Quelle est la probabilité que des données ouvertes et liées fassent découvrir une chose qu’on ne connaît ou ne cherche pas? Le potentiel de découvrabilité d’une offre culturelle sous forme de données avec les technologies du Web sémantique est très faible. Pourtant, l’Appel de projets pour le développement culturel numérique dans la francophonie canadienne privilégie la « production et la diffusion la plus large possible de métadonnées (idéalement sous forme de données ouvertes et liées) ». Les arguments qui soutiennent cette orientation gagneraient à être partagés et discutés au sein de comités scientifiques et techniques.
Continuer la lecture de Quel est le potentiel de découvrabilité des données ouvertes et liées?Archives par mot-clé : marketing

Redéfinir la découvrabilité pour une pensée stratégique
Potentiel pour un contenu, disponible en ligne, d’être aisément découvert par des internautes dans le cyberespace, notamment par ceux qui ne cherchaient pas précisément le contenu en question.
C’est une vision qui rend attrayante une solution aussi improbable que des métadonnées pour influencer Google. Mais surtout, une telle démarche élude l’étape la plus importante d’un projet qu’est la réflexion stratégique.
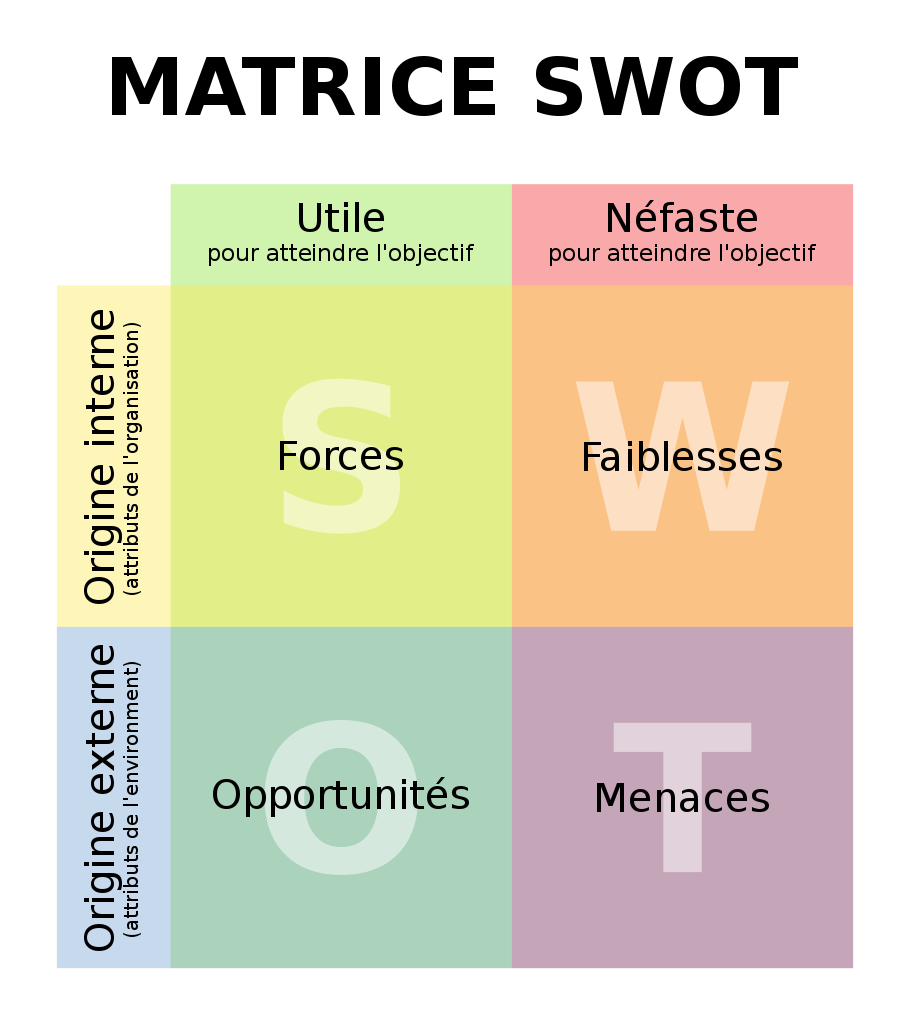
Comprendre une problématique multidimensionnelle
Une analyse stratégique permet pourtant d’identifier les facteurs internes (forces, faiblesses) et externes (opportunités, menaces) qui peuvent faciliter ou entraver la réalisation des objectifs souhaités. En voici des exemples:
Force (facteur interne): la connaissance de l’environnement technologique préconisé est suffisamment maîtrisée par la direction pour communiquer clairement sur les résultats tangibles attendus (ce que ça peut faire) et dissiper le fantasme du techno solutionnisme (ce que ça ne fait pas).
Menace (facteur externe): des pratiques industrielles et modèles d’affaires rendent des contenus indisponibles ou introuvables, comme l’affirme Philippe Falardeau dans cet article sur la possible fermeture d’un distributeur de films.
Rechercher des résultats concrets
Voici une définition plus précise de la découvrabilité et qui m’apparaît encourager une démarche stratégique:
La découvrabilité est le résultat potentiel de stratégies et moyens mis en œuvre, dans un environnement technologique donné, afin de favoriser des liens entre les intérêts de publics cibles et une offre qu’ils ne connaissent pas ou ne cherchent pas.
Elle comprend les éléments clés d’un questionnement préalable à la recherche d’une solution:
- Le but: problème ou besoin concret (achat, visite, développement de compétences)?
- Les publics cibles: quels sont-ils et quels sont leurs profils d’intérêts?
- L’environnement technologique choisi: quelles sont les particularités de l’espace numérique choisi pour favoriser la découverte? Quelles sont les expertises requises?
***
Il serait essentiel de redéfinir la découvrabilité afin que chaque initiative numérique du domaine des arts et de la culture entreprenne une analyse stratégique. C’est en réalisant une telle démarche, en amont de la recherche d’une solution, que les organisations peuvent développer leur capacité d’adaptation et d’innovation.
Comment améliorer la découvrabilité sur Google?
