En culture comme en commerce, les initiatives de mise en commun de données numériques, constituent de nouveaux « milieux documentaires ». Au Québec, pourtant, les compétences et méthodes du domaine des sciences de l’information sont rarement sollicitées. Les institutions d’enseignement et les associations professionnelles concernées devraient pourtant reconnaître, dans ces projets, les notions et enjeux entourant les systèmes documentaires classiques.
Continuer la lecture de Nouveaux milieux documentaires en manque de spécialistes des sciences de l’informationArchives par mot-clé : modèles

Comment faire un plan de « découvrabilité » pour des résultats mesurables

Depuis peu, en culture, on retrouve un volet « découvrabilité » dans la plupart des appels à projets. S’agit-il d’une application technologique, de techniques de référencement ou d’une campagne de promotion numérique? L’absence d’explications concrètes et de description des compétences requises met les demandeurs (ainsi que les bailleurs de fonds!) dans une situation où ils ne disposent pas des guides nécessaires pour savoir ce qu’il faut faire, ni quels résultats escompter.
Un projet dans un projet
Assurer la repérabilité d’une nouvelle création ou d’une nouvelle offre est un projet à part entière, avec ses ressources, ses objectifs et ses réalisations. Il ne s’agit pas de mettre en commun ce que chacun aura produit de son côté, mais de produire des contributions s’alimentant les unes des autres. C’est pourquoi, dans nos velléités de transformation numérique, le travail en silo est un frein à la réussite de nos projets.
Les mots qui font des connexions
C’est l’information fournie à propos des choses qui est repérable — pas les choses en elles-mêmes. Cette distinction est extrêmement importante puisque c’est le choix des éléments descriptifs qui retient l’attention d’audiences cibles et qui permet aux moteurs de recherche de connecter des offres à des intentions et des profils d’utilisateurs.
Sous le couvert nébuleux de la découvrabilité, il existe en réalité des pratiques et des standards permettant de structurer l’information pour le Web afin d’en assurer la repérabilité, l’accessibilité et l’interopérabilité.
Google ne parle pas web sémantique
Représenter des connaissances avec les technologies du web sémantique (URI, RDF…) et structurer de l’information pour des moteurs de recherche sont des projets différents qui n’ont pas les mêmes finalités.
Si votre objectif est de faire découvrir votre offre culturelle en vous servant, entre autres, des moteurs de recherche pour générer des visites, des visionnements ou des achats, le web sémantique ne vous sera d’aucune utilité!
Google n’exploite que le langage de balisage Schema.org…
Pour un plan de découvrabilité plus efficace
Voici les éléments de réflexion qui apporteront plus d’efficacité à votre plan de découvrabilité. La grande lacune de la plupart des plans de découvrabilité est l’absence ou la faiblesse de la stratégie — comment pousser les bons contenus aux bons publics, sur les bons canaux, pour atteindre des objectifs mesurables. Or, ce travail est essentiel à plusieurs titres:
1 – Connaître les publics et fixer des objectifs
À quels besoins et à quels publics votre offre est-elle susceptible de répondre? Les objectifs à atteindre doivent être déterminés en fonction des intérêts et comportements de ces publics cibles ainsi que de leurs possibles relations à l’offre.
2 – Différencier votre offre
Le vocabulaire Schema.org permet de fournir une description détaillée d’une offre culturelle. Google n’en utilise cependant que certains éléments. Baliser une offre de spectacle n’est pas suffisant pour permettre à celle-ci de se différencier de milliers d’autres offres. La connaissance des publics fournit les éléments d’information et le vocabulaire pouvant aider les moteurs de recherche à faire des connexions entre les intentions et profils des utilisateurs et les offres disponibles.
3 – Faire travailler des spécialistes ensemble
Les balises et le référencement par mots clés sont des outils complémentaires s’appuyant sur la stratégie de promotion. Accroître la découverte commence par la présentation de l’offre sur le site web . Ceci a pour but de faciliter le travail des moteurs de recherche et d’améliorer l’expérience de l’utilisateur avec leur interfaces.
4 – Relier les acteurs de l’écosystème
Si un site web est absolument essentiel et stratégique, d’autres présences numériques contribuent au rayonnement d’une offre. Une bonne stratégie met donc à contribution les acteurs de l’écosystème en identifiant des points d’entrée (réseau social, vidéo, site partenaire, etc.) et en multipliant ainsi les parcours de découverte.
5 – Ne pas compter uniquement sur Google
En se contentant de produire des métadonnées sous forme de balises Schema.org, on se conforme aux modèles et directives qui répondent avant tout aux objectifs d’affaires d’un géant du numérique. Bien que le balisage d’offres pour les moteurs de recherche fasse partie des bonnes pratiques web, Google ne garantit aucun résultat (longue lecture, mais excellent billet).
Attention: les métadonnées ne sont pas toujours utiles. Si vous souhaitez améliorer la valeur de votre site pour Google, corrigez les lacunes de conception et améliorez la valeur du contenu rédactionnel.
6 – Mesurer l’atteinte des objectifs
Finalement, la découverte d’offres culturelles sur un moteur de recherche est difficilement mesurable. Elle dépend de plusieurs facteurs extrêmement variables, comme le profil, l’intention présumée par l’algorithme et les usages antérieurs de chaque utilisateur. Ce sont donc les objectifs et indicateurs de mesure ayant été déterminés dans le plan stratégique qui permettront d’évaluer la réussite de celui-ci.
Utiliser des métadonnées sans tomber dans le solutionnisme
Ce ne sont pas les métadonnées qui produisent des résultats, mais les moyens déterminés par la stratégie. Il faut donc proposer des initiatives plus marquantes pour la diffusion et l’appréciation de nos offres culturelles. Par exemple, renouveler l’expérience de recherche sur un site en présentant l’information sous forme de fiches, de façon similaire à Google, mais selon d’autres règles que la popularité et la similarité.
Il n’existe pas de recette. Chaque projet étant unique, il doit se différencier pour se démarquer, et ce grâce au choix des canaux, plateformes, mots, images et liens adressés aux bons publics.
Surtout, il ne faut pas se contenter d’appliquer les consignes de Google. On doit également chercher à comprendre l’interaction complexe des systèmes et identifier les éléments stratégiques que nous pouvons contrôler.
Enfin, nous ne pouvons pas encourager le milieu culturel à se conformer à un système dont nous ne comprenons pas le fonctionnement et dénoncer, dans le même temps, la domination et l’opacité des GAFAM. Cette contradiction en dit long sur les connaissances qu’il nous reste à acquérir…
Faire parler les images: repérabilité et interopérabilité des métadonnées

Les images sont des éléments d’information et des données. Elles améliorent le repérage d’entités (personnes, organisations, œuvres, lieux, événements) dans des pages web. Elles contribuent au développement de nouveaux parcours de découverte. À titre d’exemple, nous pouvons mentionner le moteur de recherche Google Images (créé en juillet 2001) et Wikimedia Commons où sont déposées un nombre grandissant d’images, dont celles de galeries d’art, pour en favoriser la réutilisation.
Voici deux annonces récentes qui devraient sensibiliser les éditeurs de sites web et professionnels du numérique à l’importance de documenter les images et/ou d’adopter de meilleurs pratiques.
