C’est que nous avons pu constater au fil des présentations de la troisième édition du Colloque sur le web sémantique au Québec. Quelle que soit la nature de la problématique, du projet et du secteur d’activité considéré, tous les conférenciers ont fait état de changements nécessaires pour profiter des avantages du web de données.
Ces changements se manifestent à plusieurs niveaux: technologique, organisationnel, culturel, professionnel et structurel.
De fragmentation à intégration
Changement technologique – Le web sémantique permet de fournir des solutions aux problèmes d’interopérabilité des systèmes en affranchissant les données des environnements matériels et logiciels ne favorisant pas les interconnexions. Il devient donc essentiel, pour les professionnels de l’informatique, de se familiariser avec les graphes de données liées et d’adopter des standards ouverts qui permettent de sortir les données des silos des bases de données classiques. Ces nouvelles connaissances sont nécessaires à l’accompagnement des autres secteurs métiers et à ce que le service informatique contribue à l’élaboration d’une définition partagée des normes, règles et processus pour la qualité des données.
▷ Pour aller plus loin: démonstration très accessible des limites de la base de données classique et des possibilités qu’offre le graphe de données liées pour le traitement des connaissances, par Gautier Poupeau, architecte de données à l’Institut national de l’audiovisuel (INA), France.
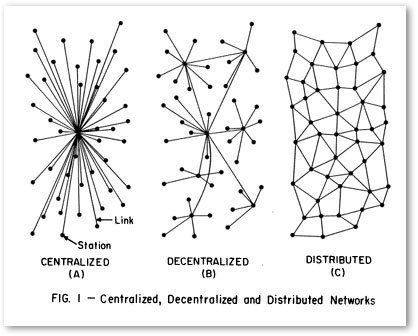
De centralisation à distribution
Changement organisationnel – Un projet de données liées (ou ouvertes et liées) est une démarche interdisciplinaire et collaborative. À l’image du Web, qui ne se développe pas de façon centralisée mais distribuée, la qualité des données devrait être une responsabilité partagée par toutes les fonctions d’une organisation.
Pour avoir des données et métadonnées utiles, il faut améliorer les compétences des personnes qui les produisent par l’apprentissage des bonnes pratiques — comme l’usage de référentiels communs pour catégoriser des documents et l’utilisation d’outils qui favorisent l’accessibilité et le partage de données. Ceci implique également, une maîtrise du cycle de vie des données (création/collecte, traitement, analyse, conservation, accès, réutilisation) par tous les services.
Dans cette même perspective, la résilience et les bons résultats d’un projet de données liées se fondent sur de nouvelles méthodes de travail qui visent la décentralisation des décisions relatives à l’identification des problématiques, à la priorisation des projets et à la proposition de solutions. C’est une étape clé vers l’adoption de systèmes distribués et de modes de direction et d’action plus agiles et plus propices à l’innovation que les structures hiérarchiques.
▷ Pour aller plus loin: conférence de Diane Mercier, docteure en sciences de l’information, sur le web sémantique et la maturité informationnelle de l’organisation (2016). Après une véritable transformation numérique, la prise en charge de la qualité des données n’est plus uniquement du ressort de l’informatique, mais de tous les métiers et la gouvernance des données n’est plus fragmentée, mais globale.
D’uniformisation à harmonisation
Changement culturel – Lorsque différents acteurs internes et externes sont appelés à contribuer à la production de données liées, il n’est pas rare d’assister à une confrontation des savoirs, des perspectives et des vocabulaires utilisés. Pourtant, dans un projet de données liées, plusieurs modèles, standards et vocabulaires peuvent cohabiter dans un même système pour autant que ceux-ci soient conformes aux normes techniques du web sémantique. Il ne s’agit pas d’uniformiser les façons de décrire des ressources, mais de normaliser les référentiels pour les rendre interopérables, la diversité des perspectives venant alors enrichir la connaissance que nous avons de ces ressources.
Il est d’autant plus important d’accueillir cette diversité des pratiques descriptives que, dans divers domaines allant de la muséologie aux administrations publiques, nous sommes amenés à prendre conscience des biais culturels véhiculés par les différents modèles de représentation et de classification en usage au sein des organisations.
▷ Pour aller plus loin: exemple d’ONOMA, un projet du Ministère de la Culture et de la Communication (France) visant à lier les différents référentiels qui décrivent des auteurs, créateurs, producteurs et personnalités intervenant dans le cycle de vie d’un bien culturel. Une démarche d’harmonisation similaire peut être mise en œuvre dans bien d’autres domaines.
De technocentrisme à interdisciplinarité
Changement professionnel – Comment des spécialistes des TI et des sciences de la donnée peuvent-ils travailler sur le traitement de la connaissance d’un domaine hors de leur champ de compétences? Un projet web sémantique comporte des défis de nature technique et conceptuelle pour lesquelles il est impératif de rassembler une diversité de perspectives et d’expertises. Notamment, en ce qui a trait à l’organisation et au traitement de l’information, comme l’indexation de documents, la modélisation des connaissances ou la linguistique.
▷ Pour aller plus loin: billet de Fred Cavazza, spécialiste des transformations numériques, sur le rôle central des experts métiers dans des projets de traitement de données, dont des systèmes d’intelligence artificielle.
Du court terme au long terme
Changement structurel – Les programmes qui soutiennent organismes et secteurs d’activité sont généralement orientés vers l’atteinte de résultats à court terme. Or, il ne faut pas attendre de résultats immédiats de projet de données liées. Il y a donc peu d’incitatifs, pour les organisations, à réaliser des projets leur permettant d’entrer dans l’économie de la connaissance. Pour ce faire, il faut adapter les politiques et programmes afin d’encourager les investissements à moyen et long termes. Ceux-ci donneront lieu à des initiatives telles que des preuves de concept ou des prototypes, préalables nécessaires de projets plus ambitieux.
▷ En résumé – Le web sémantique ne constitue pas uniquement une évolution technologique mais avant tout une transformation profonde des modes de gestion de l’information et de gouvernance des données. Il nécessite la mise en place de nouvelles façons de travailler, tant pour la décentralisation des prises de décision que pour l’abolition des silos informationnels et la mise en commun de l’information.
Transformation pour un monde numérique
Le web sémantique nous amène à envisager le numérique comme un écosystème d’acteurs métiers et de moyens technologiques interdépendants. Contrairement aux projets informatiques « traditionnels », il nécessite l’aménagement d’un environnement d’apprentissage collaboratif et de conversations transversales dans l’organisation. Sa finalité est de faire émerger l’intelligence collective permettant de produire de la connaissance et non de développer des systèmes.