Pour améliorer la découvrabilité sur Google, mieux vaut utiliser les données là où elles sont vraiment utiles et comprendre les différents types de résultats présentés par le moteur de recherche. En effet, de nouvelles fonctionnalités transforment peu à peu la liste de liens classiques en une interface qui fournit des réponses et des suggestions pour amener les internautes à préciser leurs intentions.
Continuer la lecture de Comment améliorer la découvrabilité sur Google?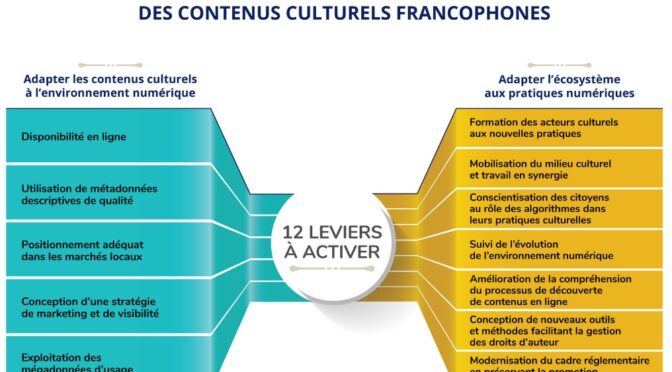
Deux leviers à ajouter au rapport de la mission franco-québécoise sur la découvrabilité
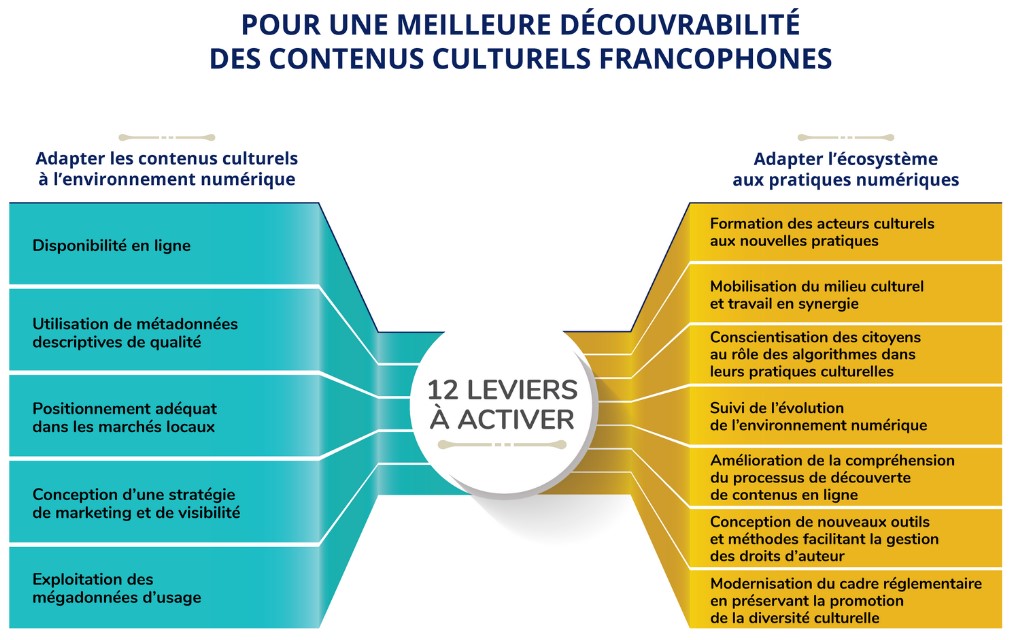
Le rapport sur la découvrabilité en ligne des contenus culturels francophones résulte d’une mission conjointe des ministères de la Culture du Québec et de la France. Il dresse un bon état des lieux d’un ensemble de phénomènes et d’actions, sans égarer le lecteur dans les détails techniques. Un excellent exercice de synthèse, donc, réalisé par Danielle Desjardins, auteure de plusieurs rapports pour le secteur culturel et collaboratrice du site de veille du Fonds des médias du Canada.
Cependant, dans le schéma des 12 leviers à activer pour une meilleure découvrabilité des contenus culturels francophones (voir plus haut), il manque à mon avis deux éléments essentiels:
- Est-ce aux acteurs culturels que revient la charge de rendre l’information concernant leurs créations ou leurs offres numériquement opérationnelle?
- Quel espace numérique offre les meilleures conditions de repérabilité, d’accessibilité et d’interopérabilité de l’information ?
Premier levier: mises à niveau des métiers du Web
Il est important de sensibiliser les acteurs culturels à l’adoption de pratiques documentaires telles que l’indexation de ressources en ligne. Ceci dit, la mise en application des principes, ainsi que le choix de modèles de représentation de contenus en ligne, sont des compétences qui ne s’acquièrent pas comme on apprend à se servir d’un logiciel. On ne peut pas attendre de toute personne et organisation du secteur culturel de tels efforts d’apprentissage. D’autant plus que la production de l’information pour le numérique fait appel à des méthodes et savoirs relevant des domaines du langage et de la représentation des connaissances autant que des technologies numériques.
Si les données structurées sont perçues comme des solutions pouvant accroître la visibilité d’offres culturelles sur nos écrans, elles appartiennent à des domaines de pratiques pas suffisamment maîtrisés au sein des métiers du Web. C’est pourtant bien vers des spécialistes en développement, intégration, référencement et optimisation que se tournent les acteurs culturels cherchant à rendre le contenu de leurs sites web plus interprétable par des machines. Or, à ma connaissance, il n’existe actuellement pas de formation et de plan de travail tenant compte de l’interdépendance des volets sémantiques, technologiques et stratégiques du web des données.
Il devient de plus en plus impératif d’identifier les connaissances à développer ou à approfondir chez les divers spécialistes contribuant à la conception de sites web aux contenus plus repérables. Il serait également souhaitable de soutenir un réseau de veille interdisciplinaire ayant pour objectif de contextualiser et d’analyser l’évolution de l’écosystème numérique.
Exemple: dans la foulée d’une étape importante de ses capacités d’interprétation (traitement automatique du langage), Google a mis à jour, cet été, ses directives d’évaluation de la qualité de l’information. Il va sans dire que c’est important.
