Je le répète: il faut retomber en amour avec nos sites web. Nous devons réinvestir le domaine du langage sur ces espaces numériques privilégiés que sont nos sites web.
Continuer la lecture de De données structurées à contenu structuréJe le répète: il faut retomber en amour avec nos sites web. Nous devons réinvestir le domaine du langage sur ces espaces numériques privilégiés que sont nos sites web.
Continuer la lecture de De données structurées à contenu structuré![Planche dPlanche de l’Encyclopédie de Diderot et d’Alembert: taille de la plume pour l’écriture. Morburre, [CC BY-SA 3.0], Wikimedia Commonse l’Encyclopédie de Diderot et d’Alembert: Taille de la plume pour l’écriture.](https://fr.wikipedia.org/wiki/Fichier:Ecriture-TaillePlume-Encyclopedie.jpg)
Or, ce ne sont plus les balises Schema.org insérées dans le code ni les articles de Wikipédia qui facilitent le travail des moteurs de recherche en les rendant intelligents. C’est, à présent, le traitement automatique du langage naturel. Celui-ci permet aux algorithmes d’évaluer l’information présente sur une page web et lisible par les humains.
Plus l’information offerte par le texte est riche et contextualisée par des liens vers d’autres pages web, plus elle a de valeur pour nous et, par conséquent, pour les moteurs de recherche dont l’objectif est de nous offrir les meilleurs résultats possibles.
Après quelques années d’accompagnement d’entrepreneurs culturels, je peux affirmer que rares sont les non-initiés sachant manier avec aisance des notions et des mécanismes qui demeurent complexes, même pour des spécialistes du Web. Ce billet sur les définitions divergentes de ce qu’est une ontologie permet de mesurer le défi d’établir une compréhension commune et claire d’une notion pourtant fondamentale des systèmes documentaires. Et pour celles et ceux qui persévèrent, les concepts et pratiques nouvellement acquis sont trop éloignés de leurs activités pour qu’ils soient en mesure de les intégrer aux opérations et de se livrer à la veille technique qui s’impose en permanence.
Structurer de l’information pour une variété d’usages et de systèmes, c’est un travail de spécialistes. Le rôle de créateurs de contenu consiste à documenter cette information et à raconter comment elle s’insère dans notre monde. Ils peuvent se faire aider afin de produire l’information répondant le mieux aux intérêts des publics cibles et de fournir des liens nécessaires aux humains et aux machines pour apporter du contexte, favorisant ainsi la découverte.
Voici les étapes qu’il faudrait suivre afin d’améliorer la valeur informative de la page web consacrée à une offre culturelle:
Mieux un contenu est documenté, plus il est susceptible de pouvoir réponse à une question. Il est donc important de baser la conception du contenu d’une page sur une solide connaissance des publics cibles. D’où la nécessité d’une stratégie et d’une concertation entre les producteurs, diffuseurs et toutes autres parties concernées. Toutefois, l’élaboration d’une stratégie de ce type requiert une formation préalable mobilisant divers spécialistes.
L’adaptation de nos contenus culturels à l’environnement numérique commence par l’écriture. Tous les éditeurs de sites web doivent à présent mieux organiser et documenter leurs contenus pour les rendre plus repérables. Pour Google, « documenter » signifie: bien décrire un contenu et fournir du contexte en faisant des liens entre des concepts. Plus la documentation est exhaustive et clairement libellée, plus elle a de la valeur pour les utilisateurs — et plus la page web de l’offre culturelle devient une source d’information de qualité.
Certains types de contenus — comme les vidéos, par exemple — peuvent apparaître sous forme d’extraits, dans la liste de résultats de Google (résultats enrichis). L’utilisation de balises permettant de catégoriser des contenus n’est donc pertinente que pour un petit nombre d’offres. Les modèles descriptifs recommandés sont ceux qui concernent les projets de développement des services du moteur de recherche. De plus, les consignes à suivre évoluent en fonction du résultat des expérimentations et de l’avancement du traitement automatique du langage.
Nous devons, alors, éviter de développer des fonctionnalités qui deviennent rapidement obsolètes ou, pire, qui réduisent notre capacité d’innovation en l’encadrant dans la logique d’affaires d’une plateforme. Il faut donc que nous demeurions extrêmement vigilants afin que nos projets nous apportent une réelle valeur et ne tombent pas dans le solutionnisme technologique.
Wikipédia facilite l’identification d’un concept ou objet spécifique, mais ce sont les pages web qui sont les sources primaires pour Google. Contrairement à la croyance courante, la production d’une fiche de réponse (appelée « knowledge panel ») résulte du traitement du contenu provenant de différentes pages web. Celles-ci sont qualifiées par le moteur de recherche pour l’information qu’elles offrent. En analysant certains brevets déposés par Google, on peut déduire que son utilisation de l’encyclopédie n’est ni constante, ni déterminante. Créer un article Wikipédia n’est donc pas une activité essentielle dans un plan de découvrabilité, même si cela peut accroître la notoriété d’un sujet lorsqu’il contient des connaissances utiles et des liens vers d’autres articles.
Adapter nos contenus culturels à l’environnement numérique commence donc par une technique millénaire: l’écriture. Nous pourrions beaucoup mieux documenter nos offres culturelles sur nos sites web sans nécessairement plonger dans des domaines de connaissance complexes. Il suffit d’apprendre à décrire des choses et les relations entre ces choses pour des systèmes qui, eux-même, apprennent à lire afin de fournir la meilleure information à leurs utilisateurs. Bref, avant de se lancer dans la modélisation de données ou le web sémantique, il serait temps de revenir aux stratégies de communication, ainsi qu’aux bonnes pratiques de rédaction web.
