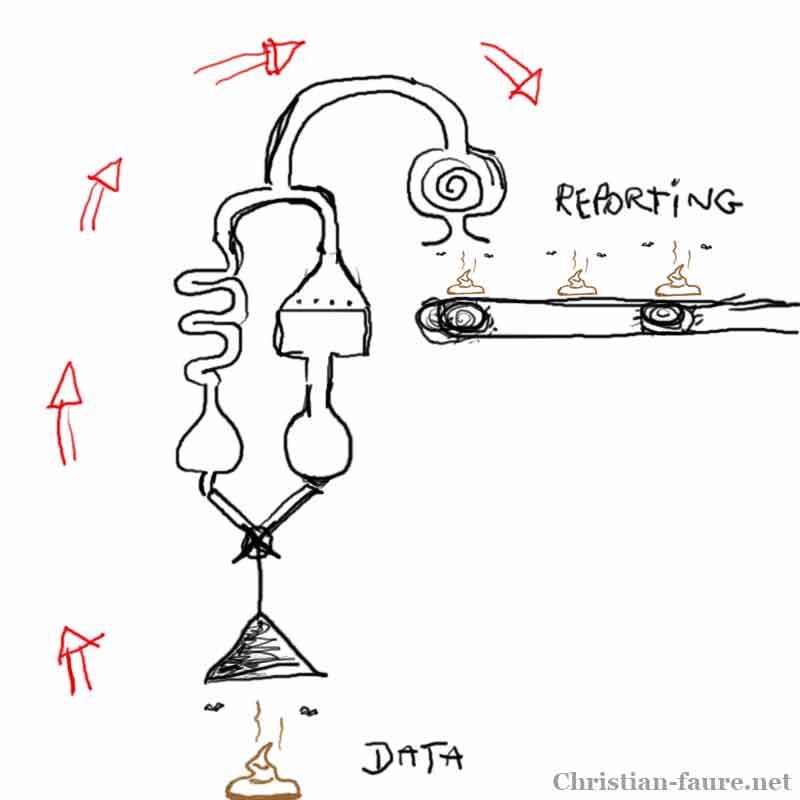
Dans la foulée des programmes de financement en culture, rares sont les propositions qui ne s’appuient pas sur la production ou l’exploitation de données. Nous devrions nous réjouir de la multiplication de telles initiatives car elles témoignent de la transformation progressive des modèles de pensée et des usages.
Cependant, deux constats témoignent d’une méconnaissance des conditions techniques et méthodologiques de cette transformation : de nouveaux concepts ne sont pas maîtrisés et la persistance de vieux modèles de gestion bloque la transformation des organisations.
Voici des types de propositions, autour des données qui, sous certaines conditions, sont les plus susceptibles de favoriser la transition numérique des acteurs et des organismes culturels.