Deuxième levier: modernisation des sites web
Dans le Web des moteurs de recherche intelligents, la reconnaissance des entités passe par l’indexation de pages web et l’analyse des contenus. Les sites web devraient donc être des sources d’information de première qualité, tant pour les internautes que pour les moteurs de recherche.
Est-il normal de ne pas trouver toute l’information, riche et détaillée, sur le site de référence d’une entreprise culturelle? Pour le bénéfice des projets numériques, il est vital de concevoir des contenus pertinents pour les machines, lesquelles évaluent à présent la qualité des sources d’information afin de générer la meilleure réponse à retourner à l’utilisateur.
Pour une productrice ou un artiste, il est beaucoup plus stratégique de faire de son site web une source primaire, en attribuant une page spécifique à la description de chaque œuvre, que de créer un article sur Wikipédia. Rappelons que Wikipédia n’est pas une source primaire pour les moteurs de recherche. De plus, l’usage du vocabulaire (Schema.org) ne leur fournit qu’un signal faible sur la nature d’une offre.
Un savoir commun, entre information et informatique
L’adaptation des contenus culturels à l’environnement numérique repose, avant tout, sur de meilleurs sites web. Ces espaces offrent les conditions optimales d’autonomie, repérabilité, accessibilité et interopérabilité. Leur modernisation requiert des acteurs clés, que sont les spécialistes du Web, une mise à niveau rapide de leurs connaissances et de leurs pratiques.
Finalement, afin d’opérer cette mise à niveau et de développer ces savoirs communs, il faut bien entendu insister sur l’interdisciplinarité entre les métiers du web et, notamment, le domaine des sciences de l’information.

Découvrabilité: des métadonnées, oui, mais dans quel but?

Retour sur des notes prises en lisant des propositions de projets numériques.
À la recherche de la stratégie perdue
L’absence de réflexion stratégique est le talon d’Achille de la plupart des propositions de projets et de plans de découvrabilité. Pourtant, qu’il s’agisse de baliser des types de contenu à l’intention des moteurs de recherche ou de décrire des ressources dans un catalogue en ligne, la production de métadonnées utiles s’appuie sur la connaissance des publics cibles et des résultats recherchés.
La meilleure façon d’évaluer le résultat des efforts déployés pour qu’une offre ou un contenu rejoigne ses publics est de fixer des objectifs mesurables et réalistes. Et pour cela, il faut avoir élaboré une stratégie basée sur la connaissance du marché, des opportunités et des contraintes propres à l’organisation.
Les connexions entre votre offre et ses publics cibles
Les algorithmes des plateformes évoluent vers une personnalisation accrue des réponses qu’elles proposent en s’appuyant sur les profils de leurs utilisateurs. Nos sites web devraient faire de même en fournissant des éléments d’information qui « parlent » aux publics cibles et qui, conséquemment, facilitent le travail des moteurs de recherche.
Petit rappel: nous découvrons de l’information sur l’interface d’un moteur de recherche, mais c’est celui-ci qui la trouve. Et cela, en fonction d’un traitement algorithmique fondé sur :
- la popularité (ou l’autorité) des contenus;
- leur similarité avec le profil et l’historique de navigation de l’utilisateur.
Avant de tout miser sur des métadonnées
Voici quelques éléments clés sur lesquels réfléchir avant de déterminer les activités à réaliser dans le cadre d’un plan de découvrabilité:
- Peu importe les activités évoquées par le terme, la découvrabilité n’est mesurable qu’à l’aide des objectifs déterminés par la stratégie. Pas de stratégie: pas d’objectifs donc pas d’évaluation des résultats. Et cela s’applique autant à une stratégie de promotion qu’à des initiatives de mutualisation de données et de modélisation de connaissances pour le web sémantique.
- Les moteurs de recherche ne sont que l’un des vecteurs de la découverte. Celle-ci n’advient pas que par l’entremise de machines car la recommandation est encore largement sociale — réseaux sociaux, réseaux professionnels et académiques, bibliothécaires, libraires, médias et publications spécialisées. Les métadonnées ne sont que l’un des moyens à mettre en œuvre, au même titre qu’une page Facebook ou une chaîne YouTube, au service d’une stratégie.
- Se contenter d’intégrer des balises ne permet pas aux moteurs de recherche de fournir aux utilisateurs les réponses correspondant le plus à leurs profils ni de différencier une offre au sein d’une même catégorie, comme des événements, par exemple.
- Les deux cotés d’une même page :
- Métadonnées dans le code HTML: les modèles Schema.org permettent aux moteurs de recherche de catégoriser des types de contenu.
- Données dans le contenu d’une page web: certains éléments d’information repérables, tels que des entités nommées et des mots clés, facilitent la contextualisation et la personnalisation des résultats de recherche.
- Il faut se tenir bien informé de l’évolution du moteur de recherche et de ses consignes d’utilisation avant d’indexer des offres avec Schema.org. Les objectifs de Google varient dans le temps, selon les types de contenu et selon les ententes qu’il conclut avec certaines grandes sources de données, comme par exemple, des plateformes musicales.
- Un site web qui fournit de l’information structurée pour des machines et qui contribue à un écosystème de liens utiles pour des humains est un excellent investissement stratégique.
- Tous les acteurs de l’écosystème numérique d’une offre culturelle contribuent au rayonnement de celle-ci par l’information offerte sur leurs sites web . Ceux-ci participent également au déploiement d’un réseau d’hyperliens fournissant des données contextuelles aux moteurs de recherche et des parcours de découverte aux humains.
- Un bon plan de découvrabilité résulte d’une connaissance des publics cibles et de l’utilisation réfléchie et coordonnée de différents outils: référencement, modèles Schema.org, contributions à Wikipédia et Wikidata, publications sur des réseaux sociaux, campagnes de promotion et publicité.
Il n’existe pas de recette gagnante: une stratégie de visibilité et de rayonnement est spécifique à chaque projet. Le succès d’un plan découvrabilité dépend de choix qui sont alignés sur cette stratégie afin de publier la bonne information, dans le bon format, au bon endroit et pour le bon public.