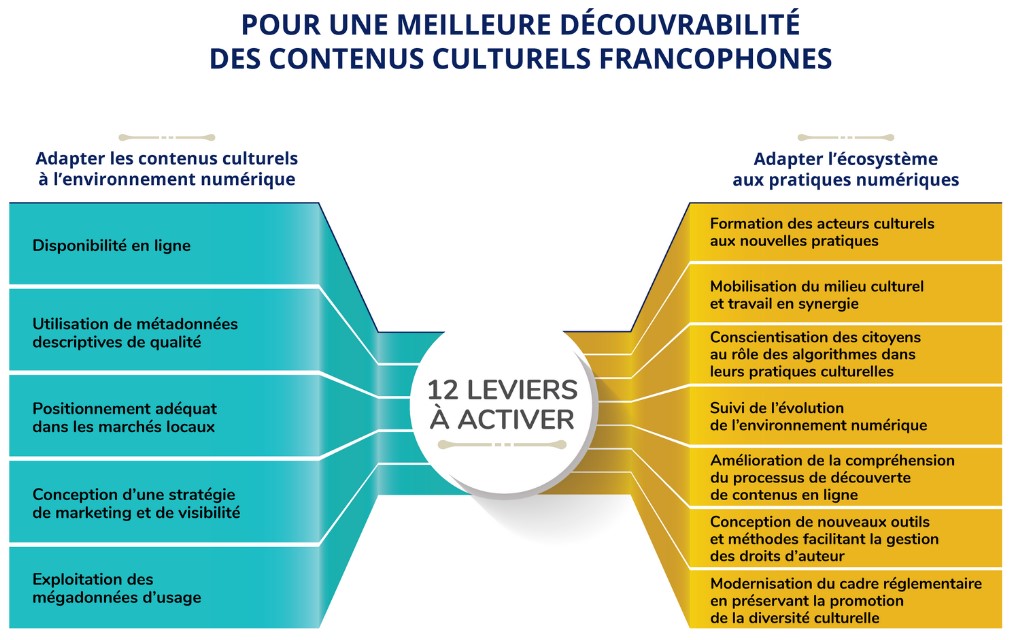
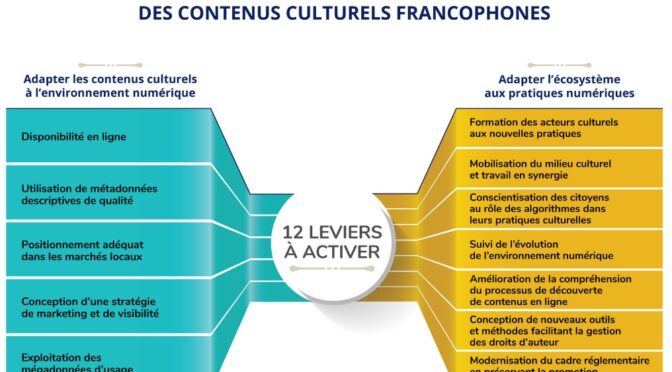
Le rapport sur la découvrabilité en ligne des contenus culturels francophones résulte d’une mission conjointe des ministères de la Culture du Québec et de la France. Il dresse un bon état des lieux d’un ensemble de phénomènes et d’actions, sans égarer le lecteur dans les détails techniques. Un excellent exercice de synthèse, donc, réalisé par Danielle Desjardins, auteure de plusieurs rapports pour le secteur culturel et collaboratrice du site de veille du Fonds des médias du Canada.
Cependant, dans le schéma des 12 leviers à activer pour une meilleure découvrabilité des contenus culturels francophones (voir plus haut), il manque à mon avis deux éléments essentiels:
Il est important de sensibiliser les acteurs culturels à l’adoption de pratiques documentaires telles que l’indexation de ressources en ligne. Ceci dit, la mise en application des principes, ainsi que le choix de modèles de représentation de contenus en ligne, sont des compétences qui ne s’acquièrent pas comme on apprend à se servir d’un logiciel. On ne peut pas attendre de toute personne et organisation du secteur culturel de tels efforts d’apprentissage. D’autant plus que la production de l’information pour le numérique fait appel à des méthodes et savoirs relevant des domaines du langage et de la représentation des connaissances autant que des technologies numériques.
Si les données structurées sont perçues comme des solutions pouvant accroître la visibilité d’offres culturelles sur nos écrans, elles appartiennent à des domaines de pratiques pas suffisamment maîtrisés au sein des métiers du Web. C’est pourtant bien vers des spécialistes en développement, intégration, référencement et optimisation que se tournent les acteurs culturels cherchant à rendre le contenu de leurs sites web plus interprétable par des machines. Or, à ma connaissance, il n’existe actuellement pas de formation et de plan de travail tenant compte de l’interdépendance des volets sémantiques, technologiques et stratégiques du web des données.
Il devient de plus en plus impératif d’identifier les connaissances à développer ou à approfondir chez les divers spécialistes contribuant à la conception de sites web aux contenus plus repérables. Il serait également souhaitable de soutenir un réseau de veille interdisciplinaire ayant pour objectif de contextualiser et d’analyser l’évolution de l’écosystème numérique.
Exemple: dans la foulée d’une étape importante de ses capacités d’interprétation (traitement automatique du langage), Google a mis à jour, cet été, ses directives d’évaluation de la qualité de l’information. Il va sans dire que c’est important.