IIIF (International Image Interoperability Framework)
D’abord, le mois dernier, IIIF annonçait que l’annotation des images s’étend désormais aux images des contenus audio et images en mouvement (vidéo, film). De plus, lIIF rend son modèle compatible avec l’écosystème des données liées en passant du modèle Open Annotation aux standards du Web (W3C Web Annotations) et en facilitant l’usage du langage JSON-LD pour exprimer les données. IIIF est un format de transmission de données: il ne permet pas de gérer des collections.
A critical element of this release is the ability to move beyond static digital images to present and annotate audio and moving images. This is done by adding duration to the existing IIIF canvas model, which also features x and y coordinates as means of selecting and annotating regions. Now, images and video can be juxtaposed using open source software viewers — allowing the public to view time-based media in open source media players, and allowing researchers to use open assets to create new tools and works including critical editions, annotated oral histories, musical works with thematic markup, and more.
IIIF Announces Final Release of 3.0 Specifications
Google Images
Cette semaine, Google dévoilait une nouvelle fonctionnalité qui permet de spécifier les informations relatives à la licence d’utilisation d’une image: licence payante, Creative Commons. Cette fonctionnalité permet d’utiliser le langage de balisage Schema.org (appelé « données structurées » par la plateforme) ou les métadonnées IPTC qui sont incrustées dans les fichiers des photos numériques.
L’un des moyens permettant d’indiquer à Google qu’une image peut être concédée sous licence consiste à ajouter des champs de données structurées. Ces données structurées représentent un format normalisé permettant de fournir des informations sur une page et de classer son contenu.
Licence d’image dans Google Images (BÊTA)
Découvrabilité: mythes et réalité
Mise à jour 2019-05-24: ajout d’une question et sa référence, en conclusion.
La recherche du Graal de la découvrabilité, ce moyen qui accroîtra la «consommation» de nos produits culturels, peut-elle nous faire tomber dans le piège de la solution technologique qui nous fait oublier le problème ?
Solution simple et problématique complexe
Appelé « solutionnisme » par l’historien des sciences Evgeny Morozov, c’est la proposition d’une solution technologique à un problème d’origine complexe. Ceci a pour effet d’escamoter les débats qui sont essentiels à la recherche de solutions pour le bien commun.
Moins de quatre ans se sont écoulés depuis le sommet qui a propulsé le terme « découvrabilité » jusque dans les hautes sphères décisionnelles, en culture. Depuis lors, des événements et programmes de financement de la culture ont intégré cette thématique ou certains de ces éléments les plus emblématiques, comme les métadonnées.
Je réalise, depuis quelques années, des ateliers sur la découvrabilité et les métadonnées, avec les Fonds Bell et Fonds indépendant de production. Une collaboration avec Marie-Ève Berlinger apporte à ma démarche exploratoire la dimension stratégique de la promotion numérique. C’est dans ce contexte que nous avions échangé sur les mythes de la découvrabilité, au cours du Forum avantage numérique.
Voici quelques constats qui se rapportent aux mythes qui sont spécifiques à la production de métadonnées pour les moteurs de recherche.
La découvrabilité n’est pas une finalité
La finalité d’un plan de découvrabilité est le fruit d’une réflexion stratégique. Celui-ci fournit les questions, le contexte et le cadre sans lesquels la découvrabilité n’aurait pas d’autre objectif que de fournir des données à un moteur de recherche. Ce sont les activités de marketing et de promotion qui produisent des résultats mesurables.
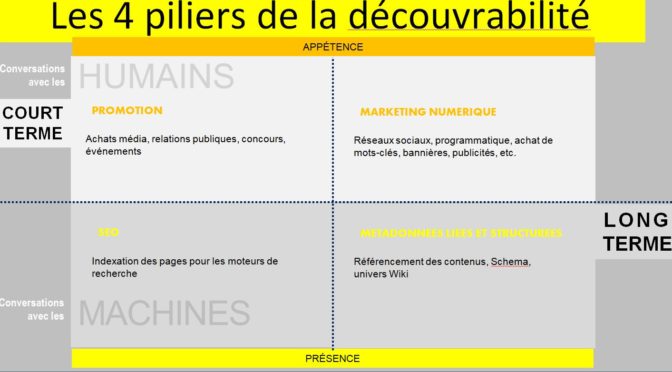
L’exploitation des métadonnées par les moteurs de recherche n’est qu’un des piliers de la découvrabilité. Cette approche a été illustrée dansle cadre d’un projet auquel je collabore, avec Véronique Marino et Andrée Harvey (La Cogency).
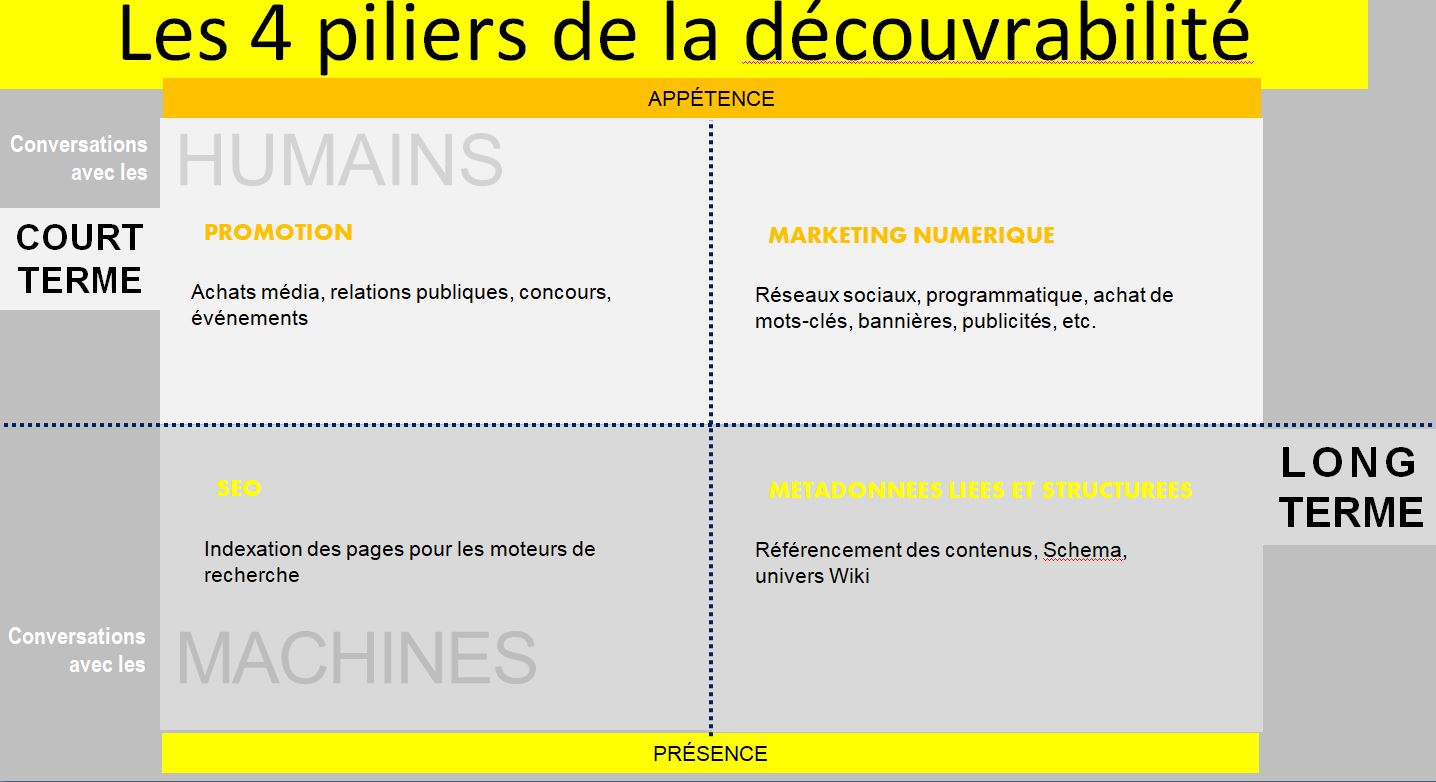
Il est surprenant de constater que la stratégie et les moyens techniques ne sont pas intimement intégrés dans des projets numériques. Il y a une importante mise à jour des connaissances conceptuelles et techniques à opérer au sein des agences qui conseillent et accompagnent les organismes et entreprises.