Produire des données : entre outils de marketing et bases de connaissances
La découverte optimisée pour les moteurs de recherche est-elle la seule solution pour accroître la consommation de contenus culturels locaux ? Sommes-nous à la recherche de nouveaux outils de marketing ou souhaitons-nous développer des bases de connaissances communes ? Les résultats attendus à court terme, par nos programmes et partenaires sectoriels, pèsent sur les choix qui orientent nos actions.
La découverte optimisée pour les moteurs de recherche
Google poursuit son évolution pour devenir notre principale interface d’accès à la connaissance. La tendance zéro clic est une forme de désintermédiation des répertoires qui est similaire à celle que connaissent les sites des médias. Il y a quelques années que les réseaux de veille prédisent la transition des moteurs de recherche vers des moteurs de réponse.
Alors, est-il stratégique de baliser nos pages web avec des métadonnées (aussi appelées données structurées) pour que des machines comprennent et utilisent nos contenus dans leurs fiches de réponse ?
Améliorer le potentiel d’une information d’être repérée et interprétée par un agent automatisé est une bonne pratique à intégrer dans toute conception web, au même titre que le référencement de site web. Mais se contenter de baliser des pages pour les seules fins de marketing et de visibilité n’est pas stratégique. Voici pourquoi:
- Architecture de l’information conçue pour servir des intérêts économiques et culturels spécifiques.
- Aucun contrôle sur le développement de la base de connaissances.
- Uniformité de la présentation de l’information, quel que soit le pays ou la culture.
- Modèle et vocabulaire descriptifs simples, mais adaptés à des offres commerciales (une bibliothèque publique est une entreprise locale).
- Le moteur de recherche n’utilise que certains éléments du vocabulaire Schema.org et modifie son traitement des balises au gré de ses objectifs commerciaux (voir ce billet sur les mythes et réalité de la découvrabilité).
Des données pour générer de la connaissance
Les plans de marketing et de promotion ont des effets à court terme, mais ponctuels, sur la découverte. Cependant, nous devons parallèlement développer les expertises nécessaires pour concevoir de nouveaux systèmes de mise en valeur des offres culturelles et de recommandation qui répondent à nos propres objectifs. Ne pas également prioriser cette avenue, c’est accumuler une dette numérique et accroître notre dépendance envers les plateformes et tout promoteur de solution.
Comme je l’ai souligné en conclusion d’un billet rédigé lors de recherches sur la découvrabilité et la « knowledge card » de Google, « , apprendre à documenter des contenus sous forme de données est une étape vers le dévelopement de « nos propres outils de découverte, de recommandation et de reconnaissance de ceux qui ont contribué à la création et à la production d’œuvres. »
Pour cela, il faut élaborer collectivement nos propres stratégies pour faire connaître le contenu de répertoires et rejoindre de nouveaux publics. Nous serions, alors, en mesure de concevoir des moyens non intrusifs pour collecter l’information qui permet de comprendre la consommation culturelle.
Adopter une méthode de travail pour une réflexion stratégique
Concevoir et réaliser des projets autour de données liées (ouvertes ou non) demande un long temps de réflexion et d’échanges de connaissances entre des acteurs qui ont des perspectives différentes. L’initiative de la Cinémathèque québécoise peut être citée comme un excellent exemple de transformation organisationnelle par l’adoption d’une nouvelle méthode de travail. Marina Gallet pilote ce projet qui vise à formaliser les savoirs communs du cinéma en données ouvertes et liées. Elle a gracieusement partagé cette expérience lors de la dernière édition du Colloque sur le web sémantique.
Représentation de la diversité culturelle et linguistique
Il existe de nombreuses façons de décrire les oeuvres d’un album de musique ou un spectacle de danse. Pour représenter ces descriptions sous forme de données, il existe des modèles et vocabulaires pour différentes missions et utilisateurs. Une part grandissante de ces vocabulaires est en données ouvertes et liées. Ces descriptions ne sont pas toujours structurées ou conformes aux standards du web, mais leur diversité est essentielle à la richesse de l’information. Il est vital que les vocabulaires utilisés pour décrire des offres et des contenus soient en français pour que la francophonie soit présente dans le web des données et qu’elle soit prise en compte par les systèmes intelligents.
Le Réseau canadien d’information sur le patrimoine annonçait ce printemps, la réalisation de la version française de référentiels en données ouvertes et liées. Philippe Michon, analyse pour le RCIP, explique comment ces référentiels essentiels au patrimoine culturel seront rendus disponibles en données ouvertes et liées.
Recherche augmentée: découverte selon les goût et l’expérience recherchée
Il faut cesser de reproduire des interfaces et modes d’accès aux répertoires qui sont dépassés. On ne peut cependant améliorer la découverte sans investir le temps et les efforts nécessaires pour sortir de nos vieilles habitudes de conception.
Nos interfaces de recherche sont devenues obsolètes dès l’arrivée du champ unique des premiers moteurs de recherche. Nos stratégies de marketing de contenu pour le référencement de pages web aident les moteurs de recherche à répondre à des questions, mais effacent les spécificités en uniformisant l’architecture de l’information.
L’information qui décrit nos productions culturelles et artistiques est trop souvent limitée à des données factuelles. Il faut annoter des descriptions avec des attributs et caractéristiques riches et orientés vers divers publics et usages. Des outils d’analyse et de recommandation peuvent ainsi fournir de l’information ayant une plus grande valeur. Il ne faudrait pas espérer refiler ce travail à des intelligences artificielles: l’indexation automatique ne produira pas nécessairement des métadonnées utiles et pertinentes pour une stratégie de valorisation. De plus, il ne faut pas sous estimer la valeur que l’expérience humaine (éditorialisation, sélection, critique, mise en contexte) apporte à des services qui jouent un rôle prescripteur.
