Quelle est la probabilité que des données ouvertes et liées fassent découvrir une chose qu’on ne connaît ou ne cherche pas? Le potentiel de découvrabilité d’une offre culturelle sous forme de données avec les technologies du Web sémantique est très faible. Pourtant, l’Appel de projets pour le développement culturel numérique dans la francophonie canadienne privilégie la « production et la diffusion la plus large possible de métadonnées (idéalement sous forme de données ouvertes et liées) ». Les arguments qui soutiennent cette orientation gagneraient à être partagés et discutés au sein de comités scientifiques et techniques.
Continuer la lecture de Quel est le potentiel de découvrabilité des données ouvertes et liées?Archives par mot-clé : métadonnée
Comment améliorer la découvrabilité sur Google?
Pour améliorer la découvrabilité sur Google, mieux vaut utiliser les données là où elles sont vraiment utiles et comprendre les différents types de résultats présentés par le moteur de recherche. En effet, de nouvelles fonctionnalités transforment peu à peu la liste de liens classiques en une interface qui fournit des réponses et des suggestions pour amener les internautes à préciser leurs intentions.
Continuer la lecture de Comment améliorer la découvrabilité sur Google?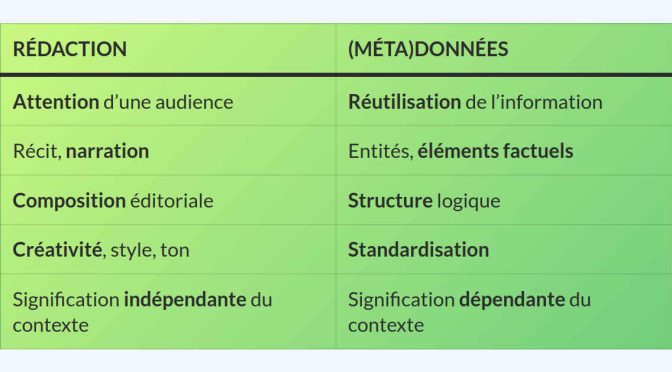
Découvrabilité: les données et métadonnées sont-elles toujours utiles?
De façon générale, les initiatives visant à promouvoir une offre culturelle afin de favoriser sa « découvrabilité » concernent les moteurs de recherche comme Google ou des plateformes en ligne, existantes ou à concevoir. Ce sont cependant deux types de projets différents pour lesquels le type d’information à produire détermine des activités, compétences et ressources nécessaires différentes.
Continuer la lecture de Découvrabilité: les données et métadonnées sont-elles toujours utiles?
Les données ne sont pas la panacée de la découvrabilité

Orienter toute initiative de découvrabilité vers la production de données relève de la pensée magique selon laquelle la technologie est la solution à toute problématique, aussi systémique et complexe soit-elle.
Continuer la lecture de Les données ne sont pas la panacée de la découvrabilité
Découvrabilité: sens commun et connaissances partagées
Les formations, référentiels, trousses à outils, programmes de financement et experts en découvrabilité abondent. Tous peuvent se saisir des termes et notions qui circulent sans avoir une compréhension approfondie du Web. C’est, à mon avis, préoccupant car il n’existe pas de traité sur ce qu’il faut faire, dans le numérique, pour qu’une information soit vue. À la différence du génie ou de la médecine, par exemple, il n’y a pas de socle commun de connaissances pour les divers métiers du Web. Un projet numérique est souvent une tour de Babel de concepts. Que des non-spécialistes du numérique, comme des directions d’entreprises, soit dépassés n’est pas étonnant.
Continuer la lecture de Découvrabilité: sens commun et connaissances partagées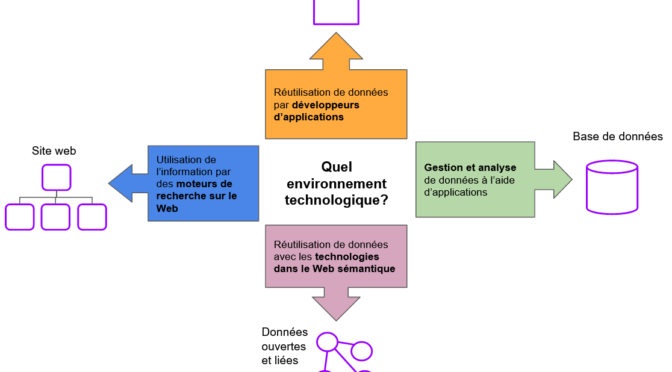
Découvrabilité: oui, mais dans quel environnement technologique?
