De façon générale, les initiatives visant à promouvoir une offre culturelle afin de favoriser sa « découvrabilité » concernent les moteurs de recherche comme Google ou des plateformes en ligne, existantes ou à concevoir. Ce sont cependant deux types de projets différents pour lesquels le type d’information à produire détermine des activités, compétences et ressources nécessaires différentes.
Continuer la lecture de Découvrabilité: les données et métadonnées sont-elles toujours utiles?Archives par mot-clé : plateforme

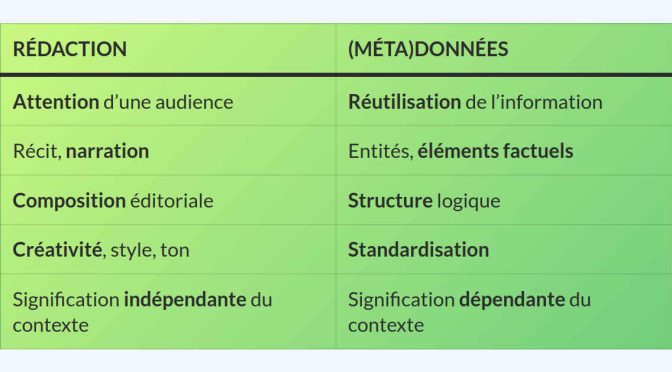
Les données ne sont pas la panacée de la découvrabilité

Orienter toute initiative de découvrabilité vers la production de données relève de la pensée magique selon laquelle la technologie est la solution à toute problématique, aussi systémique et complexe soit-elle.
Continuer la lecture de Les données ne sont pas la panacée de la découvrabilité
Découvrabilité: sens commun et connaissances partagées
Les formations, référentiels, trousses à outils, programmes de financement et experts en découvrabilité abondent. Tous peuvent se saisir des termes et notions qui circulent sans avoir une compréhension approfondie du Web. C’est, à mon avis, préoccupant car il n’existe pas de traité sur ce qu’il faut faire, dans le numérique, pour qu’une information soit vue. À la différence du génie ou de la médecine, par exemple, il n’y a pas de socle commun de connaissances pour les divers métiers du Web. Un projet numérique est souvent une tour de Babel de concepts. Que des non-spécialistes du numérique, comme des directions d’entreprises, soit dépassés n’est pas étonnant.
Continuer la lecture de Découvrabilité: sens commun et connaissances partagées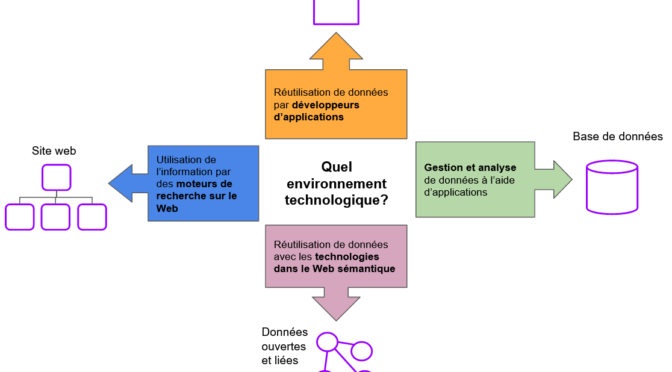
Découvrabilité: oui, mais dans quel environnement technologique?
Favoriser la découverte d’une offre pour atteindre un objectif c’est bien, mais dans quel environnement technologique? La réponse à cette question, rarement abordée, pourrait pourtant aiguiller certains projets ciblant les moteurs de recherche vers de meilleures pratiques de conception et de rédaction pour le Web plutôt que vers la création de métadonnées.
Continuer la lecture de Découvrabilité: oui, mais dans quel environnement technologique?
Découvrabilité: comment aiguiller des initiatives numériques vers la bonne voie

Il est temps d’apporter un peu de clarté dans le méli-mélo de concepts qui ne sont pas très bien maîtrisés. Voici une petite mise au point qui pourrait être bénéfique pour les promoteurs d’initiatives numériques, ainsi que les organisations qui les financent.
Continuer la lecture de Découvrabilité: comment aiguiller des initiatives numériques vers la bonne voie
Découvrabilité: des métadonnées, oui, mais dans quel but?