Soutenir le dévelopement de bases de données en graphes
La mise en valeur de répertoires et collections, ainsi que des actifs informationnels (textes, images, sons) d’organisations ne devrait plus reposer sur des bases de données classiques. Les bases de données en graphes permettent de raisonner sur des données et de générer de la connaissance , en faisant des liens, à l’image de la pensée humaine:
Quelle est le parfum de glace préféré des personnes [qui] dégustent régulièrement des expresso, mais [qui] détestent les choux de Bruxelles ? Une base de donnée Graph peut vous le dire. Comment ? Avec des données de qualité, les bases de données Graph permettent de modéliser les données et de les stocker de la manière dont nous pensons et raisonnons dans le monde réel.
Ceci est tiré d’un bon article de vulgarisation sur les bases de données en graphe.
Choisir des méthodes de travail adaptées aux projets collectifs
Pour qu’un écosystème diversifié de connaissances (multidisciplinaire, multi acteurs) soit durable, il doit reposer sur la distribution des fonctions de production et de réutilisation des données entre des partenaires. Il faut aussi réunir des initiatives collectives dans une démarche où le développement de connaissances et l’expérimentation ne sont pas relégués au second plan par des intérêts individuels ou commerciaux. Enfin, il faut élaborer et adopter de nouvelles méthodes de travail pour des projets collectifs.
Je reviendrai bientôt sur les éléments nécessaire pour la gestion participative d’une base de connaissances commune.
Architectures et bases de connaissances
Définir les finalités et les modalités des projets de liage de données est un long cheminement qui demande des apprentissages, des efforts concertés et du temps. Nos programmes devraient être revus. Mettre en place les conditions de réussite d’un projet collectif est un projet en soi. Il faut tenir compte d’un cadre de formation, d’une nouvelle méthode de travail et d’une progression dans la durée. Exiger des résultats à court terme oriente les projets vers des « solutions » et laisse peu de place à la remise en question des habitudes.
Nos initiatives doivent être conjuguées pour élaborer une architecture commune de la connaissance. Parce qu’elle sort du cadre de nos actions habituelles, c’est une avenue qui offre plus de potentiel, à plusieurs titres, que des stratégies de visibilité et de marketing.
Découvrabilité et métadonnées: nous sommes nuls en documentation de contenu
La documentation des contenus devient un enjeu prioritaire quand des moteurs de recherche deviennent moteurs de réponses et de suggestions. Surtout dans le domaine des arts et de la culture. Curieusement, nombreuses sont les initiatives qui font dans le dilettantisme en matière d’information numérisée. Car le problème est bien d’ordre documentaire. Petite mise en perspective à la lumière de l’actualité.
« From search to suggest» (Eric Schmidt, Google)
Les ventes d’enceintes acoustiques intelligentes (smart speakers) dépassent celles d’autres équipements électroniques comme les casques de réalité virtuelle ou les vêtements connectés. Les grandes plateformes et leurs partenaires (de nombreux manufacturiers d’enceintes acoustiques) se livrent à une concurrence effrénée, enchaînant les itérations afin de lancer et tester de nouveaux modèles.
/…/ smart speakers have become the fastest growing consumer technology in recent times, surpassing market share gains of AR, VR and even wearables.
Smart speakers are now the fastest-growing consumer technology
Depuis peu, certains constatent que ce sont des applications et des algorithmes qui nous pointent ce que nous devrions voir ou écouter.
/…/ how consumer power can meaningfully express itself within the “Suggest” paradigm, if consumer power will continue to exist at all. If the Amazon Echo, Google Home, or whatever else that comes down the pike becomes the primary way of consuming podcasts, the radio, or music, what does the user pathway of selecting what to listen look like? How are those user journeys structured, how can they be designed to push you in certain ways? (The “Power of the Default,” by the way, is a very real thing.) How would discovery work? Which is to say, how does the market look like? Where and how does the consumer make choices? What would choice even mean?
If podcasts and radio move to smart speakers, who will be directing us what to listen to?
C’est un constat que partagent plusieurs observateurs des changements qui sont à l’oeuvre dans le web , notamment chez ceux dont la puissance s’est établie sur l’indexation et le classement de l’information. Laurent Frisch, directeur du numérique de Radio France, est l’un de ces observateurs.
Dans tous les cas, la problématique des assistants vocaux est de passer d’un monde où on pouvait faire des recherches mises en ordre par des algorithmes, nous laissant le choix de cliquer sur le résultat de notre choix, à un monde dans lequel les besoins seront anticipés avec la proposition d’une réponse unique. Il faut donc que lorsque nous avons la bonne réponse, nous puissions être trouvés et écoutés au bon moment. C’est très compliqué, c’est nouveau pour tout le monde. Les radios ont un atout : elles partent avec un temps d’avance puisqu’elles ont une matière première. Par contre, ça ne veut pas dire que ce sera automatique. Il y aura des challenges, notamment pour réussir à être des réponses pour ces assistants vocaux.
La radio en 2018 vue par Laurent Frisch
Penser/Classer (George Perec)
Nous avons un problème: nous avons abandonné l’indexation et le classement de nos ressources à des bases de données qui ne sont pas conçues pour être interopérables avec d’autres systèmes et à des spécialistes des technologies qui n’ont ni les compétences en documentation, ni les connaissances du domaine (ontologies, taxonomie).
Nous avons cessé d’investir temps et ressources dans la documentation de nos contenus lorsque la micro informatique est entrée dans nos organisations. Nous nous sommes fiés à des structures proposées par des programmeurs guidés par leurs propres objectifs et compréhension pour créer des métadonnées et des systèmes de classement. Ces systèmes nous interdisent toute visibilité sur nos contenus, collections et répertoires et toute possibilité de lier nos données aux autres données mondiales afin que nos contenus demeurent pertinents et génèrent de la connaissance.
Les enjeux de la découvrabilité, les métadonnées propriétaires et non standards, ainsi que la faible qualité des données sont avant tout un problème documentaire du à l’ignorance ou au rejet de méthodes et normes qui, pourtant, existent et évoluent. Ce problème ne pourra être résolu que si nos stratégies numériques, ainsi que nos institutions d’enseignement, passent d’une vision technocentriste à une vision systémique du numérique. Concrètement, cela implique l’ajout de la littératie de l’information (de quoi est faite l’information numérisée et comment circule-t-elle) aux programmes de formation, l’adoption de normes pour l’acquisition et le développement d’applications et l’inclusion des compétences en sciences de l’information à toute démarche autour des données.