La réponse n’est pas une page web
La fiche d’information qui constitue la réponse du moteur de recherche (à la droite de la liste de résultats) n’a pas pour objectif de diriger l’utilisateur vers une page web spécifique. Elle rassemble différents éléments d’information afin de fournir la réponse la plus précise possible. Il faut donc sortir de la logique de la liste de résultats et ne pas penser l’usage des métadonnées en fonction d’une destination.
Les liens entre les éléments d’information qui composent la fiche de réponse construisent des parcours qui orientent la recherche de l’utilisateur, sans nécessairement aboutir sur un site web. Par exemple, chercher une oeuvre de VanGogh, comme la Nuit étoilée, permet de mesurer la distance et les clics qui nous séparent du site web du Museum of Modern Art.
Ceci accroît la collecte des données d’usage qui permettent d’analyser l’intention, le comportement et la consommation de l’utilisateur. Plus les fonctions et choix offerts sont utiles, plus l’utilisateur demeure dans l’interface du moteur de recherche. Les agrégateurs d’information, qui font face à la désintermédiation de leur services, constateront probablement une diminution progressive du volume de données qui sont collectées sur leurs pages.
L’effet des métadonnées est dans la durée
Les résultats de l’utilisation de métadonnées pour décrire des contenus ne sont pas mesurables, au sens strict.
La qualité de l’encodage des métadonnées peut être validée, mais l’outil de test ne peut juger la logique de la description (interprétation des balises uniquement). Une validation que peu de producteurs de métadonnées semblent se donner la peine de faire. Il est également possible d’attribuer un indice de découvrabilité à une information en fonction de critères spécifiques.
L’effet des métadonnées peut être observé sur un temps long. L’enrichissement progressif de la fiche de réponse illustre le potentiel qu’a une offre d’être liée par le moteur de recherche à d’autres informations. Il n’est pas possible de fournir des résulats immédiats et quantifiables, de façon similaire aux stratégies de référencement organique et payant de pages web.
Schema.org n’est pas le moteur de recherche
Schema est un vocabulaire commun de métadonnées qui a été développé pour les moteurs de recherche. Google recommande l’intégration des métadonnées sous forme de balises dans le code HTML d’une page afin de décrire l’offre qui y est présente. Cependant, les règles de l’algorithme évoluent au fil des expérimentations du moteur de recherche. Les métadonnées Schema qui étaient recommandées pour décrire des offres de type Movie, TVSeries et Music existent toujours. Cependant, Google n’en recommande plus l’usage et invite les entreprises concernées à faire une demande pour devenir des partenaires médias. Jusqu’où, alors, faut-il investir pour indexer une offre si le fonctionnement de l’algorithme et l’évolution du moteur de recherche nous sont inconnus ?
Une réflexion stratégique est nécessaire pour répondre à cette question. Deux avenues s’ouvrent:
1. Rendre des offres interprétables pour les moteurs de recherche (indexation) et appuyer la stratégie de référencement du site
- Fournir uniquement les métadonnées Schema qui sont obligatoirement requises par le moteur de recherche. Ceci fait partie des bonnes pratiques du développement de sites web.
- Tout comme pour le référencement, il est important d’assurer une veille sur l’évolution des fonctions analytiques et techniques des moteurs de recherche.
2. Valoriser les éléments d’un catalogue ou d’une collection en produisant un graphe de données liées
- Fournir des métadonnées très riches selon le vocabulaire Schema.
- Prévoir un important travail de modélisation (de préférence, par une personne compétente) afin de mettre en valeur des attributs et des liens, en travaillant sur les propriétés et les niveaux hiérarchiques.
Enjeux d’importance pour une stratégie numérique:
- Aucun résultat garanti sur le traitement des métadonnées par le moteur de recherche. Ceci ne doit donc pas être l’unique objectif d’un tel projet.
- Vocabulaire et modèle de représentation uniques: uniformisation de la représentation répondant aux objectifs d’affaires des moteurs de recherche.
Précision 2019-05-25: ce billet concerne uniquement le langage de balisage pour moteurs de recherche (métadonnées Schema) et non la représentation des connaissances avec les standards du web sémantique.
Pas de solution, mais quelques questions
L’uniformisation des modèles descriptifs est-elle un risque pour la diversité culturelle ?
La problématique de la «consommation culturelle» ne devrait-elle pas être abordée dans les deux sens ? En orientant nos projets sur la promotion, nous oublions la relation au public et l’analyse de ce qui rend une oeuvre de création attractive. Ce rapport sur les pratiques culturelles numériques et plateformes participatives, piloté par la chercheuse Nathalie Casemajor, contient des pistes de réflexion à ne pas négliger, dont cellec-ci:
Les efforts de découvrabilité ne suffisent pas à eux seuls à créer l’appétence culturelle, et l’analyse des données consommatoires et comportementales n’est pas la panacée pour agir sur le développement des goûts et des dispositions culturelles en amont.
Nous devrions nous donner des moyens pour définir les modalités et conditions de la découvrabilité que nous souhaitons. Celles-ce se trouvent quelque part, entre le monde vu par une entreprise et celui que nous voyons au travers du prisme de nos cultures et sensibilités, d’une part, et, d’autre part, entre lier des données pour un objectif de marketing et faire du lien social autour d’objectifs communs.
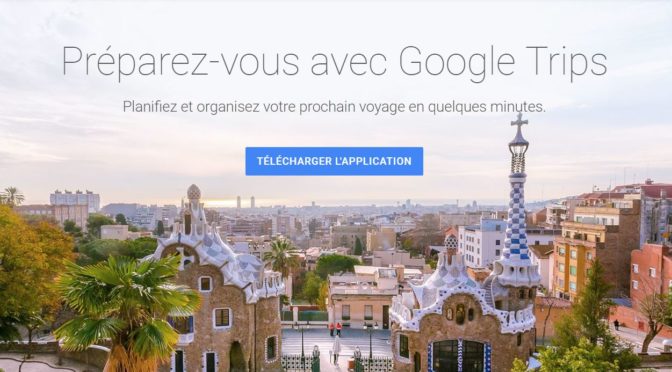
Moteur de recherche et désintermédiation
Il est possible de passer quelques heures, sur le web, à écouter de la musique et à croiser des artistes, connus et inconnus, en suivant des liens tissés par un algorithme. Et cela, sans quitter l’interface du moteur de recherche.
Désintermédiation des services d’information
Le moteur de rechercher devient une interface qui impose aux utilisateurs sa vision du monde, son algorithme, son modèle de classification et son régime de vérité: la popularité. Une uniformisation de la structure de l’information et des fonctions proposées qui efface la diversité des modèles et des expressions.
