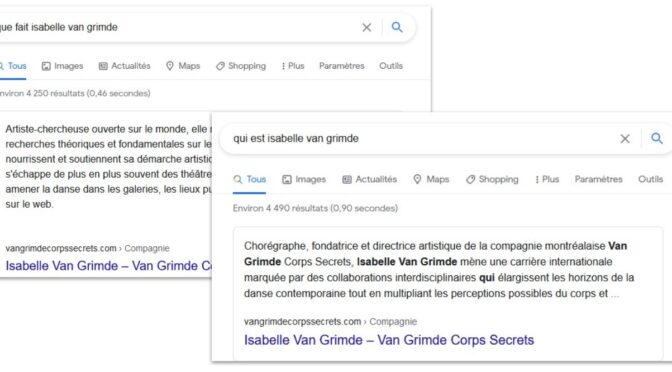
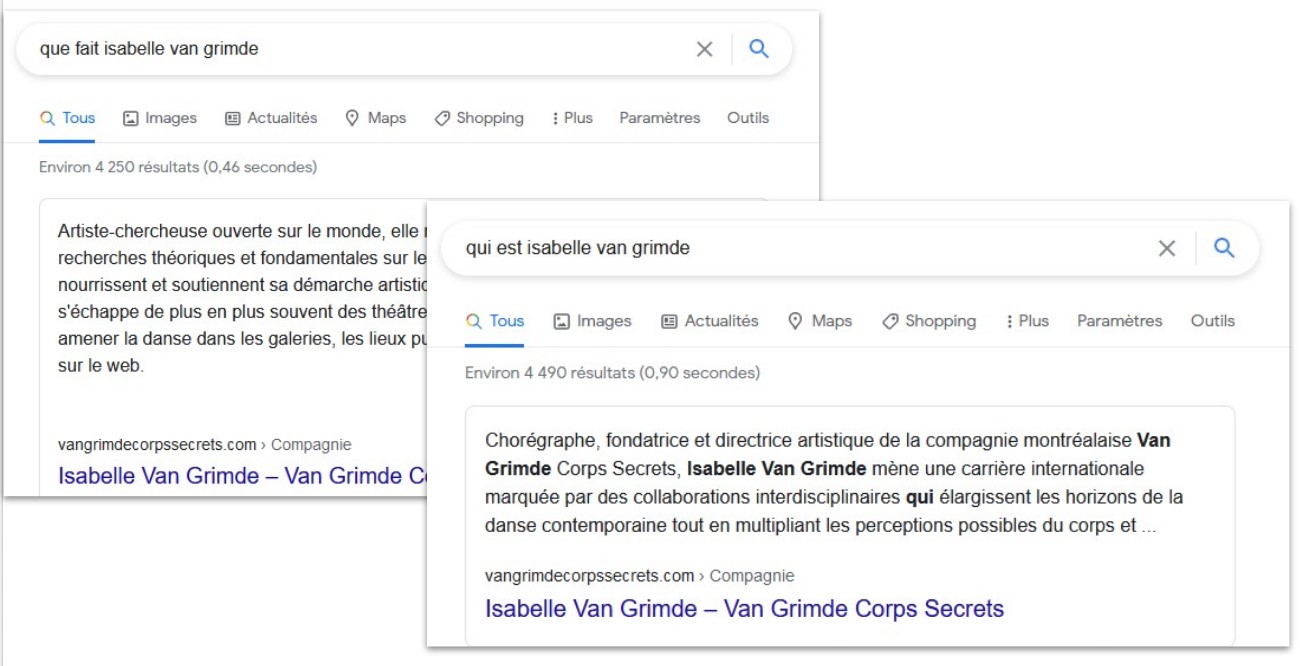
Je le répète: il faut retomber en amour avec nos sites web. Nous devons réinvestir le domaine du langage sur ces espaces numériques privilégiés que sont nos sites web.
L’hypertexte en réseau
Le World Wide Web dont c’est aujourd’hui l’anniversaire, est cette application de l’Internet qui permet de relier des éléments d’information pour former un hypertexte. Nos site web sont des espaces numériques privilégiés parce des standards universels et libres nous offrent la possibilité de publier et partager des contenus, indépendamment des règles des plateformes commerciales et sociales. Sur nos sites web, nous détenons un contrôle stratégique: décider de la façon de documenter une chose et faire des liens qui la place dans un écosystème de connaissances.
Afin de réduire l’angle mort de la promotion de la culture sur le Web, nous pourrions beaucoup mieux documenter nos offres sans nécessairement plonger dans des domaines de connaissances complexes.
Le Web des moteurs de recherche
De quelles machines est-il question ici? Il s’agit des moteurs de recherche qui indexent les pages web, ce qui exclut les plateformes pour lesquelles il faut ouvrir une session (Spotify, Netflix, les réseaux sociaux). À celles-ci, on peut ajouter le Web sémantique qui est une extension du Web permettant de relier des données. Ce sont des espaces numériques différents et qui font appel à des structures, règles et technologies spécifiques. Le Web des moteurs de recherche est celui des contenus accessibles, repérables et interopérables.
Wikidata permet de valider l’identification d’entités spécifiques et de fournir de l’information factuelle, comme une date de naissance. Cependant, c’est le contenu d’un site web qui contient le texte de la réponse à une question. Les moteurs de recherche analysent et évaluent, à présent, le texte des pages web afin d’en interpréter le sens avec certitude.
Rédiger pour des moteurs plus intelligents
L’information collectée sur les sites est mise en relation avec un système d’organisation de la connaissance qui permet de mieux interpréter une chose et d’enrichir la « compréhension » qu’a une machine de cette chose:
- Interprétation: de quoi est-il question?
- Classification: de quel type de chose s’agit-il?
- Contexte: à quels autres types de choses/personnes est-ce relié?
Il faut lire l’article ci-dessous pour constater la rapidité du développement des systèmes d’analyse du langage (ce à quoi servent les graphes de connaissance). Cette évolution est en marche, que ce soit chez Google ou tout autre entreprise tirant profit de l’extraction de l’information.
It is clear that Google is moving rapidly toward a quasi-human understanding of the world and all its algorithms will increasingly rely on its understanding of entities and its confidence in its understanding.
▣ Jason Barnard. « Tracking Google Knowledge Graph Algorithm Updates & Volatility ». Search Engine Journal, 11 mars 2021.
Nous devons prioriser l’amélioration de nos sites web afin de nous rendre plus intelligibles, comme personne physique ou morale. Ceci permet de résister à une centralisation de l’information qui aplanit la diversité des expressions et des perspectives et de relier les acteurs de nos écosystèmes sans l’intervention d’algorithmes.
***
Alors, quelle serait la valeur informationnelle de votre site selon votre moteur de recherche favori?