Comme l’a si clairement expliqué Fabienne Cabado , directrice générale du Regroupement québécois de la danse, dans un récent billet, c’est notre modèle de pensée et nos réflexes qu’il faut changer.
/…/le virage numérique ne consiste pas à numériser nos archives ni à produire les plateformes les plus grandioses, mais plutôt à transformer nos manières de regarder le monde, de le penser, de le construire et d’y évoluer. Ils l’ont dit et répété: l’innovation réside avant tout dans l’adoption d’une pensée systémique.
Perspectives numériques
En attendant que nos leaders prennent la mesure du problème et apprennent à se servir d’autres solutions que celles auxquelles ils sont habitués, il est encourageant de constater le cheminement des idées et leur assimilation par les têtes pensantes du secteur culturel.

Culture et numérique : créer une nouvelle plateforme ou adapter le système ?
N’en déplaise à ceux et celles qui n’ont vu que dénigrement et manque d’ambition dans les réactions qui ont suivi la proposition d’Alexandre Taillefer (vidéo, 43:39 min.), celle-ci a favorisé des échanges révélateurs de la véritable nature de la transformation numérique à poursuivre. Proposer la création d’une nouvelle plateforme culturelle ne fait que remettre à plus tard les nécessaires adaptations qu’un système doit entreprendre pour durer et prospérer.

Face à complexité: la diversité des perspectives
La réaction de Sylvain Carle, exprimée à chaud lors de cette première édition du Forum Culture + Numérique, a été répercutée sur les médias sociaux.
Tellement pas d’accord avec la vison de plate-forme « du Québec pour le Québec » de @ataillefer. Un modèle anti-internet, anti-ouverture. #fcn
— Sylvain Carle (@sylvain) 21 mars 2017
À l’émission de radio La sphère, diffusée le samedi suivant l’événement, Martin Lessard en a fait le sujet de sa chronique. Même les médias grands publics ont repris ce qui semblait une polémique, mais qui pourrait être le début d’échanges qui n’ont jamais eu lieu de façon ouverte et avec toutes les parties concernées.
Il y aurait pourtant lieu de faire converger les différentes lectures des causes et des symptômes du malaise croissant qui afflige plus spécifiquement les domaines des arts et de la culture dans le contexte de la transformation numérique. Ces quelques publications témoignent de la diversité des perspectives et des approches proposées pour une même problématique. Cette diversité constitue, selon moi, notre meilleure outil pour faire face à la complexité des changements qui se manifestent différemment et à divers niveaux dans des systèmes qui sont tous interdépendants.
Voici quelques perspectives qui sont toutes pertinentes et guidées par la recherche de solutions:
- De plates-formes et de ressources: numériques et physiques, par Sylvain Carle
- Taillefer.coop, par Patrick Tanguay
- Plateformisation: l’exemple DuProprio, par Stéphane Guidoin
- Extrait d’un long commentaire d’Yves William à la suite du partage de mon billet sur Facebook:
Le grand défi n’est-il pas plutôt de faire se rencontrer ces ressources mutualisées et les usagers/consommateurs? ET si au contraire, Taillefer et toi étiez du même combat?
Ce que je vois, c’est que vous êtes sans doute du même combat, mais à deux bouts du spectre. Toi, du côté de la ressource, du produit, de l’œuvre, et la mise en place des infrastructures qui faciliterait leur découvrabilité. Mais comme tu dis : « l’offre culturelle est abondante et que notre attention, elle, est limitée. » Et le problème est tout là. Cet aspect manque à ton équation. Non seulement notre attention est limitée, mais elle est dirigée, elle est détournée… par ces grandes plateformes. Taillefer, quant à lui, avec sa proposition, ne s’occupe que de l’usager; il aimerait créer un canal pour attirer l’usager et faire pointer son « attention » ailleurs, sur d’autres produits, d’autres biens et services. Locaux, ceux-là.
Et si finalement ces deux bouts du spectre devaient travailler ensemble, travailler soutenir la visibilité des ressources et des produits, mais aussi sur cette attention dispersée des usagers ?
Mais d’accord, il faut oublier la plateforme.
- Suzanne Lortie, professeure à l’École des médias de l’UQAM, a commenté, comme suit, un article sur Facebook:
C’est ça, je crois, qui motive Alexandre Taillefer. Et c’est bien parfait.
« What Amazon Prime is selling most of all is time. Every executive I spoke to, when asked about how it all fits together, cites this desire to get you whatever you want in the shortest window possible. Stephenie Landry, the Amazon vice president who launched Prime Now in 2014 and has overseen its expansion into 49 cities in seven countries, explains that her business merely has to answer two questions: “Do you have what I want, and can you get it to me when I need it?” The rest of the customer experience is built around answering both questions in the affirmative. »
Why Amazon Is The World’s Most Innovative Company Of 2017
Et dans ses interventions qui émaillaient le fil des commentaires, elle a évoqué le modèle de rémunération du risque dans le cadre d’investissements publics; un modèle dont l’inadéquation affecte plus spécifiquement les nouveaux produits culturels.
» si la discussion porte en même temps sur la reconfiguration des marges des détaillants et la mutualisation de la logistique, il faut donc commencer par le commencement pour les produits culturels: revoir les notions de pari passu, les piscines qui se remplissent consécutivement. »
Les systèmes grâce auxquels nos contenus culturels et artistiques sont produits et diffusés doivent s’adapter au contexte numérique pour y jouer un rôle plus proactif. N’y a-t-il pas là des discussions qui sont trop souvent éludées, mais qu’il faudrait avoir le courage d’accueillir ?
Politique culturelle en crise ?
Certains états d’Asie ont, dès le début du 21ième siècle et alors que se développaient de nouveaux modèles économiques, pris des mesures visant à protéger leur culture et leurs productions. La culture a été intégrée à la politique industrielle de la Corée afin de préserver son identité culturelle et de favoriser ses productions au sein des marchés national et international. Protectionnisme ? Peut-être, mais il s’agissait avant tout de rechercher un équilibre entre productions culturelles nationales et étrangères auprès des consommateurs.
