Pour améliorer la découvrabilité sur Google, mieux vaut utiliser les données là où elles sont vraiment utiles et comprendre les différents types de résultats présentés par le moteur de recherche. En effet, de nouvelles fonctionnalités transforment peu à peu la liste de liens classiques en une interface qui fournit des réponses et des suggestions pour amener les internautes à préciser leurs intentions.
Continuer la lecture de Comment améliorer la découvrabilité sur Google?Archives par mot-clé : recherche

Découvrabilité: comment aiguiller des initiatives numériques vers la bonne voie

Il est temps d’apporter un peu de clarté dans le méli-mélo de concepts qui ne sont pas très bien maîtrisés. Voici une petite mise au point qui pourrait être bénéfique pour les promoteurs d’initiatives numériques, ainsi que les organisations qui les financent.
Continuer la lecture de Découvrabilité: comment aiguiller des initiatives numériques vers la bonne voie
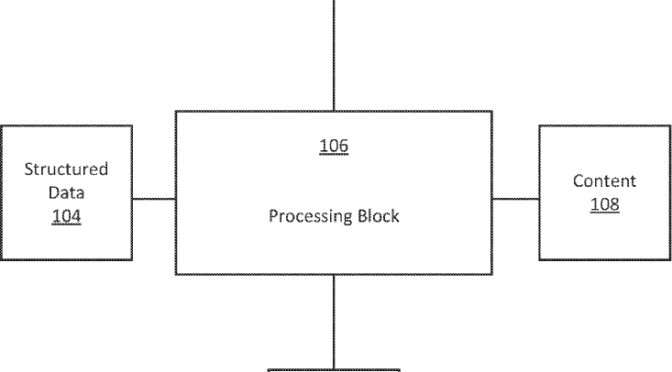
De données structurées à contenu structuré
Je le répète: il faut retomber en amour avec nos sites web. Nous devons réinvestir le domaine du langage sur ces espaces numériques privilégiés que sont nos sites web.
Continuer la lecture de De données structurées à contenu structuré
Nouveaux milieux documentaires en manque de spécialistes des sciences de l’information
En culture comme en commerce, les initiatives de mise en commun de données numériques, constituent de nouveaux « milieux documentaires ». Au Québec, pourtant, les compétences et méthodes du domaine des sciences de l’information sont rarement sollicitées. Les institutions d’enseignement et les associations professionnelles concernées devraient pourtant reconnaître, dans ces projets, les notions et enjeux entourant les systèmes documentaires classiques.
Continuer la lecture de Nouveaux milieux documentaires en manque de spécialistes des sciences de l’information
L’angle mort de la promotion de l’offre culturelle sur le Web
![Planche dPlanche de l’Encyclopédie de Diderot et d’Alembert: taille de la plume pour l’écriture. Morburre, [CC BY-SA 3.0], Wikimedia Commonse l’Encyclopédie de Diderot et d’Alembert: Taille de la plume pour l’écriture.](https://fr.wikipedia.org/wiki/Fichier:Ecriture-TaillePlume-Encyclopedie.jpg)
Or, ce ne sont plus les balises Schema.org insérées dans le code ni les articles de Wikipédia qui facilitent le travail des moteurs de recherche en les rendant intelligents. C’est, à présent, le traitement automatique du langage naturel. Celui-ci permet aux algorithmes d’évaluer l’information présente sur une page web et lisible par les humains.
Plus l’information offerte par le texte est riche et contextualisée par des liens vers d’autres pages web, plus elle a de valeur pour nous et, par conséquent, pour les moteurs de recherche dont l’objectif est de nous offrir les meilleurs résultats possibles.
Un travail de spécialistes
Après quelques années d’accompagnement d’entrepreneurs culturels, je peux affirmer que rares sont les non-initiés sachant manier avec aisance des notions et des mécanismes qui demeurent complexes, même pour des spécialistes du Web. Ce billet sur les définitions divergentes de ce qu’est une ontologie permet de mesurer le défi d’établir une compréhension commune et claire d’une notion pourtant fondamentale des systèmes documentaires. Et pour celles et ceux qui persévèrent, les concepts et pratiques nouvellement acquis sont trop éloignés de leurs activités pour qu’ils soient en mesure de les intégrer aux opérations et de se livrer à la veille technique qui s’impose en permanence.
Structurer de l’information pour une variété d’usages et de systèmes, c’est un travail de spécialistes. Le rôle de créateurs de contenu consiste à documenter cette information et à raconter comment elle s’insère dans notre monde. Ils peuvent se faire aider afin de produire l’information répondant le mieux aux intérêts des publics cibles et de fournir des liens nécessaires aux humains et aux machines pour apporter du contexte, favorisant ainsi la découverte.
