Les formations, référentiels, trousses à outils, programmes de financement et experts en découvrabilité abondent. Tous peuvent se saisir des termes et notions qui circulent sans avoir une compréhension approfondie du Web. C’est, à mon avis, préoccupant car il n’existe pas de traité sur ce qu’il faut faire, dans le numérique, pour qu’une information soit vue. À la différence du génie ou de la médecine, par exemple, il n’y a pas de socle commun de connaissances pour les divers métiers du Web. Un projet numérique est souvent une tour de Babel de concepts. Que des non-spécialistes du numérique, comme des directions d’entreprises, soit dépassés n’est pas étonnant.
Continuer la lecture de Découvrabilité: sens commun et connaissances partagéesArchives par mot-clé : apprentissage
De données structurées à contenu structuré
Je le répète: il faut retomber en amour avec nos sites web. Nous devons réinvestir le domaine du langage sur ces espaces numériques privilégiés que sont nos sites web.
Continuer la lecture de De données structurées à contenu structuré
L’angle mort de la promotion de l’offre culturelle sur le Web
![Planche dPlanche de l’Encyclopédie de Diderot et d’Alembert: taille de la plume pour l’écriture. Morburre, [CC BY-SA 3.0], Wikimedia Commonse l’Encyclopédie de Diderot et d’Alembert: Taille de la plume pour l’écriture.](https://fr.wikipedia.org/wiki/Fichier:Ecriture-TaillePlume-Encyclopedie.jpg)
Or, ce ne sont plus les balises Schema.org insérées dans le code ni les articles de Wikipédia qui facilitent le travail des moteurs de recherche en les rendant intelligents. C’est, à présent, le traitement automatique du langage naturel. Celui-ci permet aux algorithmes d’évaluer l’information présente sur une page web et lisible par les humains.
Plus l’information offerte par le texte est riche et contextualisée par des liens vers d’autres pages web, plus elle a de valeur pour nous et, par conséquent, pour les moteurs de recherche dont l’objectif est de nous offrir les meilleurs résultats possibles.
Un travail de spécialistes
Après quelques années d’accompagnement d’entrepreneurs culturels, je peux affirmer que rares sont les non-initiés sachant manier avec aisance des notions et des mécanismes qui demeurent complexes, même pour des spécialistes du Web. Ce billet sur les définitions divergentes de ce qu’est une ontologie permet de mesurer le défi d’établir une compréhension commune et claire d’une notion pourtant fondamentale des systèmes documentaires. Et pour celles et ceux qui persévèrent, les concepts et pratiques nouvellement acquis sont trop éloignés de leurs activités pour qu’ils soient en mesure de les intégrer aux opérations et de se livrer à la veille technique qui s’impose en permanence.
Structurer de l’information pour une variété d’usages et de systèmes, c’est un travail de spécialistes. Le rôle de créateurs de contenu consiste à documenter cette information et à raconter comment elle s’insère dans notre monde. Ils peuvent se faire aider afin de produire l’information répondant le mieux aux intérêts des publics cibles et de fournir des liens nécessaires aux humains et aux machines pour apporter du contexte, favorisant ainsi la découverte.
Voici les étapes qu’il faudrait suivre afin d’améliorer la valeur informative de la page web consacrée à une offre culturelle:
1- Stratégie: quelle information, à quels publics, pour quels résultats
Mieux un contenu est documenté, plus il est susceptible de pouvoir réponse à une question. Il est donc important de baser la conception du contenu d’une page sur une solide connaissance des publics cibles. D’où la nécessité d’une stratégie et d’une concertation entre les producteurs, diffuseurs et toutes autres parties concernées. Toutefois, l’élaboration d’une stratégie de ce type requiert une formation préalable mobilisant divers spécialistes.
2- Documentation: les choses et les relations entre ces choses
L’adaptation de nos contenus culturels à l’environnement numérique commence par l’écriture. Tous les éditeurs de sites web doivent à présent mieux organiser et documenter leurs contenus pour les rendre plus repérables. Pour Google, « documenter » signifie: bien décrire un contenu et fournir du contexte en faisant des liens entre des concepts. Plus la documentation est exhaustive et clairement libellée, plus elle a de la valeur pour les utilisateurs — et plus la page web de l’offre culturelle devient une source d’information de qualité.