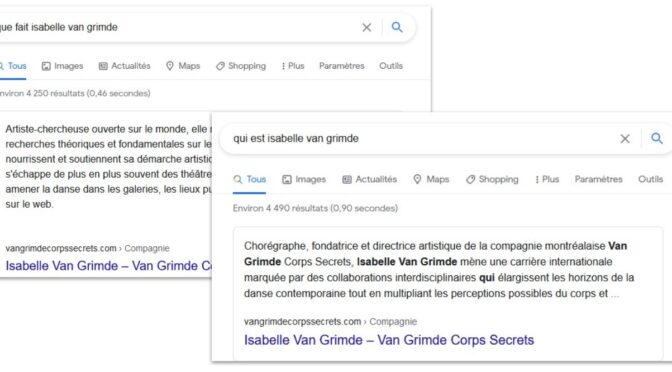
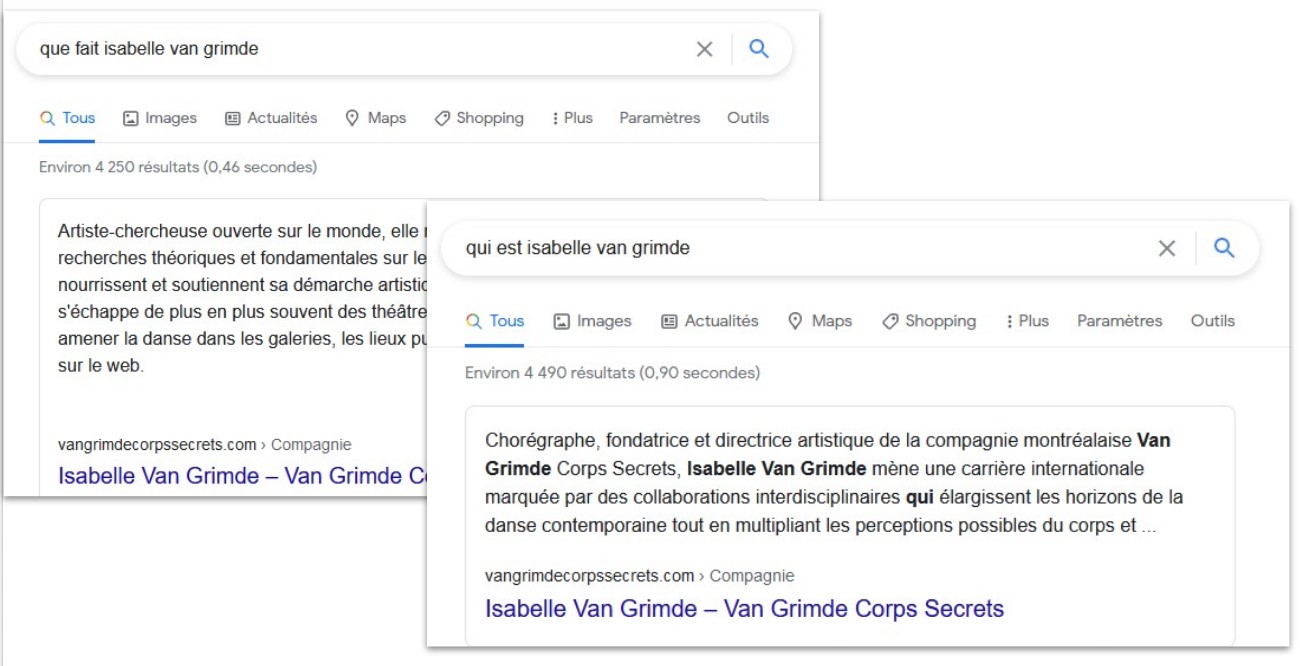
Dans le Web des moteurs de recherche intelligents, la reconnaissance des entités passe par l’indexation de pages web et l’analyse des contenus. Les sites web devraient donc être des sources d’information de première qualité, tant pour les internautes que pour les moteurs de recherche.
Est-il normal de ne pas trouver toute l’information, riche et détaillée, sur le site de référence d’une entreprise culturelle? Pour le bénéfice des projets numériques, il est vital de concevoir des contenus pertinents pour les machines, lesquelles évaluent à présent la qualité des sources d’information afin de générer la meilleure réponse à retourner à l’utilisateur.
Pour une productrice ou un artiste, il est beaucoup plus stratégique de faire de son site web une source primaire, en attribuant une page spécifique à la description de chaque œuvre, que de créer un article sur Wikipédia. Rappelons que Wikipédia n’est pas une source primaire pour les moteurs de recherche. De plus, l’usage du vocabulaire (Schema.org) ne leur fournit qu’un signal faible sur la nature d’une offre.
L’adaptation des contenus culturels à l’environnement numérique repose, avant tout, sur de meilleurs sites web. Ces espaces offrent les conditions optimales d’autonomie, repérabilité, accessibilité et interopérabilité. Leur modernisation requiert des acteurs clés, que sont les spécialistes du Web, une mise à niveau rapide de leurs connaissances et de leurs pratiques.
Finalement, afin d’opérer cette mise à niveau et de développer ces savoirs communs, il faut bien entendu insister sur l’interdisciplinarité entre les métiers du web et, notamment, le domaine des sciences de l’information.

Retour sur des notes prises en lisant des propositions de projets numériques.
L’absence de réflexion stratégique est le talon d’Achille de la plupart des propositions de projets et de plans de découvrabilité. Pourtant, qu’il s’agisse de baliser des types de contenu à l’intention des moteurs de recherche ou de décrire des ressources dans un catalogue en ligne, la production de métadonnées utiles s’appuie sur la connaissance des publics cibles et des résultats recherchés.
La meilleure façon d’évaluer le résultat des efforts déployés pour qu’une offre ou un contenu rejoigne ses publics est de fixer des objectifs mesurables et réalistes. Et pour cela, il faut avoir élaboré une stratégie basée sur la connaissance du marché, des opportunités et des contraintes propres à l’organisation.
Les algorithmes des plateformes évoluent vers une personnalisation accrue des réponses qu’elles proposent en s’appuyant sur les profils de leurs utilisateurs. Nos sites web devraient faire de même en fournissant des éléments d’information qui « parlent » aux publics cibles et qui, conséquemment, facilitent le travail des moteurs de recherche.