Voici les étapes qu’il faudrait suivre afin d’améliorer la valeur informative de la page web consacrée à une offre culturelle:
1- Stratégie: quelle information, à quels publics, pour quels résultats
Mieux un contenu est documenté, plus il est susceptible de pouvoir réponse à une question. Il est donc important de baser la conception du contenu d’une page sur une solide connaissance des publics cibles. D’où la nécessité d’une stratégie et d’une concertation entre les producteurs, diffuseurs et toutes autres parties concernées. Toutefois, l’élaboration d’une stratégie de ce type requiert une formation préalable mobilisant divers spécialistes.
2- Documentation: les choses et les relations entre ces choses
L’adaptation de nos contenus culturels à l’environnement numérique commence par l’écriture. Tous les éditeurs de sites web doivent à présent mieux organiser et documenter leurs contenus pour les rendre plus repérables. Pour Google, « documenter » signifie: bien décrire un contenu et fournir du contexte en faisant des liens entre des concepts. Plus la documentation est exhaustive et clairement libellée, plus elle a de la valeur pour les utilisateurs — et plus la page web de l’offre culturelle devient une source d’information de qualité.
3- Balises: signaler certains types de contenus
Certains types de contenus — comme les vidéos, par exemple — peuvent apparaître sous forme d’extraits, dans la liste de résultats de Google (résultats enrichis). L’utilisation de balises permettant de catégoriser des contenus n’est donc pertinente que pour un petit nombre d’offres. Les modèles descriptifs recommandés sont ceux qui concernent les projets de développement des services du moteur de recherche. De plus, les consignes à suivre évoluent en fonction du résultat des expérimentations et de l’avancement du traitement automatique du langage.
Nous devons, alors, éviter de développer des fonctionnalités qui deviennent rapidement obsolètes ou, pire, qui réduisent notre capacité d’innovation en l’encadrant dans la logique d’affaires d’une plateforme. Il faut donc que nous demeurions extrêmement vigilants afin que nos projets nous apportent une réelle valeur et ne tombent pas dans le solutionnisme technologique.
4- Wikipédia: création d’article utile, mais non essentielle
Wikipédia facilite l’identification d’un concept ou objet spécifique, mais ce sont les pages web qui sont les sources primaires pour Google. Contrairement à la croyance courante, la production d’une fiche de réponse (appelée « knowledge panel ») résulte du traitement du contenu provenant de différentes pages web. Celles-ci sont qualifiées par le moteur de recherche pour l’information qu’elles offrent. En analysant certains brevets déposés par Google, on peut déduire que son utilisation de l’encyclopédie n’est ni constante, ni déterminante. Créer un article Wikipédia n’est donc pas une activité essentielle dans un plan de découvrabilité, même si cela peut accroître la notoriété d’un sujet lorsqu’il contient des connaissances utiles et des liens vers d’autres articles.
L’écriture: une « solution » à la portée de tous!
Adapter nos contenus culturels à l’environnement numérique commence donc par une technique millénaire: l’écriture. Nous pourrions beaucoup mieux documenter nos offres culturelles sur nos sites web sans nécessairement plonger dans des domaines de connaissance complexes. Il suffit d’apprendre à décrire des choses et les relations entre ces choses pour des systèmes qui, eux-même, apprennent à lire afin de fournir la meilleure information à leurs utilisateurs. Bref, avant de se lancer dans la modélisation de données ou le web sémantique, il serait temps de revenir aux stratégies de communication, ainsi qu’aux bonnes pratiques de rédaction web.
Comment rendre votre information repérable, accessible et interopérable
Ce billet s’inscrit dans la ligne du précédent, qui appelait à remplacer le terme fourre-tout de découvrabilité par les objectifs, beaucoup plus concrets, de repérabilité, accessibilité et interopérabilité.
Source de la référence: ce billet de Bill Slawski.
Nos sites web sont des ensembles d’informations structurées pouvant être repérées, consultées, utilisées et interconnectées sur la grande plateforme ouverte qu’est le Web. C’est pour cette raison que les nôtres sont au cœur de la découverte de contenus et d’offres diverses. Nous devrions consacrer prioritairement nos efforts à les moderniser. Parce qu’aujourd’hui, tout part de là.