3- Balises: signaler certains types de contenus
Certains types de contenus — comme les vidéos, par exemple — peuvent apparaître sous forme d’extraits, dans la liste de résultats de Google (résultats enrichis). L’utilisation de balises permettant de catégoriser des contenus n’est donc pertinente que pour un petit nombre d’offres. Les modèles descriptifs recommandés sont ceux qui concernent les projets de développement des services du moteur de recherche. De plus, les consignes à suivre évoluent en fonction du résultat des expérimentations et de l’avancement du traitement automatique du langage.
Nous devons, alors, éviter de développer des fonctionnalités qui deviennent rapidement obsolètes ou, pire, qui réduisent notre capacité d’innovation en l’encadrant dans la logique d’affaires d’une plateforme. Il faut donc que nous demeurions extrêmement vigilants afin que nos projets nous apportent une réelle valeur et ne tombent pas dans le solutionnisme technologique.
4- Wikipédia: création d’article utile, mais non essentielle
Wikipédia facilite l’identification d’un concept ou objet spécifique, mais ce sont les pages web qui sont les sources primaires pour Google. Contrairement à la croyance courante, la production d’une fiche de réponse (appelée « knowledge panel ») résulte du traitement du contenu provenant de différentes pages web. Celles-ci sont qualifiées par le moteur de recherche pour l’information qu’elles offrent. En analysant certains brevets déposés par Google, on peut déduire que son utilisation de l’encyclopédie n’est ni constante, ni déterminante. Créer un article Wikipédia n’est donc pas une activité essentielle dans un plan de découvrabilité, même si cela peut accroître la notoriété d’un sujet lorsqu’il contient des connaissances utiles et des liens vers d’autres articles.
L’écriture: une « solution » à la portée de tous!
Adapter nos contenus culturels à l’environnement numérique commence donc par une technique millénaire: l’écriture. Nous pourrions beaucoup mieux documenter nos offres culturelles sur nos sites web sans nécessairement plonger dans des domaines de connaissance complexes. Il suffit d’apprendre à décrire des choses et les relations entre ces choses pour des systèmes qui, eux-même, apprennent à lire afin de fournir la meilleure information à leurs utilisateurs. Bref, avant de se lancer dans la modélisation de données ou le web sémantique, il serait temps de revenir aux stratégies de communication, ainsi qu’aux bonnes pratiques de rédaction web.
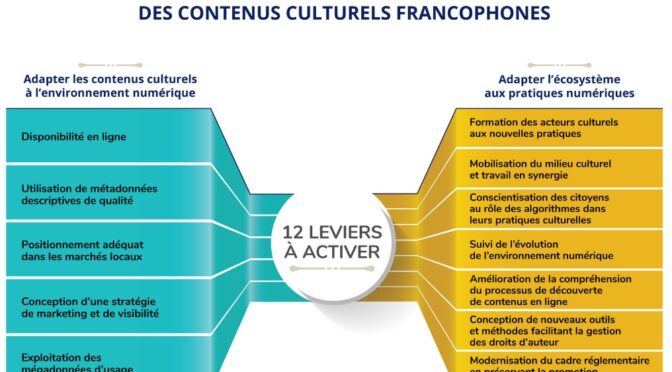
Deux leviers à ajouter au rapport de la mission franco-québécoise sur la découvrabilité
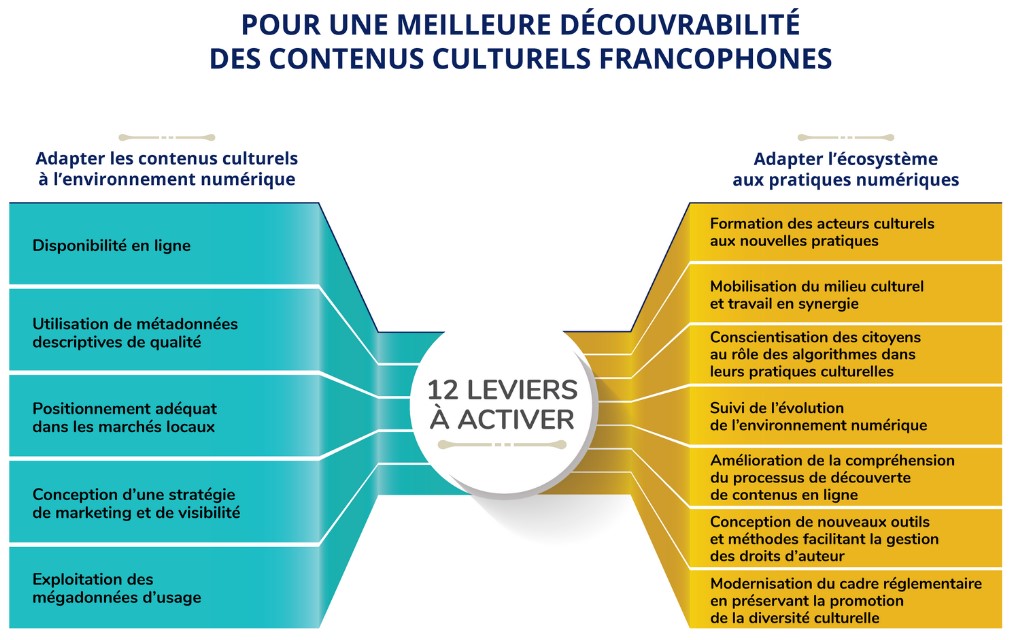
Le rapport sur la découvrabilité en ligne des contenus culturels francophones résulte d’une mission conjointe des ministères de la Culture du Québec et de la France. Il dresse un bon état des lieux d’un ensemble de phénomènes et d’actions, sans égarer le lecteur dans les détails techniques. Un excellent exercice de synthèse, donc, réalisé par Danielle Desjardins, auteure de plusieurs rapports pour le secteur culturel et collaboratrice du site de veille du Fonds des médias du Canada.