Petit rappel: nous découvrons de l’information sur l’interface d’un moteur de recherche, mais c’est celui-ci qui la trouve. Et cela, en fonction d’un traitement algorithmique fondé sur :
Voici quelques éléments clés sur lesquels réfléchir avant de déterminer les activités à réaliser dans le cadre d’un plan de découvrabilité:
Il n’existe pas de recette gagnante: une stratégie de visibilité et de rayonnement est spécifique à chaque projet. Le succès d’un plan découvrabilité dépend de choix qui sont alignés sur cette stratégie afin de publier la bonne information, dans le bon format, au bon endroit et pour le bon public.

Depuis peu, en culture, on retrouve un volet « découvrabilité » dans la plupart des appels à projets. S’agit-il d’une application technologique, de techniques de référencement ou d’une campagne de promotion numérique? L’absence d’explications concrètes et de description des compétences requises met les demandeurs (ainsi que les bailleurs de fonds!) dans une situation où ils ne disposent pas des guides nécessaires pour savoir ce qu’il faut faire, ni quels résultats escompter.
Assurer la repérabilité d’une nouvelle création ou d’une nouvelle offre est un projet à part entière, avec ses ressources, ses objectifs et ses réalisations. Il ne s’agit pas de mettre en commun ce que chacun aura produit de son côté, mais de produire des contributions s’alimentant les unes des autres. C’est pourquoi, dans nos velléités de transformation numérique, le travail en silo est un frein à la réussite de nos projets.
C’est l’information fournie à propos des choses qui est repérable — pas les choses en elles-mêmes. Cette distinction est extrêmement importante puisque c’est le choix des éléments descriptifs qui retient l’attention d’audiences cibles et qui permet aux moteurs de recherche de connecter des offres à des intentions et des profils d’utilisateurs.
Sous le couvert nébuleux de la découvrabilité, il existe en réalité des pratiques et des standards permettant de structurer l’information pour le Web afin d’en assurer la repérabilité, l’accessibilité et l’interopérabilité.
Représenter des connaissances avec les technologies du web sémantique (URI, RDF…) et structurer de l’information pour des moteurs de recherche sont des projets différents qui n’ont pas les mêmes finalités.
Si votre objectif est de faire découvrir votre offre culturelle en vous servant, entre autres, des moteurs de recherche pour générer des visites, des visionnements ou des achats, le web sémantique ne vous sera d’aucune utilité!
Google n’exploite que le langage de balisage Schema.org…
Voici les éléments de réflexion qui apporteront plus d’efficacité à votre plan de découvrabilité. La grande lacune de la plupart des plans de découvrabilité est l’absence ou la faiblesse de la stratégie — comment pousser les bons contenus aux bons publics, sur les bons canaux, pour atteindre des objectifs mesurables. Or, ce travail est essentiel à plusieurs titres:
À quels besoins et à quels publics votre offre est-elle susceptible de répondre? Les objectifs à atteindre doivent être déterminés en fonction des intérêts et comportements de ces publics cibles ainsi que de leurs possibles relations à l’offre.
Le vocabulaire Schema.org permet de fournir une description détaillée d’une offre culturelle. Google n’en utilise cependant que certains éléments. Baliser une offre de spectacle n’est pas suffisant pour permettre à celle-ci de se différencier de milliers d’autres offres. La connaissance des publics fournit les éléments d’information et le vocabulaire pouvant aider les moteurs de recherche à faire des connexions entre les intentions et profils des utilisateurs et les offres disponibles.
Les balises et le référencement par mots clés sont des outils complémentaires s’appuyant sur la stratégie de promotion. Accroître la découverte commence par la présentation de l’offre sur le site web . Ceci a pour but de faciliter le travail des moteurs de recherche et d’améliorer l’expérience de l’utilisateur avec leur interfaces.
Si un site web est absolument essentiel et stratégique, d’autres présences numériques contribuent au rayonnement d’une offre. Une bonne stratégie met donc à contribution les acteurs de l’écosystème en identifiant des points d’entrée (réseau social, vidéo, site partenaire, etc.) et en multipliant ainsi les parcours de découverte.
En se contentant de produire des métadonnées sous forme de balises Schema.org, on se conforme aux modèles et directives qui répondent avant tout aux objectifs d’affaires d’un géant du numérique. Bien que le balisage d’offres pour les moteurs de recherche fasse partie des bonnes pratiques web, Google ne garantit aucun résultat (longue lecture, mais excellent billet).
Attention: les métadonnées ne sont pas toujours utiles. Si vous souhaitez améliorer la valeur de votre site pour Google, corrigez les lacunes de conception et améliorez la valeur du contenu rédactionnel.
Finalement, la découverte d’offres culturelles sur un moteur de recherche est difficilement mesurable. Elle dépend de plusieurs facteurs extrêmement variables, comme le profil, l’intention présumée par l’algorithme et les usages antérieurs de chaque utilisateur. Ce sont donc les objectifs et indicateurs de mesure ayant été déterminés dans le plan stratégique qui permettront d’évaluer la réussite de celui-ci.
Ce ne sont pas les métadonnées qui produisent des résultats, mais les moyens déterminés par la stratégie. Il faut donc proposer des initiatives plus marquantes pour la diffusion et l’appréciation de nos offres culturelles. Par exemple, renouveler l’expérience de recherche sur un site en présentant l’information sous forme de fiches, de façon similaire à Google, mais selon d’autres règles que la popularité et la similarité.
Il n’existe pas de recette. Chaque projet étant unique, il doit se différencier pour se démarquer, et ce grâce au choix des canaux, plateformes, mots, images et liens adressés aux bons publics.
Surtout, il ne faut pas se contenter d’appliquer les consignes de Google. On doit également chercher à comprendre l’interaction complexe des systèmes et identifier les éléments stratégiques que nous pouvons contrôler.