Objectif: aider les moteurs à repérer et lier des entités
Les moteurs de recherche indexent le contenu des pages web. Grâce au développement de bases de connaissances structurées (Knowledge Graph), ceux-ci peuvent repérer dans chaque page des choses ayant une signification spécifique, comme des personnes, des lieux, des événements ou des œuvres. Ces choses sont appelées « entités nommées ». Les entités nommées qui sont repérées sont catégorisées et associées selon le modèle d’organisation propre à chacune des bases de connaissances des moteurs de recherche.
Nos sites web, lorsqu’ils sont bien conçus, alimentent ces bases de connaissances. C’est pour cette raison qu’il faut prioriser l’amélioration de la repérabilité des contenus sur nos sites avant de verser des données dans Wikidata. Cette base de connaissances, tout comme d’autres, sert à réduire l’ambiguïté entre des entités (homonymes) et à valider les liens entre elles. Elle ne remplace cependant pas les sources d’information interconnectées, classifiées et référencées que sont les sites web.
Stratégie: quoi, pour qui, avec quels objectifs?
L’amélioration des conditions de repérabilité de l’information ne produit pas de résultat immédiat, contrairement aux tactiques de référencement organique de pages. Elle s’inscrit dans la durée et doit s’appuyer sur des notions précises plutôt que sur des mythes.
La réflexion stratégique permet de déterminer les objectifs à atteindre, les questions auxquelles les données doivent répondre, les publics cibles et les caractéristiques des offres à mettre de l’avant. Les objectifs vérifiables et mesurables de la « découvrabilité » sont les indicateurs de succès qui ont été déterminés en amont dans la stratégie numérique.
Responsabilités: qui fait quoi?
Comme je l’ai déjà mentionné dans un autre billet, nous ne devons plus concevoir des sites web comme des documents, mais comme des plateformes de données. Il faut nous affranchir d’un modèle de conception hérité du document imprimé afin de concevoir le site en commençant par les modèles de données plutôt que par les modèles de pages. Viennent ensuite la définition des structures représentant le ou les domaine de connaissance, puis la représentation des types d’entités sous forme de nœuds et de liens pour former, finalement, des graphes. Tout ceci nous oblige à revoir la méthodologie de conception de sites et à faire appel à des compétences qui sont rarement sollicitées pour des projets web.
Il ne s’agit pas uniquement de savoir comment intégrer ce processus dans les activités d’un projet, mais aussi de savoir ce qui doit être fait à l’interne et ce qui doit, par contre, être confié à des spécialistes.
Il n’existe pas de recette toute faite, ni d’application, pour améliorer ainsi l’organisation de l’information. L’élaboration d’un modèle de données représentant différentes entités et les relations qui les définissent est un travail de spécialiste. De plus, la spécificité des offres, objectifs stratégiques, publics cibles et environnements technologiques soulèvent des questions auxquelles une présentation de 3 heures ne permet pas de fournir de réponses solides.
Trois étapes essentielles pour rendre l’information plus repérable et découvrable
J’utilise des outils simples pour accompagner des équipes dans leurs démarches d’amélioration de sites web et de description de contenus avec des données structurées. Cependant, les projets n’avanceraient pas si ces équipes étaient livrées à elles-même, sans ressources pour répondre aux nombreuses questions que la démarche permet de soulever.
Comment améliorer la découvrabilité de contenus culturels sur un site web? Les principes d’organisation et de rédaction des sujets des pages d’un site contribuent à la visibilité des contenus dans les résultats des moteurs recherche. Voici trois étapes essentielles d’une méthode conception web pour une information plus repérable et découvrable:
1. Organiser le site web autour des entités
L’organisation du site et la structure de l’information concernent les pages web lisibles par des humains et indexables par des machines (voir Structurer l’information autour d’entités repérables) et le code informatique de ces pages qui est interprétable par des machines (lire Schema.org n’est pas le moteur de recherche).
Vous pouvez évaluer en quelques points si la structure et le contenu des pages de votre site fournissent aux éléments d’information (entités nommées, métadonnées, mots clés) les meilleures conditions d’exploitation, pour des visiteurs et pour des moteurs de recherche.
- Arborescence (accès aux offres et contenus).
- Nomenclature (alignement de la taxonomie sur les publics cibles).
- URL unique et lisible pour chaque offre et contenu.
- Images (nomenclature de fichier, texte alternatif, résolutions).
- Description (caractéristiques, attributs distinctifs, expérience).
- Information à valeur ajoutée (liens vers d’autres sources d’information complémentaire).
2. Faire « du lien »
Comment évaluer le potentiel de rayonnement de vos contenus dans le numérique?