Cependant, dans le schéma des 12 leviers à activer pour une meilleure découvrabilité des contenus culturels francophones (voir plus haut), il manque à mon avis deux éléments essentiels:
- Est-ce aux acteurs culturels que revient la charge de rendre l’information concernant leurs créations ou leurs offres numériquement opérationnelle?
- Quel espace numérique offre les meilleures conditions de repérabilité, d’accessibilité et d’interopérabilité de l’information ?
Premier levier: mises à niveau des métiers du Web
Il est important de sensibiliser les acteurs culturels à l’adoption de pratiques documentaires telles que l’indexation de ressources en ligne. Ceci dit, la mise en application des principes, ainsi que le choix de modèles de représentation de contenus en ligne, sont des compétences qui ne s’acquièrent pas comme on apprend à se servir d’un logiciel. On ne peut pas attendre de toute personne et organisation du secteur culturel de tels efforts d’apprentissage. D’autant plus que la production de l’information pour le numérique fait appel à des méthodes et savoirs relevant des domaines du langage et de la représentation des connaissances autant que des technologies numériques.
Si les données structurées sont perçues comme des solutions pouvant accroître la visibilité d’offres culturelles sur nos écrans, elles appartiennent à des domaines de pratiques pas suffisamment maîtrisés au sein des métiers du Web. C’est pourtant bien vers des spécialistes en développement, intégration, référencement et optimisation que se tournent les acteurs culturels cherchant à rendre le contenu de leurs sites web plus interprétable par des machines. Or, à ma connaissance, il n’existe actuellement pas de formation et de plan de travail tenant compte de l’interdépendance des volets sémantiques, technologiques et stratégiques du web des données.
Il devient de plus en plus impératif d’identifier les connaissances à développer ou à approfondir chez les divers spécialistes contribuant à la conception de sites web aux contenus plus repérables. Il serait également souhaitable de soutenir un réseau de veille interdisciplinaire ayant pour objectif de contextualiser et d’analyser l’évolution de l’écosystème numérique.
Exemple: dans la foulée d’une étape importante de ses capacités d’interprétation (traitement automatique du langage), Google a mis à jour, cet été, ses directives d’évaluation de la qualité de l’information. Il va sans dire que c’est important.
Deuxième levier: modernisation des sites web
Dans le Web des moteurs de recherche intelligents, la reconnaissance des entités passe par l’indexation de pages web et l’analyse des contenus. Les sites web devraient donc être des sources d’information de première qualité, tant pour les internautes que pour les moteurs de recherche.
Est-il normal de ne pas trouver toute l’information, riche et détaillée, sur le site de référence d’une entreprise culturelle? Pour le bénéfice des projets numériques, il est vital de concevoir des contenus pertinents pour les machines, lesquelles évaluent à présent la qualité des sources d’information afin de générer la meilleure réponse à retourner à l’utilisateur.
Pour une productrice ou un artiste, il est beaucoup plus stratégique de faire de son site web une source primaire, en attribuant une page spécifique à la description de chaque œuvre, que de créer un article sur Wikipédia. Rappelons que Wikipédia n’est pas une source primaire pour les moteurs de recherche. De plus, l’usage du vocabulaire (Schema.org) ne leur fournit qu’un signal faible sur la nature d’une offre.