Enfin, nous ne pouvons pas encourager le milieu culturel à se conformer à un système dont nous ne comprenons pas le fonctionnement et dénoncer, dans le même temps, la domination et l’opacité des GAFAM. Cette contradiction en dit long sur les connaissances qu’il nous reste à acquérir…

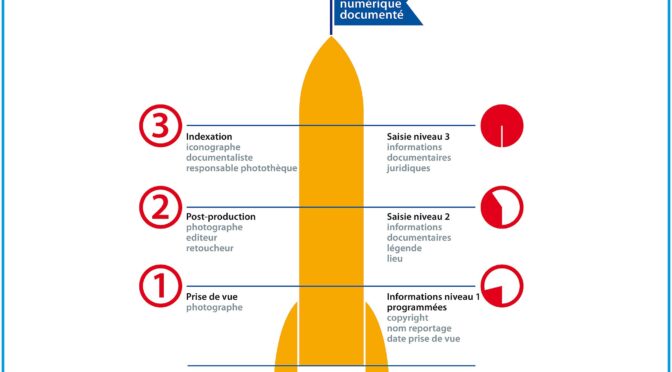
Les images sont des éléments d’information et des données. Elles améliorent le repérage d’entités (personnes, organisations, œuvres, lieux, événements) dans des pages web. Elles contribuent au développement de nouveaux parcours de découverte. À titre d’exemple, nous pouvons mentionner le moteur de recherche Google Images (créé en juillet 2001) et Wikimedia Commons où sont déposées un nombre grandissant d’images, dont celles de galeries d’art, pour en favoriser la réutilisation.
Voici deux annonces récentes qui devraient sensibiliser les éditeurs de sites web et professionnels du numérique à l’importance de documenter les images et/ou d’adopter de meilleurs pratiques.
D’abord, le mois dernier, IIIF annonçait que l’annotation des images s’étend désormais aux images des contenus audio et images en mouvement (vidéo, film). De plus, lIIF rend son modèle compatible avec l’écosystème des données liées en passant du modèle Open Annotation aux standards du Web (W3C Web Annotations) et en facilitant l’usage du langage JSON-LD pour exprimer les données. IIIF est un format de transmission de données: il ne permet pas de gérer des collections.
A critical element of this release is the ability to move beyond static digital images to present and annotate audio and moving images. This is done by adding duration to the existing IIIF canvas model, which also features x and y coordinates as means of selecting and annotating regions. Now, images and video can be juxtaposed using open source software viewers — allowing the public to view time-based media in open source media players, and allowing researchers to use open assets to create new tools and works including critical editions, annotated oral histories, musical works with thematic markup, and more.
IIIF Announces Final Release of 3.0 Specifications
Cette semaine, Google dévoilait une nouvelle fonctionnalité qui permet de spécifier les informations relatives à la licence d’utilisation d’une image: licence payante, Creative Commons. Cette fonctionnalité permet d’utiliser le langage de balisage Schema.org (appelé « données structurées » par la plateforme) ou les métadonnées IPTC qui sont incrustées dans les fichiers des photos numériques.
L’un des moyens permettant d’indiquer à Google qu’une image peut être concédée sous licence consiste à ajouter des champs de données structurées. Ces données structurées représentent un format normalisé permettant de fournir des informations sur une page et de classer son contenu.
Licence d’image dans Google Images (BÊTA)
Pourtant, plus de vingt ans après la naissance du web, la conception de sites est encore largement influencée par la production de documents imprimés. Si la forme et le design se sont adaptés aux modes et aux supports, la structure et la conception de l’information n’ont pas bougé. Nos sites sont encore conçus pour être lus par des humains.
Voici quelques éléments qui sont essentiels pour faciliter le repérage d’entités (personnes, organisations, œuvres, lieux, événements) par des moteurs de recherche et autres applications.
Un site web est au centre d’un écosystème numérique. C’est une adresse où se trouve de l’information accessible selon des standards universels et ouverts. C’est également un espace de publication qui n’est pas assujetti à d’autres objectifs que ceux de son propriétaire. Constitué de pages et de documents reliés entre eux et à d’autres sites web par des hyperliens, il peut se trouver sur le parcours d’utilisateurs et de moteurs de recherche. Un site web marque l’existence d’une entité dans cette application qui opère sur l’Internet et qui s’appelle le Web.
Ne compter que sur des réseaux sociaux pour avoir une présence numérique est une pratique qui réduit le potentiel de rayonnement et de découverte de nos contenus culturels.
Le développement des moteurs évolue rapidement vers le repérage et l’interprétation d’entités nommées (noms propres ou expressions définies comme un événement) dans des données non structurées. Pour faciliter le repérage d’un événement ou d’une œuvre, il faut lui attribuer une page spécifique. Publier plusieurs offres dans la même page ne permet pas à une machine de traiter adéquatement l’information qui y est présente. L’unicité et la persistance de l’URL signalent la présence d’une entité «événement» ou «œuvre» qui est liée à l’entité organisation.
L’intégration des balises du vocabulaire Schema.org permet d’identifier des types d’offres et de générer des aperçus, ou résultats enrichis, dans certains cas d’usage (expressément non garanti par Google). Celles-ci ne permettent cependant pas aux moteurs de recherche de différencier une offre d’autres offres similaires. Ce sont alors des mots (description, titre, caractéristiques) qui peuvent générer des liens entre l’information recherchée par des utilisateurs et les données non structurées qui sont présentes dans la page web.
Le choix des mots employés est stratégique parce que ceux-ci peuvent être utilisés pour fournir une réponse plus précise à une question (et cela, tant dans le contenu d’une page que dans le balisage qui est intégré dans son code HTML). Il s’agit d’établir des connexions avec les vocabulaires et intérêts des publics cibles et de rendre le contenu indexé unique ou le distinguer d’autres contenus similaires.