- En cartographiant l’écosystème composé de points et de liens qui jouent un rôle central dans leur visibilité et découverte.
- En identifiant les points (site web, réseaux sociaux, sites de partenaires) permettant d’établir des connexions pertinentes vers vos offres.
Vous reporterez ensuite, dans une grille, les points ainsi identifiés, puis dresser l’inventaire détaillé de l’information diffusée, de la fréquence des publications, des rôles et responsabilités de chacun. Vous serez alors en mesure de:
- Déterminer les points permettant de rejoindre différents publics (en d’autres termes, associer les bons canaux et contenus aux bons publics).
- Identifier les liens à créer ou à solidifier ainsi que les partenariats à développer.
3. Décrire les entités
Cette grille permettra d’identifier les métadonnées qui rendent vos offres et contenus uniques et plus faciles à trouver. Vous pouvez à la fois:
- Trouver les mots pour différencier votre offre auprès de vos publics cibles.
- Fournir des métadonnées permettant aux moteurs de recherche de fournir des réponses personnalisées.
Ces activités devraient être réalisées en groupe, au sein d’une organisation ou, lorsqu’il s’agit d’une initiative collective, avec les représentants de différentes organisations.

Découvrabilité = Repérabilité + Accessibilité + Interopérabilité

Traditionnellement, des réponses sont retrouvées à partir d’une collection de documents ou d’un graphe de connaissances.
(«Traditionally, answers have been retrieved from a collection of documents or a knowledge graph», Google AI Blog)
Traditionnellement ?
Cet adverbe est ici associé à «graphe de connaissances»: une technologie et des pratiques documentaires que nous ne maîtrisons pas.
Cette association, signale l’ampleur de l’écart entre notre conception des systèmes d’information, qui a peu évolué depuis l’invention des bases de données (pré Web), et le développement de graphes de données interconnectables (entité-relation) permettant, depuis plusieurs années déjà, de raisonner sur des connaissances.
Découvrabilité
Je préfère ne plus employer le terme « découvrabilité » car il porte l’illusion de pouvoir pousser des contenus sur les écrans des utilisateurs, comme à l’époque d’avant Internet. Cet espoir, qui façonne la plupart de nos projets connectés, est probablement la source de leur plus grande faiblesse.
Afin de faire évoluer nos usages du Web, il faut que nos initiatives numériques aient d’autres objectifs, plus concrets et vérifiables, que la découvrabilité. Ce mot trahit notre incapacité à faire évoluer notre compréhension du Web face à des entreprises qui se sont constituées en misant sur ses possibilités ultimes.
S’agit-il d’une caractéristique de l’information ou d’une activité de promotion? « Découvrabilité » est un néologisme dont nous n’arrivons pas à rapporter le sens à un savoir commun. Et pour cause: chaque spécialiste ou consultant l’adapte à ses compétences et à sa capacité d’intervention. L’absence de définition commune et précise ne facilite donc pas la convergence des initiatives numériques.
Je crois que nous aurions intérêt à remplacer ce concept flou par trois objectifs concrets pour lesquels il existe des connaissances formalisées et des outils pratiques: repérabilité, accessibilité et interopérabilité.
Repérabilité
Information documentée de façon à pouvoir être identifiée et localisée le plus aisément possible (architecture du site web, taxonomie, métadonnées). Synonyme: trouvabilité.
Accessibilité
L’information se trouve dans le Web et est accessible tant aux humains (contenu ouvert) qu’aux machines et algorithmes (indexation par les moteurs de recherche). L’accessibilité du web, qui vise initialement à permettre aux personnes handicapées d’accéder aux contenus et services web, est l’une des composantes de l’accessibilité numérique.
Interopérabilité
L’information est exprimée selon les standards universels, libres et ouverts d’accessibilité et de lisibilité pour les humains et les machines (protocole de communication HTTP, adressage URL, langage HTML). Voir ses enjeux, principes et typologies présentés dans Wikipedia.
***
Le Web est la seule plateforme permettant de publier de l’information de façon repérable, accessible et interopérable par qui ou quoi que ce soit. C’est pour cette raison que l’amélioration de la découverte d’offres et de contenus, dans un monde numérique, dépend de la structure de l’information publiée sur les sites web.
Dans le prochain billet, nous verrons pourquoi il faut revoir la façon dont nous concevons nos sites web et ce que tous devraient savoir pour adopter de nouvelles bonnes pratiques.
Et si le rayonnement des offres culturelles passait par de meilleurs sites web?