Un savoir commun, entre information et informatique
L’adaptation des contenus culturels à l’environnement numérique repose, avant tout, sur de meilleurs sites web. Ces espaces offrent les conditions optimales d’autonomie, repérabilité, accessibilité et interopérabilité. Leur modernisation requiert des acteurs clés, que sont les spécialistes du Web, une mise à niveau rapide de leurs connaissances et de leurs pratiques.
Finalement, afin d’opérer cette mise à niveau et de développer ces savoirs communs, il faut bien entendu insister sur l’interdisciplinarité entre les métiers du web et, notamment, le domaine des sciences de l’information.

Et si nous retombions en amour avec nos sites web?

Pourquoi l’évolution de nos sites web s’est-elle arrêtée au document numérique alors que chez des entreprises, comme Amazon ou Spotify, elle se concrétise par le déploiement de plateformes de données?
Les interactions que nous pouvions organiser sur nos domaines se sont atrophiées car nous avons laissé aux algorithmes le soin de faire des liens de proximité, de sens, de popularité ou autres. Ces liens qui favorisent la découverte et le rayonnement, nous ne les contrôlons pas.
Décloisonner les parcours de formation
Est-ce faute de ne pas avoir adapté, en les décloisonnant, des formations comme l’informatique, la communication et les sciences de l’information à la complexité de nouvelles pratiques? Dans le Web, les logiques technologiques, informationnelles et industrielles s’entrecroisent à présent pour former un nouveau champ de connaissances pour lequel il n’existe pas encore de savoir commun.
Entrer dans le domaine du langage
Ou, encore, est-ce faute de n’avoir pas réalisé que la donnée relève beaucoup plus du langage et de la pensée que du calcul et de la technologie?
Les concepts et particularités propres aux différents domaines de l’activité humaine ne sont pas aisément traduisibles dans la pensée mathématique des machines. L’information n’est plus uniquement un enjeu d’ingénierie, une chose à stocker, à transformer et à faire circuler. Dans le Web, elle relève du domaine du langage, décrivant des choses et des relations entre ces choses. Cette perspective, pourtant essentielle à l’ère de l’intelligence artificielle, est pratiquement absente des méthodes courantes de conception.
S’affranchir du document
Ou, tout simplement, est-ce parce que des solutions d’utilisation facile et très souvent gratuites nous ont été offertes? Avons-nous finalement laissé à d’autres les défis de l’évolution du Web et de nos architectures de connaissances? Cette évolution était pourtant prévisible dès 2009, la nouvelle méthode de conception de sites proposée cette anné-là par la BBC dans un billet de blogue en faisant foi.
Ne plus troquer l’acquisition d’expertise pour la facilité
Je crois bien que nous avons graduellement délégué à des entreprises, par algorithmes interposés, le choix des mots et des liens définissant qui nous sommes et la régulation des flux d’information dans un espace qui n’est pourtant qu’un sous-ensemble du Web. Nous avons renoncé au contrôle sur la découverte et la recommandation dont nous disposions grâce à nos blogues, nos répertoires et même, nos collections de fils RSS — j’utilise encore la mienne!
Alors que nous concevons encore un site web comme un ensemble de documents, les acteurs de la nouvelle économie prospèrent grâce à des sites web conçus comme des plateformes de données. Ces plateformes permettent d’aller beaucoup plus loin que la publication d’information. Par exemple:
- Trouver, réutiliser et partager des contenus par les utilisateurs et à l’interne;
- Définir les rôles, responsabilités et règles de gouvernance relatifs à chaque ensemble de données.
- Faciliter l’accès, de façon transversale, aux connaissances nécessaires pour la recherche de solutions et l’innovation.
- Et, surtout, relier les métadonnées descriptives des ressources aux données d’usage résultant de l’interaction des utilisateurs avec les contenus.
Réapprendre à faire du Web
Avant de tenter de mesurer le rayonnement de contenus culturels sur les plateformes, il faudrait se demander si nous en maîtrisons les conditions, sur nos sites web et au sein de nos écosystèmes numériques.
Nous avons choisi la gratuité et la facilité des plateformes qui sont la propriété d’entreprises sachant, mieux que nous, exploiter l’information tirée des interactions avec nos contenus. Le contexte actuel de la pandémie semble avoir accentué notre dépendance envers ces services qui entretiennent notre espoir de retrouver nos publics et nos clients.
Nos sites web nous offrent pourtant toujours la possibilité de développer et d’afficher nos écosystèmes de liens et de nommer les choses qui nous rassemblent. Afin de ne pas les laisser s’atrophier, nous devrions nous en servir pour mieux représenter nos domaines d’activité, nos contenus, ainsi que nos réseaux.