Retour sur des notes prises en lisant des propositions de projets numériques.
À la recherche de la stratégie perdue
L’absence de réflexion stratégique est le talon d’Achille de la plupart des propositions de projets et de plans de découvrabilité. Pourtant, qu’il s’agisse de baliser des types de contenu à l’intention des moteurs de recherche ou de décrire des ressources dans un catalogue en ligne, la production de métadonnées utiles s’appuie sur la connaissance des publics cibles et des résultats recherchés.
La meilleure façon d’évaluer le résultat des efforts déployés pour qu’une offre ou un contenu rejoigne ses publics est de fixer des objectifs mesurables et réalistes. Et pour cela, il faut avoir élaboré une stratégie basée sur la connaissance du marché, des opportunités et des contraintes propres à l’organisation.
Les connexions entre votre offre et ses publics cibles
Les algorithmes des plateformes évoluent vers une personnalisation accrue des réponses qu’elles proposent en s’appuyant sur les profils de leurs utilisateurs. Nos sites web devraient faire de même en fournissant des éléments d’information qui « parlent » aux publics cibles et qui, conséquemment, facilitent le travail des moteurs de recherche.
Petit rappel: nous découvrons de l’information sur l’interface d’un moteur de recherche, mais c’est celui-ci qui la trouve. Et cela, en fonction d’un traitement algorithmique fondé sur :
- la popularité (ou l’autorité) des contenus;
- leur similarité avec le profil et l’historique de navigation de l’utilisateur.
Avant de tout miser sur des métadonnées
Voici quelques éléments clés sur lesquels réfléchir avant de déterminer les activités à réaliser dans le cadre d’un plan de découvrabilité:
- Peu importe les activités évoquées par le terme, la découvrabilité n’est mesurable qu’à l’aide des objectifs déterminés par la stratégie. Pas de stratégie: pas d’objectifs donc pas d’évaluation des résultats. Et cela s’applique autant à une stratégie de promotion qu’à des initiatives de mutualisation de données et de modélisation de connaissances pour le web sémantique.
- Les moteurs de recherche ne sont que l’un des vecteurs de la découverte. Celle-ci n’advient pas que par l’entremise de machines car la recommandation est encore largement sociale — réseaux sociaux, réseaux professionnels et académiques, bibliothécaires, libraires, médias et publications spécialisées. Les métadonnées ne sont que l’un des moyens à mettre en œuvre, au même titre qu’une page Facebook ou une chaîne YouTube, au service d’une stratégie.
- Se contenter d’intégrer des balises ne permet pas aux moteurs de recherche de fournir aux utilisateurs les réponses correspondant le plus à leurs profils ni de différencier une offre au sein d’une même catégorie, comme des événements, par exemple.
- Les deux cotés d’une même page :
- Métadonnées dans le code HTML: les modèles Schema.org permettent aux moteurs de recherche de catégoriser des types de contenu.
- Données dans le contenu d’une page web: certains éléments d’information repérables, tels que des entités nommées et des mots clés, facilitent la contextualisation et la personnalisation des résultats de recherche.
- Il faut se tenir bien informé de l’évolution du moteur de recherche et de ses consignes d’utilisation avant d’indexer des offres avec Schema.org. Les objectifs de Google varient dans le temps, selon les types de contenu et selon les ententes qu’il conclut avec certaines grandes sources de données, comme par exemple, des plateformes musicales.
- Un site web qui fournit de l’information structurée pour des machines et qui contribue à un écosystème de liens utiles pour des humains est un excellent investissement stratégique.
- Tous les acteurs de l’écosystème numérique d’une offre culturelle contribuent au rayonnement de celle-ci par l’information offerte sur leurs sites web . Ceux-ci participent également au déploiement d’un réseau d’hyperliens fournissant des données contextuelles aux moteurs de recherche et des parcours de découverte aux humains.
- Un bon plan de découvrabilité résulte d’une connaissance des publics cibles et de l’utilisation réfléchie et coordonnée de différents outils: référencement, modèles Schema.org, contributions à Wikipédia et Wikidata, publications sur des réseaux sociaux, campagnes de promotion et publicité.
Il n’existe pas de recette gagnante: une stratégie de visibilité et de rayonnement est spécifique à chaque projet. Le succès d’un plan découvrabilité dépend de choix qui sont alignés sur cette stratégie afin de publier la bonne information, dans le bon format, au bon endroit et pour le bon public.