Schema.org: se représenter sous forme de métadonnées
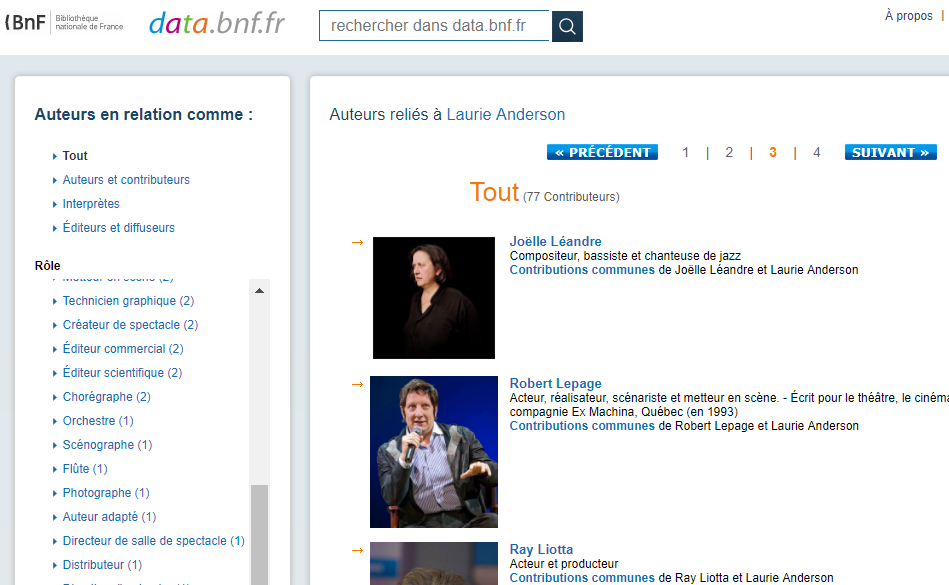
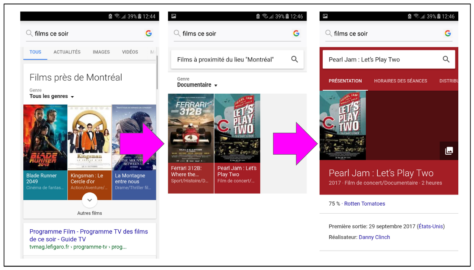
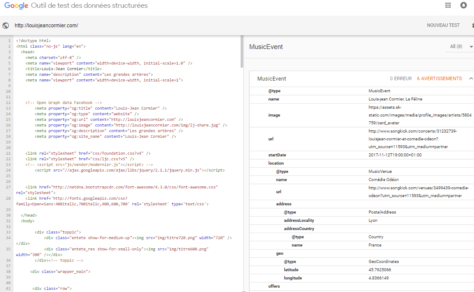
Voici un exemple d’usage de ce que Google appelle « données structurées« . Il s’agit, en fait, des métadonnées utilisées pour décrire des offres afin qu’elles soient interprétées par des systèmes automatisés. Le site de Patrick Watson, musicien montréalais, contient les métadonnées décrivant les lieux , dates et salles où il se produit en concert. Google proposera ses représentations lors de recherches sur l’artiste ou d’une simple question posée au moteur de recherche. Cette semaine, les utilisateurs géolocalisés près de certaines villes européennes se feront proposer des spectacles de M. Watson. Les offres apparaîtront en décembre pour les utilisateurs du Québec et de l’Ontario.
Cette technique qui vise à améliorer la découvrabilité des offres est, à présent, incontournable. Rater le test des données structurées , pour un événement ou un produit culturel, c’est dépendre uniquement d’activités de promotion pour être proposé à un public. Et c’est également ne pas rentabiliser un investissement dans un site Internet. Cependant, si celui-ci n’est plus une destination principale pour les internautes, il est un point de référence essentiel pour la validation de l’identité numérique.
Impact: culture de la donnée et identité numérique
Apprendre à indexer une offre (la représenter à l’aide de métadonnées) permet à chacun de développer sa littératie numérique ainsi qu’une culture de la donnée. Une bonne initiative viserait à former et à équiper les acteurs culturels afin qu’ils définissent eux-mêmes les données qui les concernent et qu’ils intègrent cette pratique à leurs processus et stratégies. Confier à d’autres le soin de décider de la façon de se représenter n’est ni formateur et ni stratégique.
Une description d’offres personnalisée et éloquente requiert cependant une bonne connaissance des principes d’indexation et de la structure logique du modèle Schema.org. Ce sont des compétences que des bibliothécaires et spécialistes de la documentation pourraient aider à développer auprès des acteurs du milieu culturel et artistique et des agences web.