Définir numérique, données et «IA» est encore un défi

De quoi le numérique est-il le nom ?
Il y a eu «nouvelles technologies», «nouveaux médias» (suivi de l’abandon progressif de l’adjectif), «virtuel» (bien que l’environnement et les usages numériques soient bien réels), puis, «numérique» (en opposition à «analogique»). Mais de quoi ce concept flou à saveur culturelle et sociale est-il le nom ?
Voici un texte qui pourrait nous aider à discerner les caractéristiques qui sont spécifiquement numériques dans les modèles de production et de circulation des contenus.
Nous sommes obligés de prendre en compte le fait que l’on ne communique pas seulement sur le web: on organise sa journée, on achète des produits, on gère ses comptes en banque, on met en place des manifestations contre le gouvernement, on s’informe, on joue, on éprouve des émotions.
Voilà pourquoi le numérique n’est pas seulement une technique de reproduction qui s’oppose à l’analogique, mais il devient une véritable culture, avec des enjeux sociaux, politiques et éthiques fondamentaux et qu’il est urgent d’analyser et de prendre en compte.
Pour une définition du numérique, Marcello Vitali-Rosati.
Littératie de la donnée: de statistique à statactivisme
La littératie de la donnée est trop souvent restreinte aux capacités numériques, statistiques et techniques nécessaires à la lecture à à l’exploitation de jeux de données. Cette définition réduit notre capacité à questionner la fabrication des données (elles ne sont jamais neutres), les méthodologies et politiques auxquelles elles sont soumises, ainsi que les pratiques sociales que les bases de données reflètent.
Gaining a sense of the diversity of actors involved in the production of digital data (and their interests, which may not align with the providers of infrastructures that they use) is crucial when assessing not only the representational capacities of digital data but also its performative character and role in shaping collective life.
Jonathan Gray, Carolin Gerlitz, Liliana Bounegru, Data Infrastructure Literacy.
Intelligence artificielle: sphères technologique et cognitive
J’éviterai d’employer le terme galvaudé d’intelligence artificielle et m’en tiendrai, comme le premier des deux experts [Yann LeCun] à l’expression « science des données », l’intelligence reste une notion encore largement énigmatique aujourd’hui, comme le répète dans toutes ses conférences le second expert [Stéphane Mallat]. Pour apporter mon grain de sel au débat, je tenterai d’y appliquer une approche issue des sciences de l’information pour revenir à A. Desrosières en conclusion.
Jean-Michel Salaün, La science des données en quête du « su ».
Compétences spécifiques aux données: entre savoir et pratique
Or, nous sommes loin d’être tous égaux dans la manipulation des données : dans la compréhension de statistiques, dans la prise en main d’un fichier tableur un peu costaud, dans le bidouillage d’une base de données, dans la compréhension des enjeux… Les compétences requises mêlent à la fois un savoir geek (informatique), expert (statistique), critique (sciences humaines – travailler les corrélations), parfois juridique…
Amandine Brugière, Y a-t-il des compétences « Data » spécifiques?
Industrie culturelle et littératie numérique

Why 2012 will be year of the artist-entrepreneur
Le Web a démocratisé l’usage des technologies de l’information en offrant à tous l’accès aux outils de création et de diffusion numérique.
Sans aller aussi loin que Douglas Rushkoff, spécialiste de la cyberculture, qui affirme program or be programmed, je crois effectivement qu’une certaine maîtrise du Web fait désormais partie de notre apprentissage, comme savoir lire et compter. Cela ne veux pas dire connaître les arcanes des langages de programmation et des entrailles des machines.
J’entends plutôt acquérir des connaissances et adopter des comportements :
- connaître l’écosystème du Web (machine, application, serveur, Internet, site, base de données, hébergement, fournisseur d’accès Internet,…);
- connaître les usages (utiliser le Web de façon sécuritaire, prévenir les fraudes, différencier un blogue d’une page Facebook, …);
- comprendre les modèles d’affaires (logiciels ouverts, libres et propriétaires, license d’utilisation, systèmes ouverts et fermés, …).
… qui permettent de développer un esprit ouvert et critique :
- Qu’est ce qu’on m’offre comme valeur (accès, usage, diffusion, …) ?
- Qu’est-ce que j’offre en échange (argent, données personnelles, production de code ou de contenu) ?
- Quelle est la valeur créée pour ma collectivité, la société, la planète ?
Une littératie à développer, non seulement dans l’intérêt de tous les entrepreneurs du domaine culturel (artistes, producteurs, diffuseurs, agents), mais dans celui de l’ensemble des citoyens