Avec l’intégration de Google Voyages, grâce aux données collectées auprès des utilisateurs, il connaîtra les intérêts et comportements des voyageurs beaucoup mieux que les organisations touristiques locales et deviendra un partenaire priviliégé des entreprises touristiques. Celles-ci fournissent déjà, par le biais de Google Mon entreprise, les métadonnées qui permettent de lier et classifier les données, en mode hyperlocal. Face à une très probable désintermédiation, les associations touristiques devront mettre l’accent sur une organisation de l’information et des expériences que le moteur ne propose pas.
Nul doute que cette nouveauté accroîtra l’intérêt pour les technologies de liage de données, tel que cette conférence sur les graphes de données, dans le domaine du tourisme.

Projets de données: quel impact sur la transition numérique en culture ?

Dans la foulée des programmes de financement en culture, rares sont les propositions qui ne s’appuient pas sur la production ou l’exploitation de données. Nous devrions nous réjouir de la multiplication de telles initiatives car elles témoignent de la transformation progressive des modèles de pensée et des usages.
Cependant, deux constats témoignent d’une méconnaissance des conditions techniques et méthodologiques de cette transformation : de nouveaux concepts ne sont pas maîtrisés et la persistance de vieux modèles de gestion bloque la transformation des organisations.
Voici des types de propositions, autour des données qui, sous certaines conditions, sont les plus susceptibles de favoriser la transition numérique des acteurs et des organismes culturels.
Schema.org: se représenter sous forme de métadonnées
Voici un exemple d’usage de ce que Google appelle « données structurées« . Il s’agit, en fait, des métadonnées utilisées pour décrire des offres afin qu’elles soient interprétées par des systèmes automatisés. Le site de Patrick Watson, musicien montréalais, contient les métadonnées décrivant les lieux , dates et salles où il se produit en concert. Google proposera ses représentations lors de recherches sur l’artiste ou d’une simple question posée au moteur de recherche. Cette semaine, les utilisateurs géolocalisés près de certaines villes européennes se feront proposer des spectacles de M. Watson. Les offres apparaîtront en décembre pour les utilisateurs du Québec et de l’Ontario.
Cette technique qui vise à améliorer la découvrabilité des offres est, à présent, incontournable. Rater le test des données structurées , pour un événement ou un produit culturel, c’est dépendre uniquement d’activités de promotion pour être proposé à un public. Et c’est également ne pas rentabiliser un investissement dans un site Internet. Cependant, si celui-ci n’est plus une destination principale pour les internautes, il est un point de référence essentiel pour la validation de l’identité numérique.
Impact: culture de la donnée et identité numérique
Apprendre à indexer une offre (la représenter à l’aide de métadonnées) permet à chacun de développer sa littératie numérique ainsi qu’une culture de la donnée. Une bonne initiative viserait à former et à équiper les acteurs culturels afin qu’ils définissent eux-mêmes les données qui les concernent et qu’ils intègrent cette pratique à leurs processus et stratégies. Confier à d’autres le soin de décider de la façon de se représenter n’est ni formateur et ni stratégique.
Une description d’offres personnalisée et éloquente requiert cependant une bonne connaissance des principes d’indexation et de la structure logique du modèle Schema.org. Ce sont des compétences que des bibliothécaires et spécialistes de la documentation pourraient aider à développer auprès des acteurs du milieu culturel et artistique et des agences web.
Données ouvertes: développer une vision sur les données et leurs usages
Les données ouvertes ne constituent pas une technologie mais un moyen de mise à disposition de données selon des licences d’utilisation spécifiques. Libérer des données est, en soi, un projet auquel on doit accorder les ressources et le temps nécessaires pour produire un jeu de données répondant à des besoins. Les fichiers de données ouvertes peuvent être décrits à l’aide de métadonnées Schema. Ceci ne rend cependant pas les données qui y sont contenues, accessibles et interprétables par des moteurs de recherche.
Impact: interdisciplinarité et orientation utilisateurs
La libération de données facilite la réutilisation des données de collections, catalogues ou fonds documentaires dans le cadre de la stratégie de visibilité et diffusion d’un organisme culturel. C’est un projet qui peut transformer des pratiques et des processus de façon durable, à la condition d’adopter une nouvelle méthode de travail collaboratif et de gouvernance de données. NordOuvert, un organisme a conçu une trousse d’outils maison pour données ouvertes pour le gouvernement canadien.
Données ouvertes et liées : capitaliser sur des actifs numériques
Un musée pourrait décrire ses événements pour des moteurs de recherche, avec des métadonnées Schema.org. Mais serait-il pertinent de documenter ainsi tous les éléments d’une collection ? Cette question peut faire débat pour diverses raisons. Le modèle descriptif des moteurs de recherche répond à leurs propres objectifs stratégiques. Le risque encouru est l’effacement de la diversité des perspectives au profit d’un modèle uniforme et d’une certaine vision du monde. Il est également souhaitable, pour un état, de minimiser sa dépendance à l’un des plus puissants acteurs du numérique pour l’organisation des données de la culture et du patrimoine. C’est pour ces raisons que plusieurs initiatives de données ouvertes et liées ont émergé depuis plusieurs années, à travers le monde.
Le terme « données ouvertes et liées » désigne des données qui sont ouvertes et qui peuvent être interprétées et liées entre elles par des humains et des machines si elles sont exprimées et publiées selon les standards du web. Faire un projet de données liées est très exigeant, en ressources, en expertises et, surtout, en temps. Ce sont des activités qui peuvent se dérouler sur plusieurs années afin de s’assurer de la cohérence des modèles de données et des liens.
Impact: responsabilisation et pouvoir d’agir sur les données
Malgré sa complexité, une véritable initiative de données ouvertes et liées peut amener une organisation à passer d’une gestion de projet centralisée à une véritable démarche collaborative, à l’interne et avec des partenaires. La transition numérique repose sur une profonde transformation des modes de gestion de l’information. Une solution issue d’un travail collaboratif a plus de chances de produire des résultats satisfaisants et durables pour tous qu’un projet classique. La production de données devient alors une responsabilité distribuée au sein d’une organisation et, par extension, au sein de son écosystème.
On ne saurait parler de production de données sans mentionner le nombre croissant d’initiatives s’appuyant sur l’infrastructure de Wikidata pour exposer des données ouvertes et liées. Art Institute of Chicago est une des institutions ayant récemment ajouté les données de ses collections et plus de 52 000 images d’oeuvres en licence Creative Commons 0 (domaine public). Cette institution, comme tant d’autres, sort du périmètre habituel de sa stratégie de développement de publics pour expérimenter d’autres formes de circulation de l’information.
Transition: de projets à initiatives
Une initiative de données structurées, ouvertes ou liées constitue une opportunité pour une véritable transition numérique. Comme l’affirme un chercheur du MIT Media Lab dans un billet sur la nécessité de développer une littératie de la donnée: «You don’t need a data scientist, you need a data culture » :
- Leadership: priorise et investit dans la collecte, la gestion et l’analyse de données / la production de connaissances.
- Leadership: priorise une littératie de la donnée créative pour l’ensemble de l’entreprise, et pas seulement pour les technologies de l’information et la statistique.
- Membres du personnel: encouragés et aidés à accéder aux données de l’organisation, à les combiner et à en tirer des conclusions.
