Données structurées et données ouvertes et liées sont des expressions dont l’usage indifférencié peut nuire à la prise de décisions qui ont une grande importance pour la réussite d’un projet dans le domaine culturel. Par données structurées , on fait ici référence à la technique d’indexation préconisée par Google (structured data). Ces expressions désignent deux manières différentes de travailler dans le web des données. Ce billet concerne les modèles de données et outils proposés afin de documenter des ressources pour les moteurs de recherche.
Un autre billet abordera les avantages spécifiques des données ouvertes et liées.

Google et le web sémantique
En 2013, Google effectue un des plus importants changements sur son algorithme de recherche en plus d’une décennie.
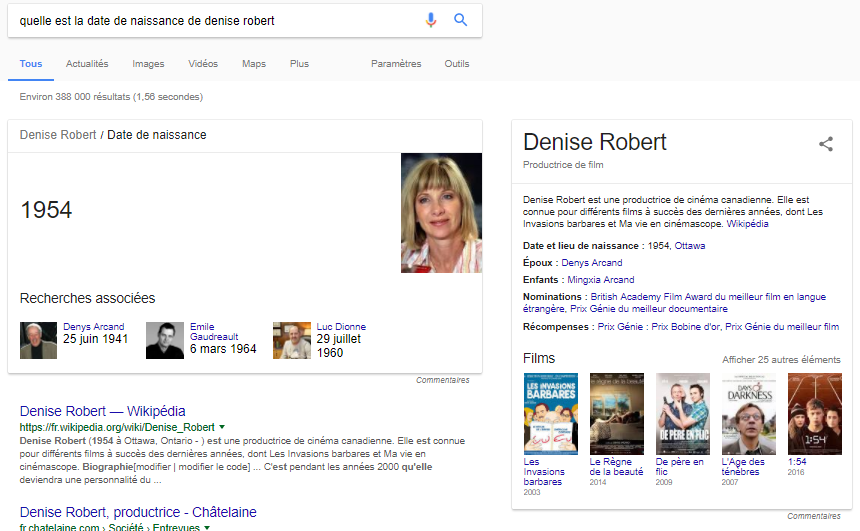
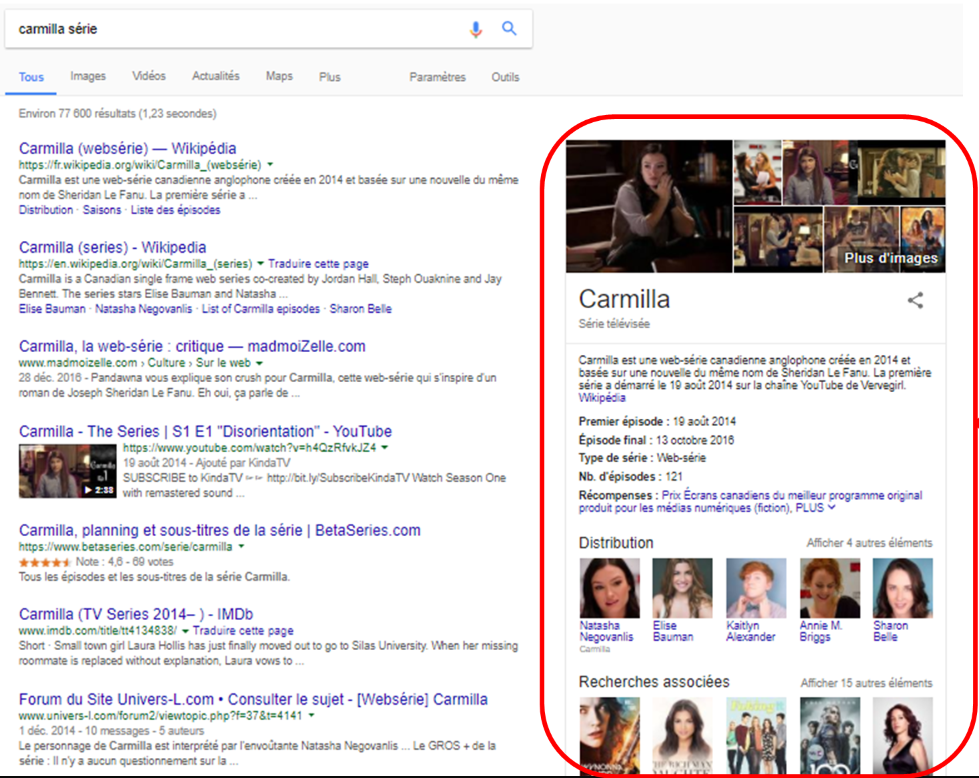
Baptisée Hummingbird , la nouvelle mouture s’appuie sur le sens et le contexte plutôt que sur la pondération de mots clés. Elle fait également appel à un savoir encyclopédique qui est organisé comme un graphe de connaissances et qui est constitué en grande partie à partir de Freebase, une base de données structurées collaborative, acquise par Google. Cette masse de données, appelée Knowledge Graph, permet de à l’algorithme de classer l’information et, de ce fait, de savoir à quelles autres informations elle est liée. C’est une logique similaire à celle de Wikipédia, où chaque article comporte plusieurs liens internes et externes.