Structurer l’information autour d’entités repérables
Pourtant, plus de vingt ans après la naissance du web, la conception de sites est encore largement influencée par la production de documents imprimés. Si la forme et le design se sont adaptés aux modes et aux supports, la structure et la conception de l’information n’ont pas bougé. Nos sites sont encore conçus pour être lus par des humains.
Voici quelques éléments qui sont essentiels pour faciliter le repérage d’entités (personnes, organisations, œuvres, lieux, événements) par des moteurs de recherche et autres applications.
Un site pour être dans le web
Un site web est au centre d’un écosystème numérique. C’est une adresse où se trouve de l’information accessible selon des standards universels et ouverts. C’est également un espace de publication qui n’est pas assujetti à d’autres objectifs que ceux de son propriétaire. Constitué de pages et de documents reliés entre eux et à d’autres sites web par des hyperliens, il peut se trouver sur le parcours d’utilisateurs et de moteurs de recherche. Un site web marque l’existence d’une entité dans cette application qui opère sur l’Internet et qui s’appelle le Web.
Ne compter que sur des réseaux sociaux pour avoir une présence numérique est une pratique qui réduit le potentiel de rayonnement et de découverte de nos contenus culturels.
Une URL pour chaque offre
Le développement des moteurs évolue rapidement vers le repérage et l’interprétation d’entités nommées (noms propres ou expressions définies comme un événement) dans des données non structurées. Pour faciliter le repérage d’un événement ou d’une œuvre, il faut lui attribuer une page spécifique. Publier plusieurs offres dans la même page ne permet pas à une machine de traiter adéquatement l’information qui y est présente. L’unicité et la persistance de l’URL signalent la présence d’une entité «événement» ou «œuvre» qui est liée à l’entité organisation.
Des mots qui connectent avec des publics
L’intégration des balises du vocabulaire Schema.org permet d’identifier des types d’offres et de générer des aperçus, ou résultats enrichis, dans certains cas d’usage (expressément non garanti par Google). Celles-ci ne permettent cependant pas aux moteurs de recherche de différencier une offre d’autres offres similaires. Ce sont alors des mots (description, titre, caractéristiques) qui peuvent générer des liens entre l’information recherchée par des utilisateurs et les données non structurées qui sont présentes dans la page web.
Le choix des mots employés est stratégique parce que ceux-ci peuvent être utilisés pour fournir une réponse plus précise à une question (et cela, tant dans le contenu d’une page que dans le balisage qui est intégré dans son code HTML). Il s’agit d’établir des connexions avec les vocabulaires et intérêts des publics cibles et de rendre le contenu indexé unique ou le distinguer d’autres contenus similaires.
Des images qui parlent et font du lien
Parmi les conditions qui facilitent le traitement de l’information par les moteurs de recherche, on ignore trop souvent celles qui concernent les images. Une page qui comprend une image sera préférée à une autre qui n’en a pas. Si des liens, dans le code HTML de la page, fournissent un accès à des fichiers contenant trois résolutions de cette image (1X1, 4X3, 16X9), le contenu sera assurément exploitable. dans des résultats de recherche et sur de petits écrans. Notez que l’optimisation des images est automatiquement prise en charge par certains systèmes de gestion de contenu et certains thèmes de WordPress.
Nommer le fichier d’une image en utilisant des mots qui sont pertinents avec la description de son contenu en facilite l’exploitation et la gestion.
Des liens pour relier des entités nommées
Ne pas faire de liens, hors d’un site web, afin d’y retenir les internautes nuit au rayonnement. Le déploiement de liens entre les acteurs concernés par la création, production et diffusion d’un contenu culturel souligne la présence numérique de chacun. La simple présence de liens vers des sources d’information externes enrichit l’information tout en favorisant des découvertes. Par exemple, relier des entités nommées autour d’une production audiovisuelle (œuvres musicales, lieu historique, réalisatrice et d’acteurs) améliore leur potentiel d’être découvertes par des humains et des machines.
Des sites web pour construire un réseau d’hyperliens
Le rayonnement et la découverte de nos contenus culturels sur le web dépendent, avant tout, de l’organisation et de la structure de l’information sur nos sites web. Ne pas avoir son propre site, c’est ne pas faire partie du web ouvert, interopérable et de plus en plus interprétable par des machines. C’est également laisser à d’autres le soin de parler de vous. Mais, c’est surtout, renoncer aux moyens les plus simples et accessibles (vous rappellez-vous les blogolistes ou « blog roll » ?) que nous ayons pour relier les personnes, les organisations, les œuvres, les événements et les lieux, sur nos territoires et sur tout le Québec.