Favoriser la découverte d’une offre pour atteindre un objectif c’est bien, mais dans quel environnement technologique? La réponse à cette question, rarement abordée, pourrait pourtant aiguiller certains projets ciblant les moteurs de recherche vers de meilleures pratiques de conception et de rédaction pour le Web plutôt que vers la création de métadonnées.
Continuer la lecture de Découvrabilité: oui, mais dans quel environnement technologique?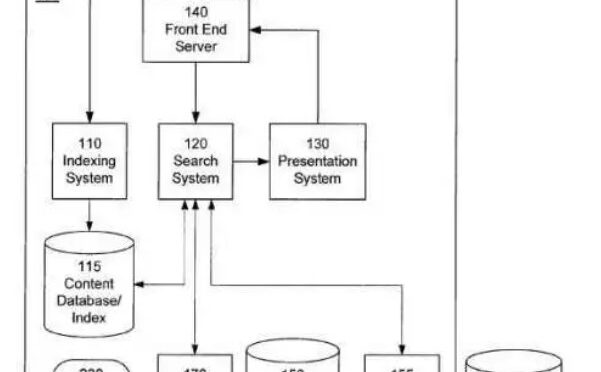
Wikipédia, Wikidata, Google et la découvrabilité: gare au solutionnisme
Le Guide des bonnes pratiques: découvrabilité et données en culture, récemment publié par le Ministère de la Culture et des Communications du Québec, est un bel effort de synthèse. Il faut cependant plus qu’un exercice de rédaction pour transmettre à des non-initiés des connaissances sur des systèmes dont le fonctionnement et les interdépendances sont complexes, changeants et trop souvent, incompris.
Continuer la lecture de Wikipédia, Wikidata, Google et la découvrabilité: gare au solutionnisme
Découvrabilité: comment aiguiller des initiatives numériques vers la bonne voie

Il est temps d’apporter un peu de clarté dans le méli-mélo de concepts qui ne sont pas très bien maîtrisés. Voici une petite mise au point qui pourrait être bénéfique pour les promoteurs d’initiatives numériques, ainsi que les organisations qui les financent.
Continuer la lecture de Découvrabilité: comment aiguiller des initiatives numériques vers la bonne voie
Comment faire un plan de « découvrabilité » pour des résultats mesurables

Depuis peu, en culture, on retrouve un volet « découvrabilité » dans la plupart des appels à projets. S’agit-il d’une application technologique, de techniques de référencement ou d’une campagne de promotion numérique? L’absence d’explications concrètes et de description des compétences requises met les demandeurs (ainsi que les bailleurs de fonds!) dans une situation où ils ne disposent pas des guides nécessaires pour savoir ce qu’il faut faire, ni quels résultats escompter.
Un projet dans un projet
Assurer la repérabilité d’une nouvelle création ou d’une nouvelle offre est un projet à part entière, avec ses ressources, ses objectifs et ses réalisations. Il ne s’agit pas de mettre en commun ce que chacun aura produit de son côté, mais de produire des contributions s’alimentant les unes des autres. C’est pourquoi, dans nos velléités de transformation numérique, le travail en silo est un frein à la réussite de nos projets.
Les mots qui font des connexions
C’est l’information fournie à propos des choses qui est repérable — pas les choses en elles-mêmes. Cette distinction est extrêmement importante puisque c’est le choix des éléments descriptifs qui retient l’attention d’audiences cibles et qui permet aux moteurs de recherche de connecter des offres à des intentions et des profils d’utilisateurs.
Sous le couvert nébuleux de la découvrabilité, il existe en réalité des pratiques et des standards permettant de structurer l’information pour le Web afin d’en assurer la repérabilité, l’accessibilité et l’interopérabilité.
Google ne parle pas web sémantique
Représenter des connaissances avec les technologies du web sémantique (URI, RDF…) et structurer de l’information pour des moteurs de recherche sont des projets différents qui n’ont pas les mêmes finalités.