- Membres du personnel: savent reconnaître les données. Ils proposent des façons créatives pour utiliser les données de l’organisation afin de résoudre des problèmes, prendre des décisions et élaborer des narratifs. (traduction libre)
Ce ne sont donc ni une mise à niveau technologique, ni l’acquisition de nouveaux usages qui opéreront cette transformation. C’est plutôt l’adoption de nouveaux modes de gestion de l’information: la décentralisation des prises de décision, l’abolition des silos organisationnels et la mise en commun de données. Pour demeurer pertinents dans un contexte numérique, nous ne pouvons faire autrement que d’expérimenter des méthodes collaboratives. Nous pouvons réussir à plusieurs ce qu’il est trop périlleux d’entreprendre individuellement. Soutenir des initiatives de données sans s’engager dans cette voie limiterait considérablement l’impact des investissements en culture.
Web sémantique: de choc culturel à transformation numérique
C’est que nous avons pu constater au fil des présentations de la troisième édition du Colloque sur le web sémantique au Québec. Quelle que soit la nature de la problématique, du projet et du secteur d’activité considéré, tous les conférenciers ont fait état de changements nécessaires pour profiter des avantages du web de données.
Ces changements se manifestent à plusieurs niveaux: technologique, organisationnel, culturel, professionnel et structurel.
De fragmentation à intégration
Changement technologique – Le web sémantique permet de fournir des solutions aux problèmes d’interopérabilité des systèmes en affranchissant les données des environnements matériels et logiciels ne favorisant pas les interconnexions. Il devient donc essentiel, pour les professionnels de l’informatique, de se familiariser avec les graphes de données liées et d’adopter des standards ouverts qui permettent de sortir les données des silos des bases de données classiques. Ces nouvelles connaissances sont nécessaires à l’accompagnement des autres secteurs métiers et à ce que le service informatique contribue à l’élaboration d’une définition partagée des normes, règles et processus pour la qualité des données.
▷ Pour aller plus loin: démonstration très accessible des limites de la base de données classique et des possibilités qu’offre le graphe de données liées pour le traitement des connaissances, par Gautier Poupeau, architecte de données à l’Institut national de l’audiovisuel (INA), France.
De centralisation à distribution
Changement organisationnel – Un projet de données liées (ou ouvertes et liées) est une démarche interdisciplinaire et collaborative. À l’image du Web, qui ne se développe pas de façon centralisée mais distribuée, la qualité des données devrait être une responsabilité partagée par toutes les fonctions d’une organisation.
Pour avoir des données et métadonnées utiles, il faut améliorer les compétences des personnes qui les produisent par l’apprentissage des bonnes pratiques — comme l’usage de référentiels communs pour catégoriser des documents et l’utilisation d’outils qui favorisent l’accessibilité et le partage de données. Ceci implique également, une maîtrise du cycle de vie des données (création/collecte, traitement, analyse, conservation, accès, réutilisation) par tous les services.
Dans cette même perspective, la résilience et les bons résultats d’un projet de données liées se fondent sur de nouvelles méthodes de travail qui visent la décentralisation des décisions relatives à l’identification des problématiques, à la priorisation des projets et à la proposition de solutions. C’est une étape clé vers l’adoption de systèmes distribués et de modes de direction et d’action plus agiles et plus propices à l’innovation que les structures hiérarchiques.
▷ Pour aller plus loin: conférence de Diane Mercier, docteure en sciences de l’information, sur le web sémantique et la maturité informationnelle de l’organisation (2016). Après une véritable transformation numérique, la prise en charge de la qualité des données n’est plus uniquement du ressort de l’informatique, mais de tous les métiers et la gouvernance des données n’est plus fragmentée, mais globale.
D’uniformisation à harmonisation
Changement culturel – Lorsque différents acteurs internes et externes sont appelés à contribuer à la production de données liées, il n’est pas rare d’assister à une confrontation des savoirs, des perspectives et des vocabulaires utilisés. Pourtant, dans un projet de données liées, plusieurs modèles, standards et vocabulaires peuvent cohabiter dans un même système pour autant que ceux-ci soient conformes aux normes techniques du web sémantique. Il ne s’agit pas d’uniformiser les façons de décrire des ressources, mais de normaliser les référentiels pour les rendre interopérables, la diversité des perspectives venant alors enrichir la connaissance que nous avons de ces ressources.
Il est d’autant plus important d’accueillir cette diversité des pratiques descriptives que, dans divers domaines allant de la muséologie aux administrations publiques, nous sommes amenés à prendre conscience des biais culturels véhiculés par les différents modèles de représentation et de classification en usage au sein des organisations.
▷ Pour aller plus loin: exemple d’ONOMA, un projet du Ministère de la Culture et de la Communication (France) visant à lier les différents référentiels qui décrivent des auteurs, créateurs, producteurs et personnalités intervenant dans le cycle de vie d’un bien culturel. Une démarche d’harmonisation similaire peut être mise en œuvre dans bien d’autres domaines.
De technocentrisme à interdisciplinarité
Changement professionnel – Comment des spécialistes des TI et des sciences de la donnée peuvent-ils travailler sur le traitement de la connaissance d’un domaine hors de leur champ de compétences? Un projet web sémantique comporte des défis de nature technique et conceptuelle pour lesquelles il est impératif de rassembler une diversité de perspectives et d’expertises. Notamment, en ce qui a trait à l’organisation et au traitement de l’information, comme l’indexation de documents, la modélisation des connaissances ou la linguistique.
▷ Pour aller plus loin: billet de Fred Cavazza, spécialiste des transformations numériques, sur le rôle central des experts métiers dans des projets de traitement de données, dont des systèmes d’intelligence artificielle.
Du court terme au long terme
Changement structurel – Les programmes qui soutiennent organismes et secteurs d’activité sont généralement orientés vers l’atteinte de résultats à court terme. Or, il ne faut pas attendre de résultats immédiats de projet de données liées. Il y a donc peu d’incitatifs, pour les organisations, à réaliser des projets leur permettant d’entrer dans l’économie de la connaissance. Pour ce faire, il faut adapter les politiques et programmes afin d’encourager les investissements à moyen et long termes. Ceux-ci donneront lieu à des initiatives telles que des preuves de concept ou des prototypes, préalables nécessaires de projets plus ambitieux.
▷ En résumé – Le web sémantique ne constitue pas uniquement une évolution technologique mais avant tout une transformation profonde des modes de gestion de l’information et de gouvernance des données. Il nécessite la mise en place de nouvelles façons de travailler, tant pour la décentralisation des prises de décision que pour l’abolition des silos informationnels et la mise en commun de l’information.
Transformation pour un monde numérique
Le web sémantique nous amène à envisager le numérique comme un écosystème d’acteurs métiers et de moyens technologiques interdépendants. Contrairement aux projets informatiques « traditionnels », il nécessite l’aménagement d’un environnement d’apprentissage collaboratif et de conversations transversales dans l’organisation. Sa finalité est de faire émerger l’intelligence collective permettant de produire de la connaissance et non de développer des systèmes.

Trois enjeux communs pour les métadonnées en culture
Les métadonnées, en culture, servent à décrire des choses pour les rendre repérables et à faire des liens d’association entre des éléments d’information pour générer de nouvelles connaissances. Voici trois enjeux pour la création de métadonnées culturelles qui devraient être abordés de façon prioritaire, au sein des organismes, institutions, entreprises et regroupements associatifs.
1. Mise à niveau de nos systèmes d’information
La problématique des métadonnées en culture origine de la conception des systèmes d’information. La source de la plupart des problème se situe en amont des processus de gestion de l’information, soit lors de la saisie des données dans un un système ou un logiciel qui n’a pas été conçu pour générer des métadonnées interopérables. Il est également plus facile de convaincre des gestionnaires d’investir dans un nouveau site web que dans un modèle de métadonnées normalisées et interopérables pour lequel il est difficile de fixer des indicateurs de rendement.
