapports pour le secteur culturel et collaboratrice du site de veille du Fonds des médias du Canada.
Cependant, dans le schéma des 12 leviers à activer pour une meilleure découvrabilité des contenus culturels francophones (voir plus haut), il manque à mon avis deux éléments essentiels:
- Est-ce aux acteurs culturels que revient la charge de rendre l’information concernant leurs créations ou leurs offres numériquement opérationnelle?
- Quel espace numérique offre les meilleures conditions de repérabilité, d’accessibilité et d’interopérabilité de l’information ?
Premier levier: mises à niveau des métiers du Web
Il est important de sensibiliser les acteurs culturels à l’adoption de pratiques documentaires telles que l’indexation de ressources en ligne. Ceci dit, la mise en application des principes, ainsi que le choix de modèles de représentation de contenus en ligne, sont des compétences qui ne s’acquièrent pas comme on apprend à se servir d’un logiciel. On ne peut pas attendre de toute personne et organisation du secteur culturel de tels efforts d’apprentissage. D’autant plus que la production de l’information pour le numérique fait appel à des méthodes et savoirs relevant des domaines du langage et de la représentation des connaissances autant que des technologies numériques.
Si les données structurées sont perçues comme des solutions pouvant accroître la visibilité d’offres culturelles sur nos écrans, elles appartiennent à des domaines de pratiques pas suffisamment maîtrisés au sein des métiers du Web. C’est pourtant bien vers des spécialistes en développement, intégration, référencement et optimisation que se tournent les acteurs culturels cherchant à rendre le contenu de leurs sites web plus interprétable par des machines. Or, à ma connaissance, il n’existe actuellement pas de formation et de plan de travail tenant compte de l’interdépendance des volets sémantiques, technologiques et stratégiques du web des données.
Il devient de plus en plus impératif d’identifier les connaissances à développer ou à approfondir chez les divers spécialistes contribuant à la conception de sites web aux contenus plus repérables. Il serait également souhaitable de soutenir un réseau de veille interdisciplinaire ayant pour objectif de contextualiser et d’analyser l’évolution de l’écosystème numérique.
Exemple: dans la foulée d’une étape importante de ses capacités d’interprétation (traitement automatique du langage), Google a mis à jour, cet été, ses directives d’évaluation de la qualité de l’information. Il va sans dire que c’est important.
Deuxième levier: modernisation des sites web
Dans le Web des moteurs de recherche intelligents, la reconnaissance des entités passe par l’indexation de pages web et l’analyse des contenus. Les sites web devraient donc être des sources d’information de première qualité, tant pour les internautes que pour les moteurs de recherche.
Est-il normal de ne pas trouver toute l’information, riche et détaillée, sur le site de référence d’une entreprise culturelle? Pour le bénéfice des projets numériques, il est vital de concevoir des contenus pertinents pour les machines, lesquelles évaluent à présent la qualité des sources d’information afin de générer la meilleure réponse à retourner à l’utilisateur.
Pour une productrice ou un artiste, il est beaucoup plus stratégique de faire de son site web une source primaire, en attribuant une page spécifique à la description de chaque œuvre, que de créer un article sur Wikipédia. Rappelons que Wikipédia n’est pas une source primaire pour les moteurs de recherche. De plus, l’usage du vocabulaire (Schema.org) ne leur fournit qu’un signal faible sur la nature d’une offre.
Un savoir commun, entre information et informatique
L’adaptation des contenus culturels à l’environnement numérique repose, avant tout, sur de meilleurs sites web. Ces espaces offrent les conditions optimales d’autonomie, repérabilité, accessibilité et interopérabilité. Leur modernisation requiert des acteurs clés, que sont les spécialistes du Web, une mise à niveau rapide de leurs connaissances et de leurs pratiques.
Finalement, afin d’opérer cette mise à niveau et de développer ces savoirs communs, il faut bien entendu insister sur l’interdisciplinarité entre les métiers du web et, notamment, le domaine des sciences de l’information.

Découvrabilité: des métadonnées, oui, mais dans quel but?

Retour sur des notes prises en lisant des propositions de projets numériques.