Parmi les conditions qui facilitent le traitement de l’information par les moteurs de recherche, on ignore trop souvent celles qui concernent les images. Une page qui comprend une image sera préférée à une autre qui n’en a pas. Si des liens, dans le code HTML de la page, fournissent un accès à des fichiers contenant trois résolutions de cette image (1X1, 4X3, 16X9), le contenu sera assurément exploitable. dans des résultats de recherche et sur de petits écrans. Notez que l’optimisation des images est automatiquement prise en charge par certains systèmes de gestion de contenu et certains thèmes de WordPress.
Nommer le fichier d’une image en utilisant des mots qui sont pertinents avec la description de son contenu en facilite l’exploitation et la gestion.
Ne pas faire de liens, hors d’un site web, afin d’y retenir les internautes nuit au rayonnement. Le déploiement de liens entre les acteurs concernés par la création, production et diffusion d’un contenu culturel souligne la présence numérique de chacun. La simple présence de liens vers des sources d’information externes enrichit l’information tout en favorisant des découvertes. Par exemple, relier des entités nommées autour d’une production audiovisuelle (œuvres musicales, lieu historique, réalisatrice et d’acteurs) améliore leur potentiel d’être découvertes par des humains et des machines.
Le rayonnement et la découverte de nos contenus culturels sur le web dépendent, avant tout, de l’organisation et de la structure de l’information sur nos sites web. Ne pas avoir son propre site, c’est ne pas faire partie du web ouvert, interopérable et de plus en plus interprétable par des machines. C’est également laisser à d’autres le soin de parler de vous. Mais, c’est surtout, renoncer aux moyens les plus simples et accessibles (vous rappellez-vous les blogolistes ou « blog roll » ?) que nous ayons pour relier les personnes, les organisations, les œuvres, les événements et les lieux, sur nos territoires et sur tout le Québec.
Mais si l’amélioration de la qualité de l’information numérique repose sur de meilleurs sites web, faudrait-il alors revoir les programmes de financement qui en excluent le développement ?
Les fournisseurs de services web ne sont-ils pas en première ligne lorsqu’il s’agit de conseiller et de réaliser des projets pour les acteurs culturels ? La même question se pose concernant les exigences de découvrablité des programmes de financement. Où sont les compétences nécessaires pour offrir un accompagnent qui soit susceptible d’apporter des améliorations notables ?
En l’absence de connaissances formalisées et de méthodes pédagogiques pour améliorer la littératie de l’information numérique (car c’est bien de cela dont il s’agit), le milieu culturel est laissé à lui-même. Il fait face à une variété d’interprétations, d’approches et de propositions stratégiques et technologiques dont il n’est pas en mesure d’évaluer l’exactitude, la pertinence ou le rendement potentiel.
Il serait donc urgent de réunir des représentants des domaines des sciences de l’information et des technologies numériques, des secteurs industriels et académiques, afin de proposer une mise à jour des compétences et des formations.

Notre focalisation sur le marketing et les solutions technologiques est-elle un risque pour la diversité culturelle ? L’absence de vision partagée et la course aux résultats peuvent-elles faire perdre aux acteurs de la culture la maîtrise stratégique des choix en matière de diffusion et d’accès ?
Nous espérons des solutions mécanistes qui accroîtront la consommation en imposant des offres culturelles à la façon des vieux modèles publicitaires. La mise en données de contenus culturels ne doit pas nous faire oublier qu’il appartient à chacun de réaliser la partie la plus stratégique d’un projet numérique : décider de la façon dont une chose (une œuvre, par exemple) doit être documentée et déterminer ce qui la relie à d’autres informations dans le web des données.
L’emploi du mot « initiative », de préférence à « projet », souligne l’importance de la démarche et des apprentissages, par rapport à la livraison d’un outil ou la modernisation d’un système. Voici comment nos initiatives pourraient être plus marquantes.
Le marketing peut entraîner la consommation de produits et services culturels, mais ce sont l’éducation et l’accès à la culture qui peuvent faire découvrir et apprécier la culture. Or, il faudrait une plus grande porosité entre les politiques et projets éducatifs et culturels pour miser sur l’environnement familial et social pour faire connaître la culture.
Il faudrait également donner un rôle plus actif, dans nos plans et initiatives numériques, aux médiateurs de proximité que sont les professionnels des bibliothèques publiques et scolaires.
Nous cherchons, par tous les moyens, à ce que la culture locale soit vue et consommée, de préférence à d’autres offres. Nos propositions techniques partagent cependant les défauts des plateformes dominantes. Qu’il s’agisse de baliser des contenus pour les moteurs de recherche ou de créer de nouvelles bases de données interrogeables, la façon dont sont conçues ces « solutions » technologiques nuit à la diversité des offres culturelles.
À l’arrivée de l’informatique, nous avons confié l’organisation de l’information à des systèmes de bases de données, selon les termes d’entreprises. Il est temps de remettre, selon nos propres termes, cette intelligence dans nos sites web et, plus spécifiquement, dans nos catalogues, collections, répertoires, fonds et archives. Nous ne devrions pas abandonner la création de sens et de liens à des opérateurs de plateformes et à des fournisseurs de services.
Être trouvé ou découvert et laisser des traces numériques sont les fruits d’un travail de documentation. Celui-ci est trop souvent escamoté par la recherche d’une solution technologique. De plus, les façons de décrire des productions ou des offres culturelles offrent peu de possibilité de mettre celles-ci en relation avec des intérêts et des passions.
Par exemple, les catalogues et répertoires en ligne pourraient grandement améliorer l’expérience des utilisateurs en devenant des bases de connaissances interactives et interconnectées. Il serait ainsi possible d’intégrer de nouvelles informations et des liens vers d’autres ressources grâce aux contributions de chercheurs et d’amateurs.
