Mise à jour 2019-10-02: ajout d’un exemple récent d’initiative à fort potentiel transformateur.
La tendance zéro clic se confirme. Les moteurs de recherche fournissent dans leurs propres interfaces, des réponses, à partir de données collectées sur des sites web. Ils sont ainsi les principaux bénéficiaires de l’information que nous structurons afin de rendre nos offres plus visibles.
Partenariat inéquitable
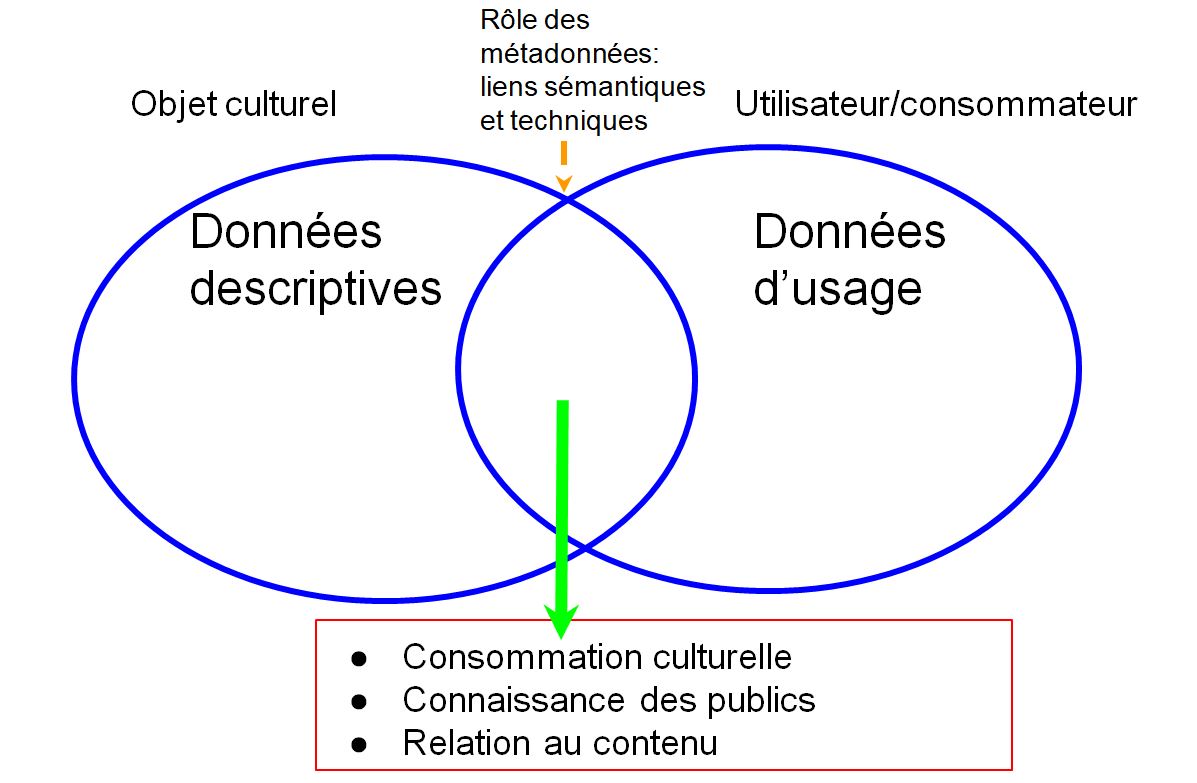
De plus, en développant des interfaces d’information spécialisées (voyage, musique, musées, entre autres), ils se substituent aux agrégateurs et portails traditionnels. Cette désintermédiation est particulièrement dommageable pour les structures locales qui produisent de l’information. Celles-ci sont privées de données d’usage qui leur permettraient de mieux connaître leur marché et de s’ajuster à leurs publics.
Effacement de la diversité culturelle
Donc, lorsque nous décrivons nos offres à l’aide de données structurées, sur le modèle Schema.org, et de services comme Google Mon entreprise, nous travaillons pour des moteurs de recherche. De plus, nous nous conformons à un vocabulaire de description, une classification et une vision du monde uniques. Ce constat est un problème pour la diversité culturelle, surtout pour les groupes ethniques et linguistiques en situation minoritaire.