Qualité des données
Plus de 60% du temps de travail des experts des données est consacré au nettoyage et à l’organisation des données. Il est possible de produire des données qui soient exploitables, plus facilement et à moindre coût, en mettant en application des principes de qualité inspirés, par exemple, de ceux qui guident la production de données ouvertes et liées pour l’Union européenne.
De la base de données au web de données
Au web des documents, s’est ajouté celui des données. Nous nous éveillons lentement à des modes de représentation et d’exploitation de l’information qui ne font plus référence à des pages, mais à des connaissances et à des ressources.
Dans le web, un contenu c’est de la donnée. Si les pages web s’adressant à des humains demeurent toujours utiles, ce sont les données décrivant des ressources (modèle Schema ou triplets du web sémantique) qui permettent à certaines technologies de classer et de relier l’information obtenue afin de nous fournir des réponses et, surtout, des suggestions.
Indexation de contenu et normalisation de données
Bien que des termes comme « métadonnées » et, même « web sémantique », se retrouvent désormais au programme de nombreux événements professionnels, au Québec et au Canada, trop rares sont les initiatives et projets où il est fait appel à des équipes pluridisciplinaires comme cela se fait au sein de gouvernements, d’institutions ou d’initiatives collectives, en Europe et aux États-Unis.
Est-il possible de réaliser des projets d’une complexité et d’une envergure que l’on peine à mesurer en dehors du cadre habituel d’un projet de développement technologique ? On peut en douter. Nous manquons de compétences en ce qui concerne la représentation de l’information sous forme de données liées, ainsi que sur les principes et méthodes de la documentation de ressources. Comment pourrions-nous, alors, atteindre des objectifs qui permettraient de tirer tous les avantages possibles des données qui décrivent nos contenus culturels ?
Plus concrètement, comment pourrions-nous entreprendre les démarches nécessaires à la réalisation d’objectifs similaires à ceux du projet DOREMUS qui réunit Radio France, Philharmonie de Paris et Bibliothèque nationale de France ?
«Permettre aux institutions culturelles, aux éditeurs
et distributeurs, aux communautés de passionnés
de disposer :
- de modèles de connaissance communs (ontologies)
- de référentiels partagés et multilingues
- de méthodes pour publier, partager, connecter, contextualiser, enrichir les catalogues d’œuvres et d’événements musicaux dans le web de données
Construire et valider les outils pédagogiques qui permettront le déploiement des standards, référentiels et technologies dans les institutions culturelles
Construire un outil d’assistance à la sélection d’œuvres
musicales.»
Il serait temps de moderniser les programmes de formation universitaire en bibliothéconomie et sciences de l’information et en technologies de l’information et d’encourager des intersections. Sans quoi, nous ne disposerons pas suffisamment de ressources compétentes pour passer du web des documents au web des données.
2. Décentralisation de la production de métadonnées
La centralisation de la production de métadonnées est contraire à la culture numérique car elle favorise généralement les perspectives et besoins d’une entité ou d’acteurs majoritaires. Les initiatives qui présentent le plus grand potentiel pour le développement de compétences en matière de production et réutilisation de données sont celles où les organismes sont appelés à participer activement à l’élaboration de leurs modèles de données, aux décisions en ce qui a trait à l’utilisation des données et à la conception de produits ou services. C’est par la pratique que les gestionnaires et entrepreneurs sont sensibilisés à l’utilité et à la valeur des données qu’ils produisent et qu’ils collectent.
Comme le signale Fred Cavazza, dans un récent billet, il nous faut réduire la dette numérique avant d’entreprendre une véritable transformation:
«Nommer un CDO, créer un incubateur, organiser un hackathon ou nouer un partenariat avec Google ou IBM ne vous aidera pas à vous transformer, au contraire, cela ne fera que reporter l’échéance. Il est donc essentiel de réduire la distance au numérique pour chaque collaborateur, et pas seulement les plus jeunes ou ceux qui sont directement impliqués dans un projet.»
À ce titre, externaliser l’indexation des ressources culturelles (production de métadonnées) ne saurait être considéré comme un choix stratégique dans une économie numérique puisqu’il éloigne les acteurs du traitement des données et les confine à des rôles de clients ou d’utilisateurs, sans opportunités d’apprentissage pratique. En effet, se pencher sur l’amélioration et la valorisation de données descriptives et de données d’usage est le meilleur moyen de développer une culture de la donnée et d’acquérir les connaissances qui permettent de transformer des pratiques et de se réinventer. En plus de responsabiliser les organismes et entreprises et d’assurer la découvrabilité numérique de leurs ressources, la décentralisation de la production de métadonnées renforce la résilience de l’écosystème; chacun des acteurs devenant un foyer potentiel de partage de connaissances et d’expérience.
3. Reconnaissance de la diversité des modèles de représentation
La centralisation de la production de métadonnées ne favorise pas la diversité des modèles de représentation et, plus spécifiquement, une réflexion post-colonialiste sur la description de productions culturelles et œuvres d’art, comme le lieu de fabrication ou la nationalité ou l’ethnie. Une démarche centralisée conduit à adopter un seul modèle de représentation des ressources, au détriment de la diversité des missions, des cultures, et des pratiques. Dans le domaine du patrimoine culturel, par exemple, il existe près d’une centaine de modèles de description différents. Tous ne conviennent pas à la production de données ouvertes et liées, mais il demeure que cette diversité des modèles est essentielle car elle répond à des besoins et contextes d’utilisation spécifiques.
C’est dans le même esprit, qui a permis au web de devenir ce qu’il est (voir « small pieces loosely joined » de David Weinberger, un des penseurs du web), qu’il faut s’entendre sur des principes et des éléments permettant de faire des relations entre différents modèles de métadonnées. Cette démarche comporte des enjeux de nature conceptuelle, technologique, voire même économiques et de politiques publiques. Face à un tel niveau de complexité, nous ne devrions pas tarder à rassembler, autour de ces enjeux, des spécialistes du développement d’ontologies et des questions d’interopérabilité des métadonnées.
*
Ce ne sont pas de nouveaux portails, plateformes et applications qui nous permettront de ne pas dépendre totalement d’entreprises se plaçant au-dessus des états eux-mêmes. Une « solution technologique » aussi extraordinaire soit-t-elle, ne remplace pas une vision et des stratégies. Surtout lorsque les modèles économiques, dont nous tentons d’imiter les interfaces sans en maîtriser le fonctionnement, reposent sur l’exploitation de données par des algorithmes et des technologies d’intelligence artificielle.
Que faire pour multiplier l’impact des initiatives numériques ?
Comment multiplier la portée des programmes de soutien à la transformation des organisations dans un contexte numérique ? En favorisant des initiatives qui ont pour objectifs des résultats durables et transmissibles à d’autres individus, organismes ou secteurs d’activités.
Ceux qui tirent la plus grande partie des bénéfices d’une économie numérique sont ceux qui en maîtrisent les concepts clés (collecte de données, organisation et classification de l’information, traitement algorithmique) et qui prennent les moyens pour profiter du réseau (contenu généré par les utilisateurs, mobilisation de capital intellectuel). Nous ne pouvons cependant pas tenter d’imiter des modèles qui ont nécessité des investissements colossaux et qui, après des années d’expérimentation, constituent des entités aussi riches et puissantes que des états. Mais nous ne devons pas non plus demeurer des fournisseurs de données et de contenus.