Mais si l’amélioration de la qualité de l’information numérique repose sur de meilleurs sites web, faudrait-il alors revoir les programmes de financement qui en excluent le développement ?
Les acteurs culturels doivent-ils devenir spécialistes de l’information numérique ?
Les fournisseurs de services web ne sont-ils pas en première ligne lorsqu’il s’agit de conseiller et de réaliser des projets pour les acteurs culturels ? La même question se pose concernant les exigences de découvrablité des programmes de financement. Où sont les compétences nécessaires pour offrir un accompagnent qui soit susceptible d’apporter des améliorations notables ?
Nécessaire mise à jour des connaissances et des programmes de formation
En l’absence de connaissances formalisées et de méthodes pédagogiques pour améliorer la littératie de l’information numérique (car c’est bien de cela dont il s’agit), le milieu culturel est laissé à lui-même. Il fait face à une variété d’interprétations, d’approches et de propositions stratégiques et technologiques dont il n’est pas en mesure d’évaluer l’exactitude, la pertinence ou le rendement potentiel.
Il serait donc urgent de réunir des représentants des domaines des sciences de l’information et des technologies numériques, des secteurs industriels et académiques, afin de proposer une mise à jour des compétences et des formations.
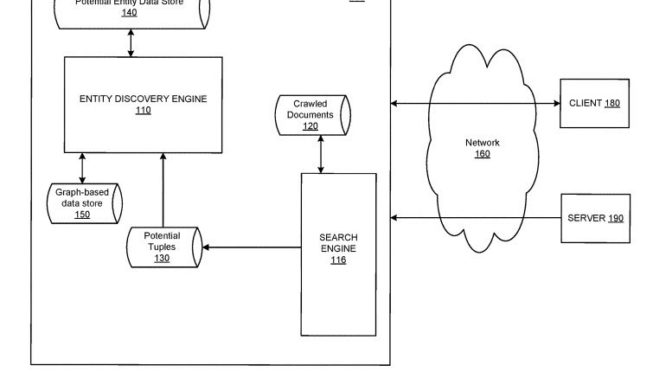
Le journalisme d’enquête et le graphe de connaissances de Google
Google annonce un changement à son algorithme afin de promouvoir le journalisme d’enquête.
Mais ceci servira surtout à améliorer la quantité de données contenues dans son graphe de connaissances (knowledge graph) et d’étendre son influence sur ce que nous voyons sur le web.
Bill Slawski est un spécialiste de l’optimisation pour moteurs de recherche. Sa formation de juriste lui permet de porte une attention particulière aux demandes de brevet. Il en commentait une, récemment, qui fait référence au développement du graphe de connaissances (knowledge graph) de Google. Elle concerne l’intégration, dans son graphe, d’information collectée sur le web, afin d’accroître la masse de données :
The patent points out at one place, that human evaluators may review additions to a knowledge graph. It is interesting seeing how it can use sources such as news sources to add new entities and facts about those entities.
Comme chez les autres entreprises dont le modèle d’affaires repose sur la donnée, une grande partie du traitement de l’information et de la production de données résulte du travail non rémunéré d’amateurs et passionnés:
How can you teach an algorithm to understand all these distinctions? Gingras said Google is doing so through its Quality Raters, a global network of more than 10,000 individuals who offer feedback on Google’s search results, which in turn is used to improve the company’s search algorithms.
Google says it will do more to prioritize original reporting in search
Ceci sert-il les intérêts du journalisme ? Probablement, mais il est trop tôt pour le vérifier. Cela sert surtout à développer une connaissance très poussée de nos rapports à l’information et de permettre à d’autres d’influencer notre vision du monde et de fabriquer des opinions. S’informer sur le scandale Facebook – Cambridge Analytica devrait nous faire prendre la mesure de l’intervention de ces systèmes dans notre développement social, notamment, la fabrication d’opinions et d’antagonismes.