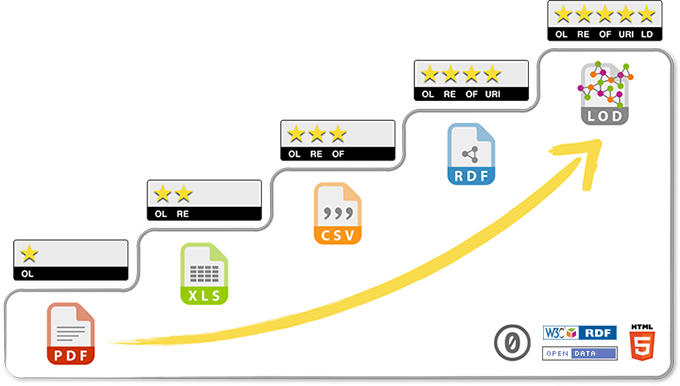
Données ouvertes: développer une vision sur les données et leurs usages
Les données ouvertes ne constituent pas une technologie mais un moyen de mise à disposition de données selon des licences d’utilisation spécifiques. Libérer des données est, en soi, un projet auquel on doit accorder les ressources et le temps nécessaires pour produire un jeu de données répondant à des besoins. Les fichiers de données ouvertes peuvent être décrits à l’aide de métadonnées Schema. Ceci ne rend cependant pas les données qui y sont contenues, accessibles et interprétables par des moteurs de recherche.
Impact: interdisciplinarité et orientation utilisateurs
La libération de données facilite la réutilisation des données de collections, catalogues ou fonds documentaires dans le cadre de la stratégie de visibilité et diffusion d’un organisme culturel. C’est un projet qui peut transformer des pratiques et des processus de façon durable, à la condition d’adopter une nouvelle méthode de travail collaboratif et de gouvernance de données. NordOuvert, un organisme a conçu une trousse d’outils maison pour données ouvertes pour le gouvernement canadien.
Données ouvertes et liées : capitaliser sur des actifs numériques
Un musée pourrait décrire ses événements pour des moteurs de recherche, avec des métadonnées Schema.org. Mais serait-il pertinent de documenter ainsi tous les éléments d’une collection ? Cette question peut faire débat pour diverses raisons. Le modèle descriptif des moteurs de recherche répond à leurs propres objectifs stratégiques. Le risque encouru est l’effacement de la diversité des perspectives au profit d’un modèle uniforme et d’une certaine vision du monde. Il est également souhaitable, pour un état, de minimiser sa dépendance à l’un des plus puissants acteurs du numérique pour l’organisation des données de la culture et du patrimoine. C’est pour ces raisons que plusieurs initiatives de données ouvertes et liées ont émergé depuis plusieurs années, à travers le monde.
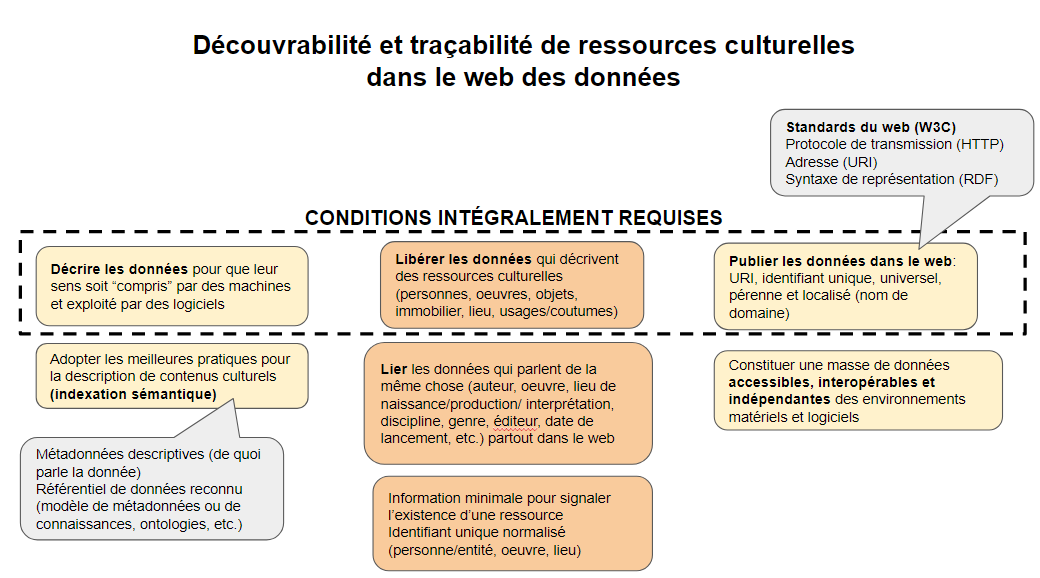
Le terme « données ouvertes et liées » désigne des données qui sont ouvertes et qui peuvent être interprétées et liées entre elles par des humains et des machines si elles sont exprimées et publiées selon les standards du web. Faire un projet de données liées est très exigeant, en ressources, en expertises et, surtout, en temps. Ce sont des activités qui peuvent se dérouler sur plusieurs années afin de s’assurer de la cohérence des modèles de données et des liens.