C’est pourquoi des programmes d’aide à la transformation numérique et à l’innovation, quel que soit le secteur d’activité, devraient permettre d’accroître de manière plus efficace nos connaissances en matière d’information numérisée , et de favoriser la collaboration entre organismes pour concevoir et expérimenter d’autres modèles de création de valeur.
Voici 3 notions qui sont essentielles pour sortir des vieux modèles :
1 – L’information avant les moyens technologiques
Découvrabilité, métadonnées, mise en commun de données, diffusion de contenu: bien avant d’être du développement logiciel ou la mise en place d’infrastructures, c’est un travail sur la définition et l’application de principes de traitement et d’organisation de l’information.
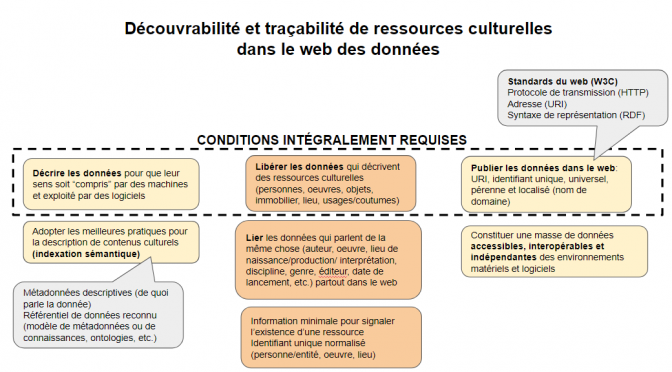
La mise en nombres binaires de l’information (soit des suites de 1 et de 0 qui représentent des caractères, puis des mots) est ce qui rend son traitement et sa transmission possibles par des machines. Par contre, pour que cette information numérisée puisse être repérable, « comprise » et exploitable par des machines qui sont, à présent, en quête de sens, il faut :
- Décrire les données pour qu’elles soient lisibles et utilisables pour des machines.
- Publier les données dans le web selon les standards du W3C pour les données ouvertes et liées (Linked Open Data).
De plus, pour rendre cette information découvrable dans le web, il faut préalablement réaliser une étape essentielle:
- Libérer les données qui décrivent des ressources (contenus culturels, patrimoine vivant et immatériel, produits, services, etc.).
2 – Les données comme actif plutôt que matière première
Nous souhaitons que les moteurs de recherche et autres types de technologie utilisés pour ratisser le web repèrent les données qui décrivent nos contenus, produits et services. Or, nous persistons à considérer la donnée comme une ressource alors que dans une économie numérique, il s’agit d’un actif. Cette nuance est extrêmement importante puisque cette ressource n’a de valeur que si elle est rare. Nous pourrions, par exemple, avoir à payer pour obtenir les données qui décrivent les titres d’un répertoire musical. Cependant, les données ne seraient donc pas repérables et accessibles pour les humains et les machines.
Considérer les données comme un actif permet de capitaliser sur la valeur de l’information qu’elles permettent de générer et sur le potentiel de découvrabilité qu’elles accordent aux contenus qu’elles décrivent.
3 – Travailler ensemble autour des données
Collaborer au sein d’une même organisation, à travers les disciplines ou entre organismes favorise l’émergence d’idées novatrices et permet de surmonter des problématiques complexes. Travailler sur des données en diversifiant les perspectives permet de générer de l’information utile pour divers objectifs, domaines d’activité et types d’utilisateurs. C’est pourquoi des initiatives qui sont mises en oeuvre par des équipes pluridisciplinaires ont de meilleures chances de succès.
Travailler ensemble sur la valorisation ou la mise en commun de données, que ce soit au sein d’un même organisme ou en partenariat avec d’autres organisations, requiert l’adoption de véritables méthodes collaboratives, notamment, pour que des enjeux relatifs à la gestion des données et au processus décisionnel ne viennent faire obstacle à l’atteinte des objectifs. En s’éloignant des dynamiques de contrôle et de subordination habituelles, il est possible d’instaurer un climat de confiance et la cohésion nécessaires à un travail collaboratif.
Un vrai modèle collaboratif n’est pas centralisateur: chacun des contributeurs d’un système de traitement ou de mutualisation de données est responsable de leur production et de leur qualité.. Ceci a pour effet d’assurer une gouvernance équilibrée du système et le transfert et développement de compétences au sein de chacune des organisations.
Pour cela, il faut apprendre à élaborer des démarches de projets qui fédèrent les participants autour d’un objectif commun tout en reconnaissant les bénéfices individuels et les limites de chacun. Ainsi, les initiatives et projets peuvent profiter du partage de connaissances au sein de réseaux internes et externes.
Pas d’évolution numérique sans maturité informationnelle
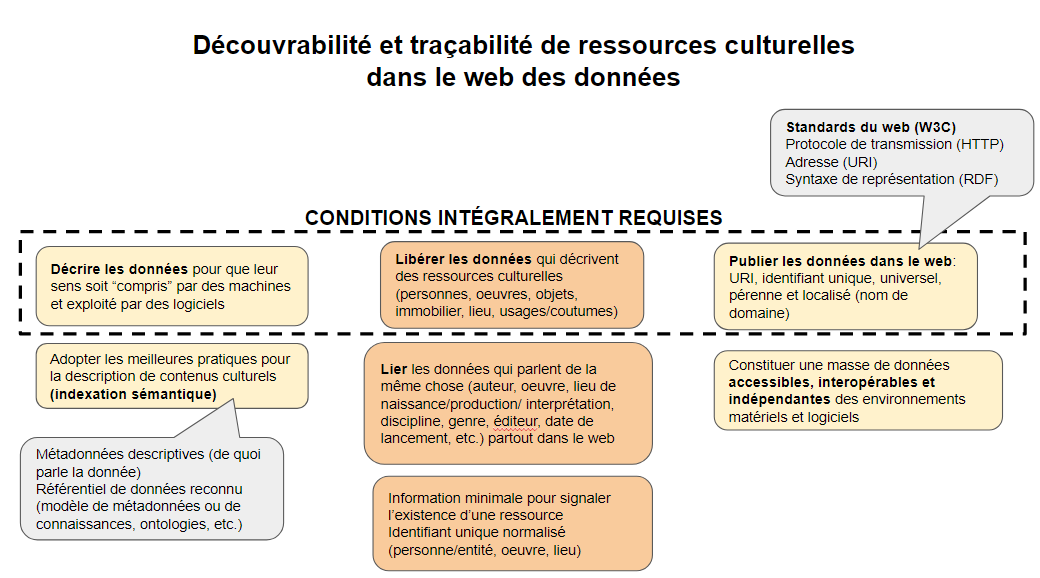
Voici la démarche des 5 étoiles du web des données, tel que conçue par Tim Berners-Lee et soutenu par les recommandations du W3C.
∗ Rendez vos données disponibles sur le Web (quel que soit leur format) en utilisant une licence ouverte.
** Rendez-les disponibles sous forme de données structurées (p. ex., en format Excel plutôt que sous forme d’image numérisée d’un tableau).
*** Utilisez des formats non exclusifs (p. ex., CSV plutôt que Excel).
**** Utilisez des URI pour identifier vos données afin que les autres utilisateurs puissent pointer vers elles.
***** Reliez vos données à d’autres données pour fournir un contexte. (Cote de degré d’ouverture des données, Gouvernement ouvert, Canada).