Si votre objectif est de faire découvrir votre offre culturelle en vous servant, entre autres, des moteurs de recherche pour générer des visites, des visionnements ou des achats, le web sémantique ne vous sera d’aucune utilité!
Google n’exploite que le langage de balisage Schema.org…
Pour un plan de découvrabilité plus efficace
Voici les éléments de réflexion qui apporteront plus d’efficacité à votre plan de découvrabilité. La grande lacune de la plupart des plans de découvrabilité est l’absence ou la faiblesse de la stratégie — comment pousser les bons contenus aux bons publics, sur les bons canaux, pour atteindre des objectifs mesurables. Or, ce travail est essentiel à plusieurs titres:
1 – Connaître les publics et fixer des objectifs
À quels besoins et à quels publics votre offre est-elle susceptible de répondre? Les objectifs à atteindre doivent être déterminés en fonction des intérêts et comportements de ces publics cibles ainsi que de leurs possibles relations à l’offre.
2 – Différencier votre offre
Le vocabulaire Schema.org permet de fournir une description détaillée d’une offre culturelle. Google n’en utilise cependant que certains éléments. Baliser une offre de spectacle n’est pas suffisant pour permettre à celle-ci de se différencier de milliers d’autres offres. La connaissance des publics fournit les éléments d’information et le vocabulaire pouvant aider les moteurs de recherche à faire des connexions entre les intentions et profils des utilisateurs et les offres disponibles.
3 – Faire travailler des spécialistes ensemble
Les balises et le référencement par mots clés sont des outils complémentaires s’appuyant sur la stratégie de promotion. Accroître la découverte commence par la présentation de l’offre sur le site web . Ceci a pour but de faciliter le travail des moteurs de recherche et d’améliorer l’expérience de l’utilisateur avec leur interfaces.
4 – Relier les acteurs de l’écosystème
Si un site web est absolument essentiel et stratégique, d’autres présences numériques contribuent au rayonnement d’une offre. Une bonne stratégie met donc à contribution les acteurs de l’écosystème en identifiant des points d’entrée (réseau social, vidéo, site partenaire, etc.) et en multipliant ainsi les parcours de découverte.
5 – Ne pas compter uniquement sur Google
En se contentant de produire des métadonnées sous forme de balises Schema.org, on se conforme aux modèles et directives qui répondent avant tout aux objectifs d’affaires d’un géant du numérique. Bien que le balisage d’offres pour les moteurs de recherche fasse partie des bonnes pratiques web, Google ne garantit aucun résultat (longue lecture, mais excellent billet).
Attention: les métadonnées ne sont pas toujours utiles. Si vous souhaitez améliorer la valeur de votre site pour Google, corrigez les lacunes de conception et améliorez la valeur du contenu rédactionnel.
6 – Mesurer l’atteinte des objectifs
Finalement, la découverte d’offres culturelles sur un moteur de recherche est difficilement mesurable. Elle dépend de plusieurs facteurs extrêmement variables, comme le profil, l’intention présumée par l’algorithme et les usages antérieurs de chaque utilisateur. Ce sont donc les objectifs et indicateurs de mesure ayant été déterminés dans le plan stratégique qui permettront d’évaluer la réussite de celui-ci.
Utiliser des métadonnées sans tomber dans le solutionnisme
Ce ne sont pas les métadonnées qui produisent des résultats, mais les moyens déterminés par la stratégie. Il faut donc proposer des initiatives plus marquantes pour la diffusion et l’appréciation de nos offres culturelles. Par exemple, renouveler l’expérience de recherche sur un site en présentant l’information sous forme de fiches, de façon similaire à Google, mais selon d’autres règles que la popularité et la similarité.
Il n’existe pas de recette. Chaque projet étant unique, il doit se différencier pour se démarquer, et ce grâce au choix des canaux, plateformes, mots, images et liens adressés aux bons publics.
Surtout, il ne faut pas se contenter d’appliquer les consignes de Google. On doit également chercher à comprendre l’interaction complexe des systèmes et identifier les éléments stratégiques que nous pouvons contrôler.
Enfin, nous ne pouvons pas encourager le milieu culturel à se conformer à un système dont nous ne comprenons pas le fonctionnement et dénoncer, dans le même temps, la domination et l’opacité des GAFAM. Cette contradiction en dit long sur les connaissances qu’il nous reste à acquérir…