Impact: responsabilisation et pouvoir d’agir sur les données
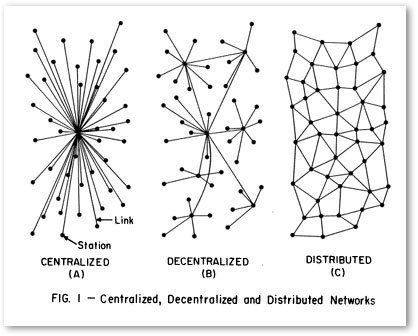
Malgré sa complexité, une véritable initiative de données ouvertes et liées peut amener une organisation à passer d’une gestion de projet centralisée à une véritable démarche collaborative, à l’interne et avec des partenaires. La transition numérique repose sur une profonde transformation des modes de gestion de l’information. Une solution issue d’un travail collaboratif a plus de chances de produire des résultats satisfaisants et durables pour tous qu’un projet classique. La production de données devient alors une responsabilité distribuée au sein d’une organisation et, par extension, au sein de son écosystème.
On ne saurait parler de production de données sans mentionner le nombre croissant d’initiatives s’appuyant sur l’infrastructure de Wikidata pour exposer des données ouvertes et liées. Art Institute of Chicago est une des institutions ayant récemment ajouté les données de ses collections et plus de 52 000 images d’oeuvres en licence Creative Commons 0 (domaine public). Cette institution, comme tant d’autres, sort du périmètre habituel de sa stratégie de développement de publics pour expérimenter d’autres formes de circulation de l’information.
Transition: de projets à initiatives
Une initiative de données structurées, ouvertes ou liées constitue une opportunité pour une véritable transition numérique. Comme l’affirme un chercheur du MIT Media Lab dans un billet sur la nécessité de développer une littératie de la donnée: «You don’t need a data scientist, you need a data culture » :
- Leadership: priorise et investit dans la collecte, la gestion et l’analyse de données / la production de connaissances.
- Leadership: priorise une littératie de la donnée créative pour l’ensemble de l’entreprise, et pas seulement pour les technologies de l’information et la statistique.
- Membres du personnel: encouragés et aidés à accéder aux données de l’organisation, à les combiner et à en tirer des conclusions.
- Membres du personnel: savent reconnaître les données. Ils proposent des façons créatives pour utiliser les données de l’organisation afin de résoudre des problèmes, prendre des décisions et élaborer des narratifs. (traduction libre)
Ce ne sont donc ni une mise à niveau technologique, ni l’acquisition de nouveaux usages qui opéreront cette transformation. C’est plutôt l’adoption de nouveaux modes de gestion de l’information: la décentralisation des prises de décision, l’abolition des silos organisationnels et la mise en commun de données. Pour demeurer pertinents dans un contexte numérique, nous ne pouvons faire autrement que d’expérimenter des méthodes collaboratives. Nous pouvons réussir à plusieurs ce qu’il est trop périlleux d’entreprendre individuellement. Soutenir des initiatives de données sans s’engager dans cette voie limiterait considérablement l’impact des investissements en culture.