Même si la présence, dans une même phrase, des mots « culture » et « économie » soulève la méfiance de plusieurs, il faut lire les publications résultant d’ateliers menés par des universitaires en économie, arts, culture et communication à propos des échecs des économies créatives et du recadrage des politiques culturelles. Selon un des auteurs, une économie de la culture devrait avoir pour éléments clés des politiques industrielle, des médias, de la ville, des arts, des artistes et autres travailleurs culturels, ainsi que de la culture et du développement durable. Selon lui, une politique industrielle, adaptée aux spécificités du domaine culturel, ne devrait plus être uniquement une stratégie de production, mais tenir compte de l’ensemble de l’écosystème, ce qui inclut la consommation (ou l’audience).
» if we do introduce the question of cultural value into industrial policy then this cannot be simply a strategy for production – as Nicholas Garnham saw long ago. The market, the audience, the public and how they consume, access, participate, judge, learn, share and adapt has to be an essential part of an ‘industrial’ strategy. Production and consumption have to be seen as a whole in terms of cultural as well as economic value. »
After the Creative Industries: Cultural Policy in Crisis
Nous avons eu des consultations sur le renouvellement de la politique culturelle et sur la stratégie numérique du Québec, mais rarement abordons-nous les enjeux socio-économiques auxquels nous faisons face autrement que par le biais d’initiatives aux objectifs bien spécifiques et, conséquemment, aux impacts limités. En investissant nos efforts sur la création de nouveaux éléments plutôt que d’adapter nos systèmes, ne rendons-nous pas nos industries culturelles encore plus vulnérables aux contraintes externes ?
Pour aller plus loin: Antifragile: Things that gain from disorder, de Nassim Nicholas Taleb.
Nouvelles compétences informationnelles pour modèles numériques
Nous produisons des contenus numériques et nous adoptons de nouveaux outils, mais nos modèles d’affaires et nos stratégies de promotion et diffusion demeurent cependant essentiellement les mêmes. Alors, comment se positionner face aux modèles d’affaires plus rentables et plus attractifs des géants du numérique tels que décrits dans cet article sur une nouvelle classification des entreprises?
/…/ companies that build and manage digital platforms, particularly those that invite a broad network of participants to share in value creation (such as how we all add content to Facebook’s platform or that anyone can sell goods on Amazon’s), achieve faster growth, lower marginal cost, higher profits, and higher market valuations.
Ce qui contribue à leur montée en puissance, c’est la donnée qui leur permet de mettre leurs contenus en avant et de générer de l’information toujours plus précise et pertinente pour la prise de décisions stratégiques.
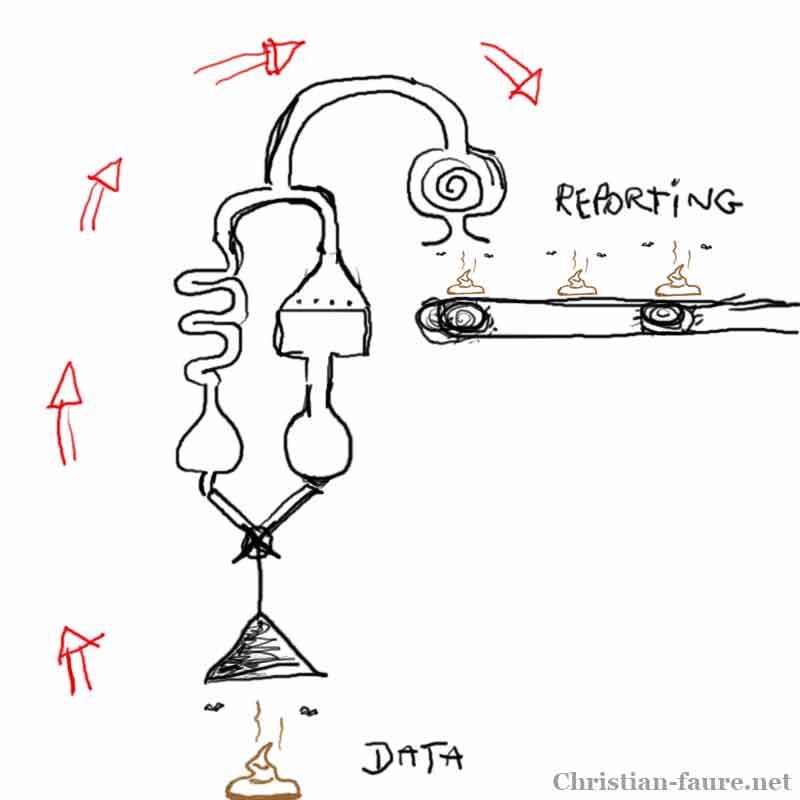
Culture de la donnée? Plutôt, des compétences informationnelles
Malgré les transformations qui accélèrent la mutation des modèles industriels et économiques, les opportunités et enjeux ayant trait à l’exploitation des données sont généralement ignorés dans la plupart des analyses et propositions d’action, qu’il s’agisse de politiques gouvernementales ou d’initiatives entrepreneuriales.
Cette situation s’explique fort probablement par le faible niveau de connaissances en matière d’information; ce qu’on appelle parfois les compétences informationnelles. En effet, si les technologies de l’information au sein de nos organisations ont un pouvoir, des ressources et des budgets dédiés, la matière première — la donnée, le document, l’information et même la connaissance — ne constitue pas une priorité.
Et pourtant. Comprendre de quoi sont faites les données (standards et sciences de l’information) et comment évolue leur exploitation (algorithmes, technologies sémantiques, blockchain) permet d’apprécier les modèles numériques d’une toute autre manière qu’en utilisateur de systèmes: en « créateur de valeur ».