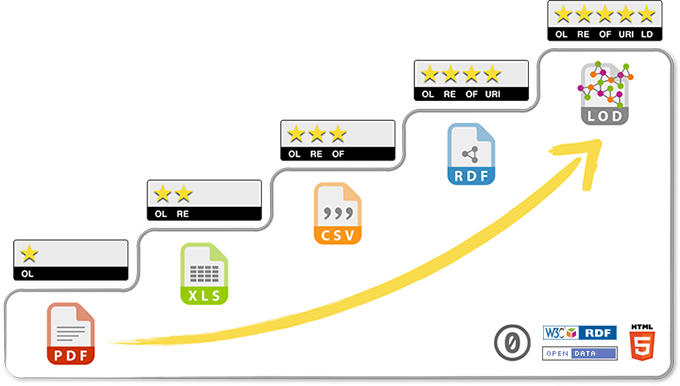
Voici l’échelle de la maturité informationnelle des organisations, telle qu’illustrée par Diane Mercier dans le cadre de sa thèse doctorale sur le web sémantique et la maturité informationnelle des organisations.
Thèse doctorale et références : Web sémantique et maturité organisationnelle sur Zotero.

Ces deux modèles participent de la même démarche graduelle et progressive vers l’ouverture et la participation, grâce à l’adoption de principes communs. C’est cette transformation que des initiatives numériques devraient permettre d’amorcer pour le bénéfice d’organismes et entreprises et, plus largement, pour la résilience d’un secteur d’activité ou d’un écosystème.
La culture à l’ère numérique: dans le web des données plutôt que sur une plateforme
Tenter de concurrencer les géants des contenus numériques en proposant nos propres plateformes, comme le proposait Alexandre Taillefer, est une mauvaise bonne idée; surtout dans le domaine culturel. Voici pourquoi:
NON: centraliser l’information dans une base de données
C’est une mauvaise idée, parce qu’il s’agit d’un concept qui va à contre-courant de l’Internet de Tim Berners-Lee: connaissances partagées, production de contenus décentralisée, modèles distributif et collaboratif, données ouvertes et liées, perspectives à la fois locale et globale. Développer une plateforme afin de centraliser dans une base de données l’information concernant des contenus culturels c’est soustraire ces derniers aux connexions potentielles avec d’autres données à travers le monde.
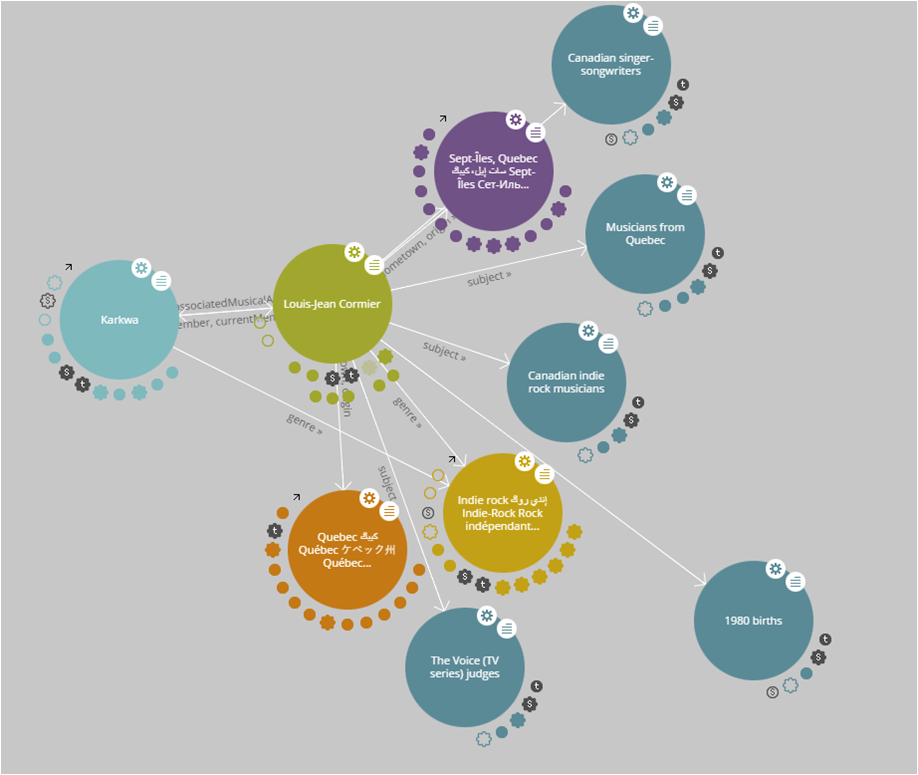
Le contenu des bases de données est « sous le web« , c’est à dire inaccessible et incompréhensible pour les moteurs de recherche et applications qui ratissent le web en quête de données qui font du sens. La transition d’un web des documents vers le web des données, et, par conséquent, de la préférence visible des moteurs de recherche pour le sémantique (Google et les données structurées), ne font plus de doute. S’exposer dans le web des données ouvertes et liées constitue une bien meilleure stratégie, pour la valorisation des contenus, le développement de modèles économiques et l’acquisition d’une culture de la donnée, que la reprise d’un concept datant du premier âge du web.
Alors, pourquoi continuer à financer des silos d’information qui interdisent toute possibilité de liens entre nos contenus et l’intention ou le parcours de consommateurs , où qu’ils se trouvent ?
OUI: mutualiser les ressources pour publier et agréger des données
La bonne idée est celle de la mutualisation d’équipement et de ressources pour réaliser un projet collectif. Là se trouve le véritable défi de la « révolution numérique »: apprendre à se faire confiance et à collaborer pour développer une valeur collective. Apprentissage d’autant plus difficile que l’offre culturelle est abondante et que notre attention, elle, est limitée.
Publier des données dans le web, comme on le fait pour des pages de sites internet, permet d’éviter les problèmes d’interopérabilité des bases de données tout en préservant l’autonomie des producteurs de données. Il devient, par la suite, possible de collecter et d’agréger ces données afin de les exploiter pour les rendre réutilisables pour des organismes touristiques, pour créer des interfaces d’exploration et, même, pour concevoir des agents intelligents qui feront des suggestions de contenus personnalisées. Mieux que tout autre documentation, cette vidéo produite par la Fondation europeana, explique en 3 minutes ce qu’est le web des données ouvertes et liées et pourquoi il est devenu si important pour la diffusion de la culture.
Le développement de cette infrastructure commune peut être pris en charge par l’État, comme c’est le cas pour Europeana, où l’Union européenne et chacun des états contributeurs, soutiennent les infrastructures et ressources qui permettent aux institutions culturelles de publier leurs données collectivement. L’État peut également faire appel au milieu académique et au secteur de la recherche, à l’image de l’entente récemment conclue, en France, entre le Ministère de la Culture et de la Communication et l’Inria, afin de soutenir le projet SemanticPedia.
Bien que le web sémantique soit utilisé dans des domaines aussi divers que les services hydroélectriques (Hydro-Québec) et la radiodiffusion (BBCMusic), nous persistons à nous tourner vers des technologies conventionnelles pour diffuser nos contenus culturels. Passer de l’informatique au numérique est clairement un changement difficile à opérer, même dans une industrie de pointe.
Pour aller plus loin
Pour les technophiles: Le web sémantique en 10 minutes, vidéo produite lors de l’édition 2016 du colloque sur le web sémantique au Québec, dans le cadre du 84e congrès de l’ACFAS.