Documenter la culture et rendre cette information pertinente, attrayante et utile pour divers publics et usages sont la responsabilité de tous les acteurs du milieu culturel. Il manque une méthode de travail et des outils faciles à utiliser pour réaliser, en équipe ou avec des partenaires, l’évaluation de l’information publiée sur le web et le choix des métadonnées qui feront des liens entre les offres culturelles et les publics cibles.
C’est dans cette perspective qu’a été conçu un guide destiné aux artistes et aux organisations du milieu de la danse. Cette approche, en trois étapes (stratégie, information, technologie) repousse les choix technologiques à la toute dernière étape afin de remettre la documentation de la danse à ceux et celles qui la font.
Extraits du lancement du guide Bien documenter pour favoriser la découverte en ligne, réalisé pour la Fondation Jean-Pierre Perreault, dans le cadre de l’initiative La danse dans le web des données.
Mise à jour 2019-10-02: ajout d’un exemple récent d’initiative à fort potentiel transformateur.
La tendance zéro clic se confirme. Les moteurs de recherche fournissent dans leurs propres interfaces, des réponses, à partir de données collectées sur des sites web. Ils sont ainsi les principaux bénéficiaires de l’information que nous structurons afin de rendre nos offres plus visibles.
De plus, en développant des interfaces d’information spécialisées (voyage, musique, musées, entre autres), ils se substituent aux agrégateurs et portails traditionnels. Cette désintermédiation est particulièrement dommageable pour les structures locales qui produisent de l’information. Celles-ci sont privées de données d’usage qui leur permettraient de mieux connaître leur marché et de s’ajuster à leurs publics.
Donc, lorsque nous décrivons nos offres à l’aide de données structurées, sur le modèle Schema.org, et de services comme Google Mon entreprise, nous travaillons pour des moteurs de recherche. De plus, nous nous conformons à un vocabulaire de description, une classification et une vision du monde uniques. Ce constat est un problème pour la diversité culturelle, surtout pour les groupes ethniques et linguistiques en situation minoritaire.
Cependant, ne pas décrire nos offres avec des balises sémantiques équivaut à refuser de faire indexer nos pages web par les robots des moteurs et, par conséquent, à rendre nos offres et nos contenus invisibles et incompréhensibles pour Google, Bing, Yahoo! et Yandex (moteur de recherche russe).
Alors, que faire pour ne pas demeurer des fournisseurs de contenus et de données (voir l’exemple des musées virtuels sur Google Arts & Culture) ?
Tout d’abord, il faudrait donner un « service minimum » aux moteurs de recherche en fournissant uniquement l’information qui est exigée pour certaines offres. Google publie des instructions concernant les balises à renseigner, ainsi que les éléments de contenu à publier pour divers types d’offres.
Attention, Schema.org n’est qu’un vocabulaire. Ce n’est pas Google. Les moteurs de recherche exploitent les balises selon leurs propres règles. Celles-ci évoluent fréquemment, notamment, pour certains types de contenus. Par exemple, Google annonce clairement ses préférences, dans le domaine du livre, en réservant son attention aux distributeurs qui utilisent les balises selon ses instructions.
Nous mettons les moteurs de recherche et plateformes commerciales au centre de nos projets. Cependant, nous n’en maîtrisons pas le fonctionnement et nous n’avons aucun moyen de contrôle sur leur développement. Nous y investissons beaucoup d’efforts afin de positionner nos offres dans l’espoir d’accroître la consommation.
Et si nous élargissions notre définition de la découverte plutôt que de la centrer sur des activités de promotion? Ne pas nous limiter à la finalité économique de l’utilisation des données nous permettrait d’en embrasser le plein potentiel pour le développement de la culture et de l’éducation. Si nous choisissions de développer des initiatives en dehors des systèmes contrôlés par les acteurs dominants de l’économie numérique, nous pourrions être plus ingénieux et, finalement, créer plus de valeur pour nos propres écosystèmes.
Il y a 25 ans, ce 1er octobre, Tim Berners-Lee fondait le World Wide Web Consortium pour permettre à une communauté mondiale de développeurs et spécialistes divers de collaborer afin de définir des standards pour maintenir un web ouvert, accessible et interopérable pour tous.
Accroître le potentiel de la découverte passe par la décentralisation de la gestion de l’information, le partage de connaissance sous forme de données ouvertes et liées, selon les standards du web et par une redistribution plus équitable du pouvoir décisionnel. Wikipédia, Wikicommons et Wikidata, qui sont des projets de la Wikimedia Foundation, exemplifient ce modèle contributif qui donne à chacun la possibilité de participer au contenu et à la gouvernance.
Tous les acteurs du domaine culturel n’ont pas les compétences et les ressources requises pour évaluer, modéliser et connecter des données avec les technologies du web sémantique. Wikidata constitue une option plus accessible: le référentiel, le mode de gouvernance et l’infrastructure n’ont pas à être développés. Ceci a pour principal avantage d’expérimenter rapidement la production et l’utilisation de données liées.