Au cours de la préparation d’un atelier pour la SODEC, dans le cadre de la prochaine édition du SODEC_LAB Distribution 360, j’ai répondu à quelques questions concernant le rôle central des données dans la diffusion et la mesure des contenus, et notamment, leur potentiel de découvrabilité. Deux questions, qui reviennent régulièrement aux cours des présentations, démontrent clairement qu’il est urgent d’élaborer un programme afin de palier le sous développement des compétences informationnelles dans nos organisations, qu’il s’agisse d’une startup ou d’un ministère.
Je partage ici ces questions, ainsi qu’un aperçu des réponses.
Comment peut-on définir simplement ce qu’est une donnée?
Par l’exemple. Voici une donnée:
snow
C’est un « morceau d’information »; la plus petite unité de représentation d’une information. Exploitée individuellement, sans contexte (dont la langue) ou d’autres données, cette donnée peut prendre n’importe quel sens
Nom: Snow
Prénom: Michael
Activité: Artiste
Pays: Canada
Ensemble, des données permettent de produire de l’information, notamment, grâce à la présence de ces données spéciales que sont les métadonnées (meta: auto-référence, en grec). Nom, Prénom, Activité, Pays permettent de comprendre le sens des données auxquelles elles sont reliées, surtout si elles sont dans des formats difficiles à interpréter comme des numéros d’identification.
Les données peuvent être structurées, comme dans les bases de données ou les feuilles de calcul, ou non structurées, comme des textes sur Twitter et Facebook ou des images-commentaires sur Snapchat.
Les données non structurées sont généralement très riches mais requièrent un traitement manuel ou automatisé. Mais, en général, l’exploitation des données fait face à un enjeu majeur: leur hétérogénéité. Les technologies, les modèles de représentation et les formats de données sont autant de silos qui empêchent de relier des données de sources diverses entre elles.
À quelles données pouvons-nous avoir accès?
Il y a une abondance de données accessibles à tous les participants d’un écosystème donné. Chaque individu, chaque organisation est une machine à produire des données.
Par exemple, les industries culturelles produisent des données sur les contenus et sur la consommation de contenu.
Les grandes plateformes numériques excellent dans leur domaine en grande partie pour ces raisons:
Exhaustivité. Elles fournissent sous forme de données et métadonnées, de l’information très détaillée à propos de leurs contenus (description, ambiance, audience, son, couleur, etc.).
Connectivité. Elles savant que les données détaillées qui décrivent leurs contenus génèrent de nouvelles données lorsqu’elles sont liées à des données de consommation ou à d’autres données sur des contenus.
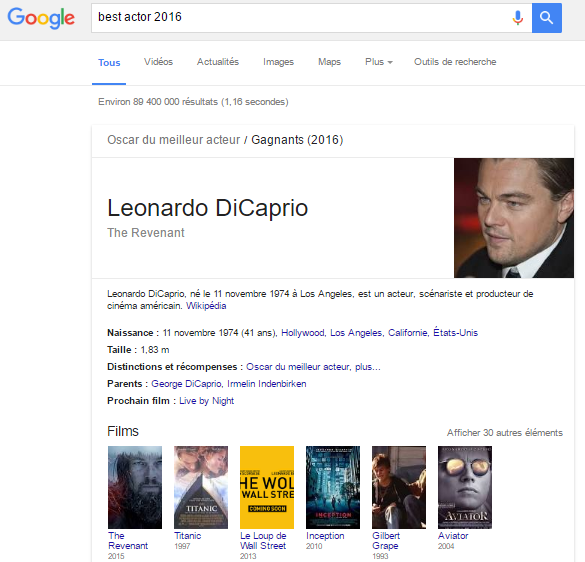
Dévouvrabilité. Elles comprennent le rôle central joué par les données et métadonnées pour la découvrabilité des contenus. De plus en plus de contenus vont à la rencontre de leurs publics, entre autres, par Google qui donne des réponses plutôt que de fournir des listes de destinations où trouver les réponses. Taper « Best actor oscar 2016 », vous y constaterez que Google exploite de façon croissante le graphe des connaissances (knowledge graph) et des données ouvertes et liées (Linked Open Data).
Pertinence. Elles se servent des données pour cibler des consommateurs, mais, de plus en plus, pour créer des contenus ou permettent à des producteurs de proposer des offres qui trouveront plus facilement leurs publics.
Mesure. Elles utilisent ou expérimentent divers indicateurs de mesure, autres que des transactions ou des faits comme des tendance, des modèles de comportement ou, encore mieux: la relation au contenu. Elles pratiquent l’écoute sociale en suivant, par exemple, les conversations sur Twitter avant, durant et après le lancement d’un contenu.
La donnée génère l’information qui est au cœur du modèle économique des puissantes plateformes numériques. Celles-ci ont toujours plusieurs trains d’avance sur leurs compétiteurs (et, souvent, également fournisseurs) dont la vision et les modèles relèvent encore des méthodes de l’ère industrielles. Nos industries culturelles, pour ne citer que cet exemple, disposent d’une masse de données, mais celles-ci sont peu entretenues et exploitées.
Avant de développer un énième silo d’information (plateforme, application), il faudrait peut-être apprendre à connecter nos données et les mettre en réseau pour générer le plus d’effet à long terme pour notre économie et notre culture.

{kind=link}
Pourquoi vos métadonnées musicales sont aussi importantes que votre musique

Pourquoi s’investir autant dans la création et la production d’œuvres musicales et les laisser ensuite devenir graduellement invisibles sur le Web, une fois la campagne de promotion terminée ? Pourquoi laisser aux plateformes technologiques le soin d’identifier et de catégoriser les œuvres ? Pourquoi s’insurger d’une part contre la copie illégale et de l’autre, diffuser des fichiers audio sans données détaillées sur les créateurs et les détenteurs des droits ?
Ces questions surgissent depuis que je contribue à des projets de valorisation de métadonnées dans le domaine de la culture. Ce sont également des enjeux vitaux pour la présence numérique de la musique créée et produite au Québec, Ce sont ces même raisons qui m’amenaient à assister à la présentation de Jean-Robert Bisaillon, lors du MusiQClab du 28 janvier dernier, à Montréal.
Lire la suite sur le blogue de MusiQC numériQC.