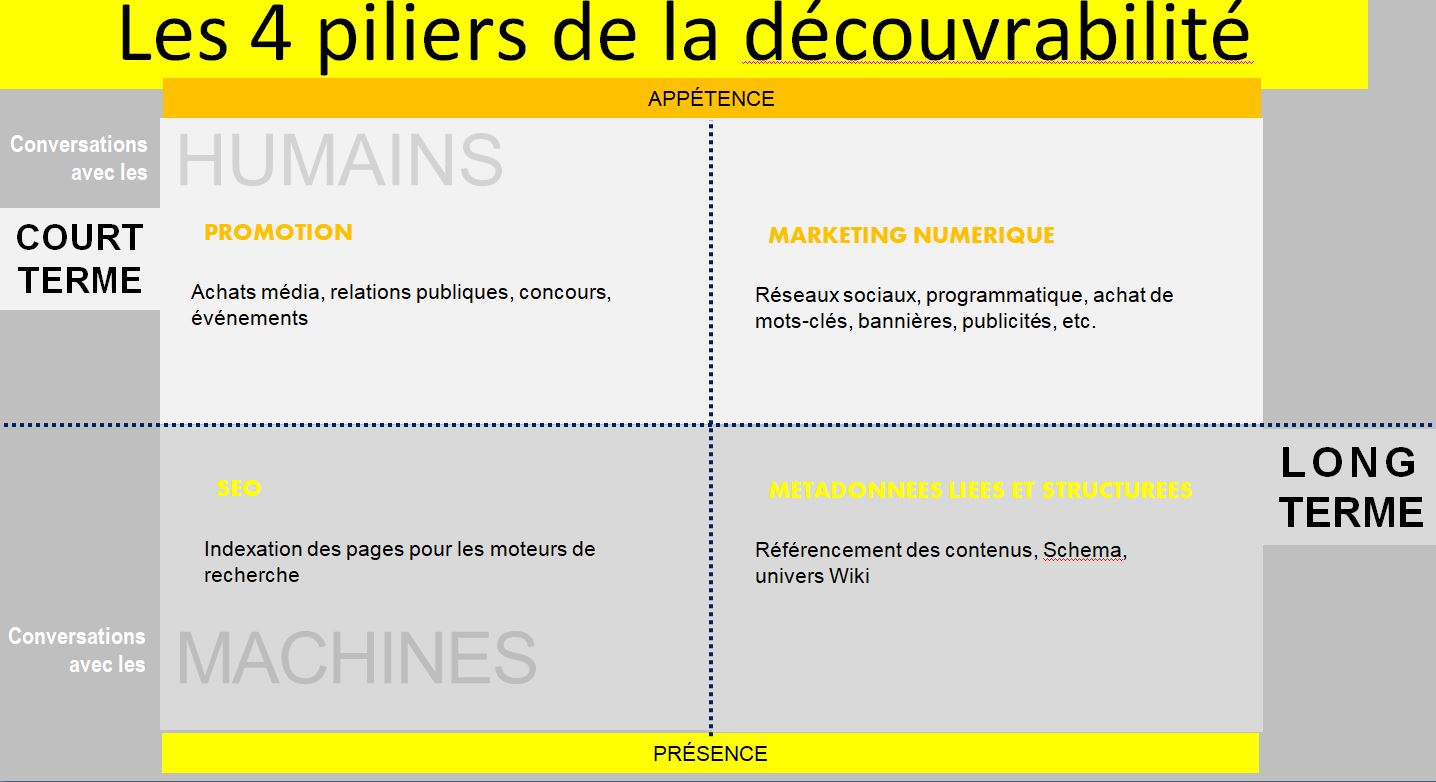
Que faire ? Fournir un service minimum
Cependant, ne pas décrire nos offres avec des balises sémantiques équivaut à refuser de faire indexer nos pages web par les robots des moteurs et, par conséquent, à rendre nos offres et nos contenus invisibles et incompréhensibles pour Google, Bing, Yahoo! et Yandex (moteur de recherche russe).
Alors, que faire pour ne pas demeurer des fournisseurs de contenus et de données (voir l’exemple des musées virtuels sur Google Arts & Culture) ?
Tout d’abord, il faudrait donner un « service minimum » aux moteurs de recherche en fournissant uniquement l’information qui est exigée pour certaines offres. Google publie des instructions concernant les balises à renseigner, ainsi que les éléments de contenu à publier pour divers types d’offres.
Attention, Schema.org n’est qu’un vocabulaire. Ce n’est pas Google. Les moteurs de recherche exploitent les balises selon leurs propres règles. Celles-ci évoluent fréquemment, notamment, pour certains types de contenus. Par exemple, Google annonce clairement ses préférences, dans le domaine du livre, en réservant son attention aux distributeurs qui utilisent les balises selon ses instructions.