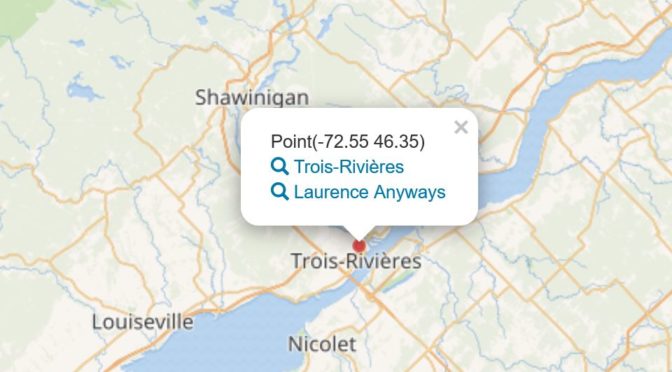
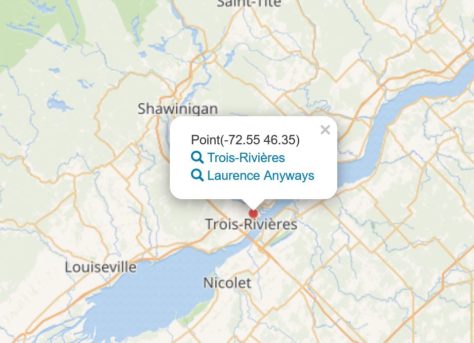
Les requêtes préconstruites qui permettent d’interroger les données de Wikidata offrent un aperçu du potentiel d’un projet contributif pour la valorisation de l’information. Par exemple, la requête 6.16 qui permet de cartographier tous les films en fonction du lieu où se déroule l’action. Lancez la requête en cliquant sur le pictogramme (flèche blanche sur fond bleu) à la gauche de l’écran. Les données des films localisés au Québec ne sont pas exhaustives et sont souvent imprécises (information incomplète, lieu fictif).
Si d’autres sources d’information étaient disponibles sous forme de données liées, on pourrait imaginer une interface où se croiseraient des images des lieux, des biographies d’acteurs et actrices ou des titres de chansons.
*** Mise à jour 2019-10-02
Voici un autre exemple d’initiative qui prend sa source hors des règles imposées par les moteurs de recherche et plateformes. Il s’agit de projets réalisés avec Wikipédia par le Musée national des beaux-arts du Québec. Cette initiative est à la fois, une contribution du musée à la connaissance mondiale, tout en permettant à l’institution d’explorer le potentiel du liage de données, de rejoindre des publics qui ne fréquentent pas de musées et de donner prise à une culture du réseau dans l’organisation. Nathalie Thibault, archiviste au MNBAQ, en mentionne les effets marquants:
Un des impacts positifs de ce chantier a été de bonifier la présence d’œuvres dans des collections d’autres musées au Québec et au Canada dans les articles bonifiés et non pas juste le MNBAQ. Nous souhaitons collaborer avec les autres musées du Québec, car les articles améliorés sur les artistes du Québec serviront certainement à d’autres institutions muséales.
***
En conclusion, il est souhaitable que nous ayons une alternative aux grandes plateformes pour développer nos compétences et mettre en valeur nos collections, catalogues, fonds et portfolios. Il faut cependant favoriser les initiatives qui ciblent des résultats marquants et transmissibles tels que la décentralisation des prises de décision, l’abolition des silos organisationnels et la mise en commun de données.
Google annonce un changement à son algorithme afin de promouvoir le journalisme d’enquête.
Mais ceci servira surtout à améliorer la quantité de données contenues dans son graphe de connaissances (knowledge graph) et d’étendre son influence sur ce que nous voyons sur le web.
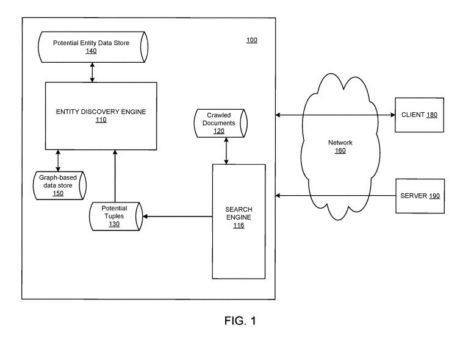
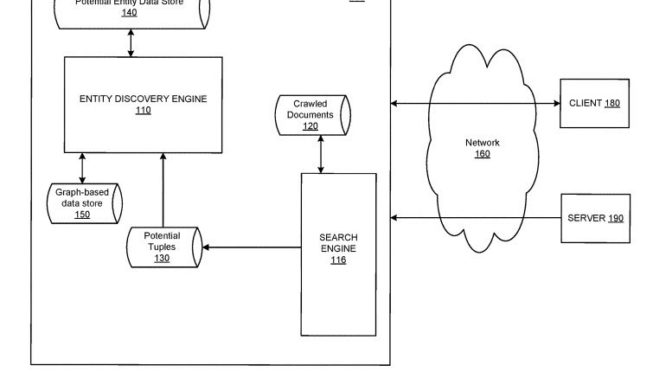
Bill Slawski est un spécialiste de l’optimisation pour moteurs de recherche. Sa formation de juriste lui permet de porte une attention particulière aux demandes de brevet. Il en commentait une, récemment, qui fait référence au développement du graphe de connaissances (knowledge graph) de Google. Elle concerne l’intégration, dans son graphe, d’information collectée sur le web, afin d’accroître la masse de données :
The patent points out at one place, that human evaluators may review additions to a knowledge graph. It is interesting seeing how it can use sources such as news sources to add new entities and facts about those entities.
Comme chez les autres entreprises dont le modèle d’affaires repose sur la donnée, une grande partie du traitement de l’information et de la production de données résulte du travail non rémunéré d’amateurs et passionnés:
How can you teach an algorithm to understand all these distinctions? Gingras said Google is doing so through its Quality Raters, a global network of more than 10,000 individuals who offer feedback on Google’s search results, which in turn is used to improve the company’s search algorithms.
Google says it will do more to prioritize original reporting in search
Ceci sert-il les intérêts du journalisme ? Probablement, mais il est trop tôt pour le vérifier. Cela sert surtout à développer une connaissance très poussée de nos rapports à l’information et de permettre à d’autres d’influencer notre vision du monde et de fabriquer des opinions. S’informer sur le scandale Facebook – Cambridge Analytica devrait nous faire prendre la mesure de l’intervention de ces systèmes dans notre développement social, notamment, la fabrication d’opinions et d’antagonismes.