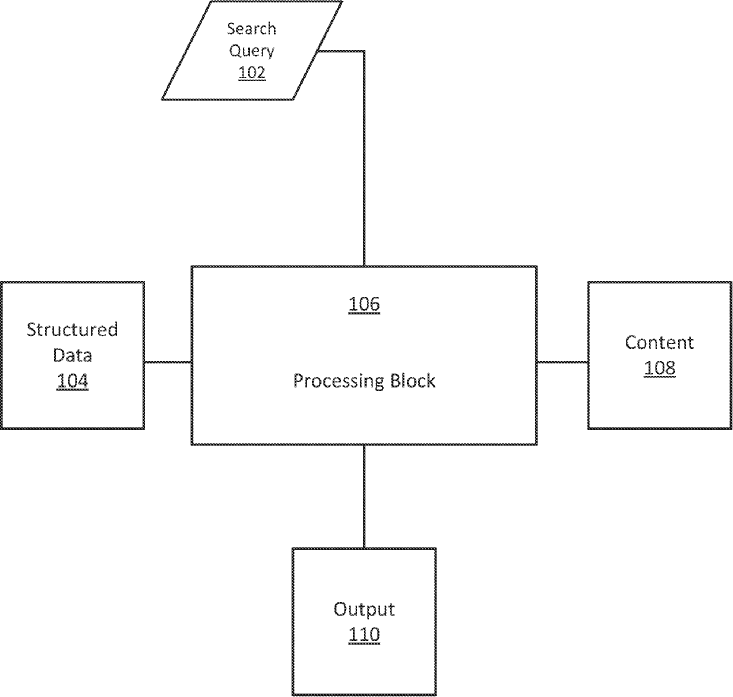
À quelles questions répondent vos (méta)données ?
Mise à jour 2019-09-07: ajout, à la fin du billet, d’information concernant les cas d’usage, suite à un commentaire exprimé sur Facebook.
Produire et réutiliser des données descriptives, ce n’est pas travailler sur une solution, mais sur des questions.
Quelle est la finalité du projet ?
Comment savoir si les données d’une organisation ou d’un collectif ont un fort potentiel informationnel ? Comment ces données peuvent-elles répondre à des questions qui demandent de faire des liens entre des entités et d’interpréter des relations ? Si ces données ne sont pas suffisamment riches en information, comment les lier avec celles provenant d’autres sources, ouvertes et privées, pour les valoriser ?
La finalité de projets de données est de générer l’information la plus riche afin de répondre à des questions à la satisfaction des publics cibles. Toute initiative devrait donc débuter par un diagnostic de la disponibilité et de la qualité des données. Cependant, comment effectuer un tel exercice sans savoir à quels besoins répondront-elles ou, plus exactement, à quelles questions devront-elles répondre ?
Trouver les bonnes questions: la dimension cognitive des projets
La dimension cognitive des projets numériques se rapporte à la sélection, l’organisation et le traitement de l’information. Ces activités doivent réunir des perspectives et compétences diversifiées: de la connaissance du domaine et des publics à la modélisation de l’information. Il s’agit d’un travail collaboratif qui doit être réalisé en amont de la conception technique. Cette étape est rarement bien planifiée et réalisée, faute de budget, ressources ou méthode de travail. Pourtant, elle constitue le coeur du projet. C’est, de plus, un processus qui permet d’améliorer la littératie numérique et développer des pratiques collaboratives au sein d’une organisation et d’un partenariat.
Interroger les données: repenser les vieilles interfaces
Les vieux modèles d’interfaces de recherche influencent notre conception des questions que nous posons aux ensembles de données. Elles forcent les utilisateurs à formuler leurs questions en fonction de critères limités. Ces interfaces pré web qui sont encore utilisées pour donner accès au contenu de catalogues en ligne sont nettement déclassées par la recherche en langage naturel.
Cocher des critères comme la date, l’auteur, le sujet ou le titre ont assez peu à voir avec les comportements et besoins des utilisateurs. L’indexation des contenus et le paramétrage du moteur de recherche des sites sont généralement peu élaborés. Par exemple, explorer les archives du journal Le Devoir est plus intéressant à partir de l’interface de Google. Il suffit de limiter la recherche au site et d’ajouter des expressions ou, même, des questions , comme ceci: « site:https://www.ledevoir.com/ causes du changement climatique ». On peut alors explorer les textes, images et vidéos. Les traces de nos usages ne serviront cependant pas les intérêts du média, mais le modèle économique du moteur de recherche.
Remplacer les cas d’usage par une approche narrative
Avant de développer de nouvelles plateformes, il y aurait place à amélioration pour répondre aux besoins d’information spécifiques des publics et accompagner le développement de services à valeur ajoutée.
Mais trouver les bonnes questions à poser requiert une connaissance des publics cibles et, pourquoi pas, leur participation. Pour cela, il convient de remplacer l’approche technologique (cas d’utilisation) par une approche narrative, plus concrète et plus proche du phénomène informationnel (lier des données pour raconter une histoire).
When we frame information about an object we focus attention on certain aspects of that object or its history. It’s just like choosing a new frame for a painting, which then highlights different qualities of the artwork. Framing is less about the information we feature in a label and more about how we present that information.