Que faire d’autre ? Aller vers le web des données
Nous mettons les moteurs de recherche et plateformes commerciales au centre de nos projets. Cependant, nous n’en maîtrisons pas le fonctionnement et nous n’avons aucun moyen de contrôle sur leur développement. Nous y investissons beaucoup d’efforts afin de positionner nos offres dans l’espoir d’accroître la consommation.
Et si nous élargissions notre définition de la découverte plutôt que de la centrer sur des activités de promotion? Ne pas nous limiter à la finalité économique de l’utilisation des données nous permettrait d’en embrasser le plein potentiel pour le développement de la culture et de l’éducation. Si nous choisissions de développer des initiatives en dehors des systèmes contrôlés par les acteurs dominants de l’économie numérique, nous pourrions être plus ingénieux et, finalement, créer plus de valeur pour nos propres écosystèmes.
Apprendre à jouer collectif
Il y a 25 ans, ce 1er octobre, Tim Berners-Lee fondait le World Wide Web Consortium pour permettre à une communauté mondiale de développeurs et spécialistes divers de collaborer afin de définir des standards pour maintenir un web ouvert, accessible et interopérable pour tous.
Accroître le potentiel de la découverte passe par la décentralisation de la gestion de l’information, le partage de connaissance sous forme de données ouvertes et liées, selon les standards du web et par une redistribution plus équitable du pouvoir décisionnel. Wikipédia, Wikicommons et Wikidata, qui sont des projets de la Wikimedia Foundation, exemplifient ce modèle contributif qui donne à chacun la possibilité de participer au contenu et à la gouvernance.
Inventer d’autres formes de découverte
Tous les acteurs du domaine culturel n’ont pas les compétences et les ressources requises pour évaluer, modéliser et connecter des données avec les technologies du web sémantique. Wikidata constitue une option plus accessible: le référentiel, le mode de gouvernance et l’infrastructure n’ont pas à être développés. Ceci a pour principal avantage d’expérimenter rapidement la production et l’utilisation de données liées.
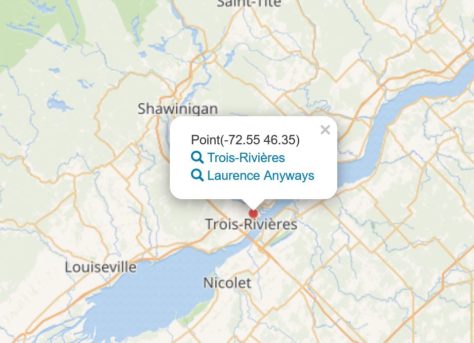
Les requêtes préconstruites qui permettent d’interroger les données de Wikidata offrent un aperçu du potentiel d’un projet contributif pour la valorisation de l’information. Par exemple, la requête 6.16 qui permet de cartographier tous les films en fonction du lieu où se déroule l’action. Lancez la requête en cliquant sur le pictogramme (flèche blanche sur fond bleu) à la gauche de l’écran. Les données des films localisés au Québec ne sont pas exhaustives et sont souvent imprécises (information incomplète, lieu fictif).
Si d’autres sources d’information étaient disponibles sous forme de données liées, on pourrait imaginer une interface où se croiseraient des images des lieux, des biographies d’acteurs et actrices ou des titres de chansons.
*** Mise à jour 2019-10-02
Voici un autre exemple d’initiative qui prend sa source hors des règles imposées par les moteurs de recherche et plateformes. Il s’agit de projets réalisés avec Wikipédia par le Musée national des beaux-arts du Québec. Cette initiative est à la fois, une contribution du musée à la connaissance mondiale, tout en permettant à l’institution d’explorer le potentiel du liage de données, de rejoindre des publics qui ne fréquentent pas de musées et de donner prise à une culture du réseau dans l’organisation. Nathalie Thibault, archiviste au MNBAQ, en mentionne les effets marquants:
Un des impacts positifs de ce chantier a été de bonifier la présence d’œuvres dans des collections d’autres musées au Québec et au Canada dans les articles bonifiés et non pas juste le MNBAQ. Nous souhaitons collaborer avec les autres musées du Québec, car les articles améliorés sur les artistes du Québec serviront certainement à d’autres institutions muséales.
***
En conclusion, il est souhaitable que nous ayons une alternative aux grandes plateformes pour développer nos compétences et mettre en valeur nos collections, catalogues, fonds et portfolios. Il faut cependant favoriser les initiatives qui ciblent des résultats marquants et transmissibles tels que la décentralisation des prises de décision, l’abolition des silos organisationnels et la mise en commun de données.



![Elliott Brown [CC BY 2.0], Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Perry_Barr_Station_-_Mind_the_Gap_(7851041352).jpg){kind=link}