À la recherche de la stratégie perdue
L’absence de réflexion stratégique est le talon d’Achille de la plupart des propositions de projets et de plans de découvrabilité. Pourtant, qu’il s’agisse de baliser des types de contenu à l’intention des moteurs de recherche ou de décrire des ressources dans un catalogue en ligne, la production de métadonnées utiles s’appuie sur la connaissance des publics cibles et des résultats recherchés.
La meilleure façon d’évaluer le résultat des efforts déployés pour qu’une offre ou un contenu rejoigne ses publics est de fixer des objectifs mesurables et réalistes. Et pour cela, il faut avoir élaboré une stratégie basée sur la connaissance du marché, des opportunités et des contraintes propres à l’organisation.
Les connexions entre votre offre et ses publics cibles
Les algorithmes des plateformes évoluent vers une personnalisation accrue des réponses qu’elles proposent en s’appuyant sur les profils de leurs utilisateurs. Nos sites web devraient faire de même en fournissant des éléments d’information qui « parlent » aux publics cibles et qui, conséquemment, facilitent le travail des moteurs de recherche.
Petit rappel: nous découvrons de l’information sur l’interface d’un moteur de recherche, mais c’est celui-ci qui la trouve. Et cela, en fonction d’un traitement algorithmique fondé sur :
- la popularité (ou l’autorité) des contenus;
- leur similarité avec le profil et l’historique de navigation de l’utilisateur.
Avant de tout miser sur des métadonnées
Voici quelques éléments clés sur lesquels réfléchir avant de déterminer les activités à réaliser dans le cadre d’un plan de découvrabilité:
- Peu importe les activités évoquées par le terme, la découvrabilité n’est mesurable qu’à l’aide des objectifs déterminés par la stratégie. Pas de stratégie: pas d’objectifs donc pas d’évaluation des résultats. Et cela s’applique autant à une stratégie de promotion qu’à des initiatives de mutualisation de données et de modélisation de connaissances pour le web sémantique.
- Les moteurs de recherche ne sont que l’un des vecteurs de la découverte. Celle-ci n’advient pas que par l’entremise de machines car la recommandation est encore largement sociale — réseaux sociaux, réseaux professionnels et académiques, bibliothécaires, libraires, médias et publications spécialisées. Les métadonnées ne sont que l’un des moyens à mettre en œuvre, au même titre qu’une page Facebook ou une chaîne YouTube, au service d’une stratégie.
- Se contenter d’intégrer des balises ne permet pas aux moteurs de recherche de fournir aux utilisateurs les réponses correspondant le plus à leurs profils ni de différencier une offre au sein d’une même catégorie, comme des événements, par exemple.
- Les deux cotés d’une même page :
- Métadonnées dans le code HTML: les modèles Schema.org permettent aux moteurs de recherche de catégoriser des types de contenu.
- Données dans le contenu d’une page web: certains éléments d’information repérables, tels que des entités nommées et des mots clés, facilitent la contextualisation et la personnalisation des résultats de recherche.
- Il faut se tenir bien informé de l’évolution du moteur de recherche et de ses consignes d’utilisation avant d’indexer des offres avec Schema.org. Les objectifs de Google varient dans le temps, selon les types de contenu et selon les ententes qu’il conclut avec certaines grandes sources de données, comme par exemple, des plateformes musicales.
- Un site web qui fournit de l’information structurée pour des machines et qui contribue à un écosystème de liens utiles pour des humains est un excellent investissement stratégique.
- Tous les acteurs de l’écosystème numérique d’une offre culturelle contribuent au rayonnement de celle-ci par l’information offerte sur leurs sites web . Ceux-ci participent également au déploiement d’un réseau d’hyperliens fournissant des données contextuelles aux moteurs de recherche et des parcours de découverte aux humains.
- Un bon plan de découvrabilité résulte d’une connaissance des publics cibles et de l’utilisation réfléchie et coordonnée de différents outils: référencement, modèles Schema.org, contributions à Wikipédia et Wikidata, publications sur des réseaux sociaux, campagnes de promotion et publicité.
Il n’existe pas de recette gagnante: une stratégie de visibilité et de rayonnement est spécifique à chaque projet. Le succès d’un plan découvrabilité dépend de choix qui sont alignés sur cette stratégie afin de publier la bonne information, dans le bon format, au bon endroit et pour le bon public.