Le sujet de cet article dépasse le domaine muséal: What makes a great museum label?
Exploiter des données plus riches de sens
Notre relation aux contenus culturels est de l’ordre du ressenti, du goût et des intérêts. Cependant, nos bases de données et catalogues fournissent une information factuelle, organisée de façon uniforme et anodine, bien loin de la diversité des cultures et expériences humaines. D’autres métadonnées pourraient jouer un rôle aussi important que les métadonnées classiques de type catégorie-titre-auteur, pour la personnalisation des services et pour l’analyse des données d’usage.
Sous la direction d’Yvon Lemay et Anne Klein, de l’École de bibliothéconomie et des sciences de l’information, Archives et création: nouvelles perspectives en archivistique regroupe des publications de recherche sur l’exploitation des archives dans le domaine culturel (arts visuels, littérature, cinéma, musique, arts de la scène, arts textiles et Web). Cette publication devrait être lue par quiconque souhaite réfléchir sur la mise en réseaux des données sur la culture.
Indexation – Émotions – Archives, la recherche menée par Laure Guitard, se rapporte plus spécifiquement à l’enrichissement des modèles de données par la représentation de la charge émotionnelle des contenus et objets (page 151).
l’indexation – professionnelle et collaborative – pourrait permettre d’inclure l’émotion dans la description des archives afin que cette dernière soit reconnue comme une clé d’accès aux documents
Je souligne, avec cette référence, l’importance de la recherche académique et des regards croisés entre domaines d’étude pour apporter de la profondeur à des idées. Les monocultures sectorielle, disciplinaire et technologique nuisent à nos ambitions numériques.
Renforcer le volet cognitif des projets
Il faut revoir des modèles d’indexation de contenu, ou de production de métadonnées. Disposer de données plus riches permet d’analyser la relation de l’utilisateur au contenu, de mieux connaître les publics, de développer des algorithmes de recommandation et, finalement, d’imaginer d’autres façons de valoriser des catalogues, fonds et répertoires.
Nous ne devons pas nous laisser démonter par la complexité des projets ou, pire: brûler de précieuses ressources en « coupant les coins ronds». Nous pouvons y faire face en mettant en commun des ressources et des expertises diversifiées et en élaborant d’autres méthodes de travail. Donnons-nous du temps, mais commençons dès maintenant.
Ajout d’information concernant les cas d’usage et l’approche narrative, à la suite d’une très bonne question posée par Frédéric Julien, sur Facebook.
Extrait du commentaire de Frédéric :
Je ne suis par contre pas certain de comprendre ce que tu entends par « remplacer les cas d’usage par une approche narrative ». Au cours de la dernière année, j’ai eu la précieuse occasion de participer à quelques exercices de consultation auprès de créateurs et usagers de données dans le cas du projet 3R. Ce que j’y entendu a énormément contribué à ma réflexion sur les cas d’usage dans le cadre de l’initiative ANL [Un avenir numérique lié]. Ces deux méthodologies ne me semblent pas du en contradiction l’une avec l’autre (ni avec ce que tu décris dans ton billet… à moins que certains détails ne m’échappent).
Réponse:
/…/ une approche narrative permet de réaliser des cas d’usage en les mettant en contexte (le « comment »). J’emploie un terme fort, « remplacer », pour attirer l’attention sur une étape du projet sur laquelle se fondent beaucoup d’objectifs (et d’espoirs). C’est une étape cruciale pour la mise en relation de l’information avec des utilisateurs. Elle est trop souvent escamotée ou sert uniquement à construire des exemples de requêtes.
Suivre une approche narrative ne signifie pas raconter une histoire, mais analyser des comportements, des usages, des interfaces et des structures de données pour produire des exemples qui vont démontrer l’utilité ou la valeur ajoutée du système.
Cependant, les cas d’usage réalisés de façon habituelle (comme en informatique), portent sur le « quoi » (les données, les étiquettes à mettre) alors que les éléments de la recherche et de la découverte ne sont plus les mêmes:
- Interrogation de données liées conçue comme des requêtes sur des BD tabulaires (où est le potentiel du liage de données?)
- Travail de terrain très rarement réalisé avec des utilisateurs finaux, dont des non-usagers (ex: non-visiteurs de musées) et des non-amateurs de certains type d’offres (ex: films québécois).
- Confusion entre parcours de recherche et de découverte (qu’est-ce que chercher? découvrir? comment cela se produit-il dans des contextes spécifiques, avec certains supports et chez certains types d’utilisateurs ?)