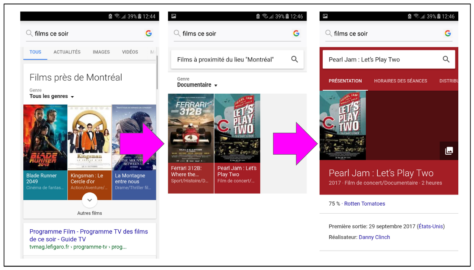
La nouvelle version de l’algorithme peut donc effectuer des recherches en mode « conversationnel » (Où faire réparer mon téléphone?) et, surtout, améliorer les résultats de recherche grâce aux concepts du web sémantique: des métadonnées qui donnent le sens des données et qui permettent de faire des liens qui produisent de l’information. En comprenant le sens et le contexte de la demande, il devient possible, pour le moteur de recherche, de mieux interpréter l’intention de l’individu qui la transmet.
De la liste de pages web aux résultats enrichis
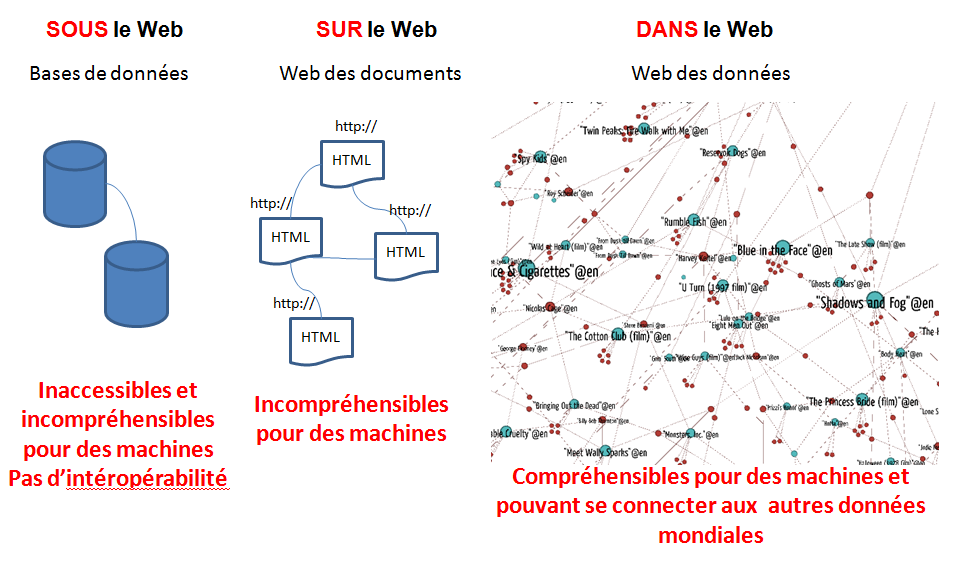
Depuis, la recherche de (méta)données qui font du sens prend progressivement le pas sur la recherche de mots clés. C’est une transition que l’on peut très facilement constater sur nos écrans mobiles. Nous passons donc d’une liste de pages qui comportent les mots clés recherchés à une agrégation d’informations qui résulte de liens entre des données structurées.
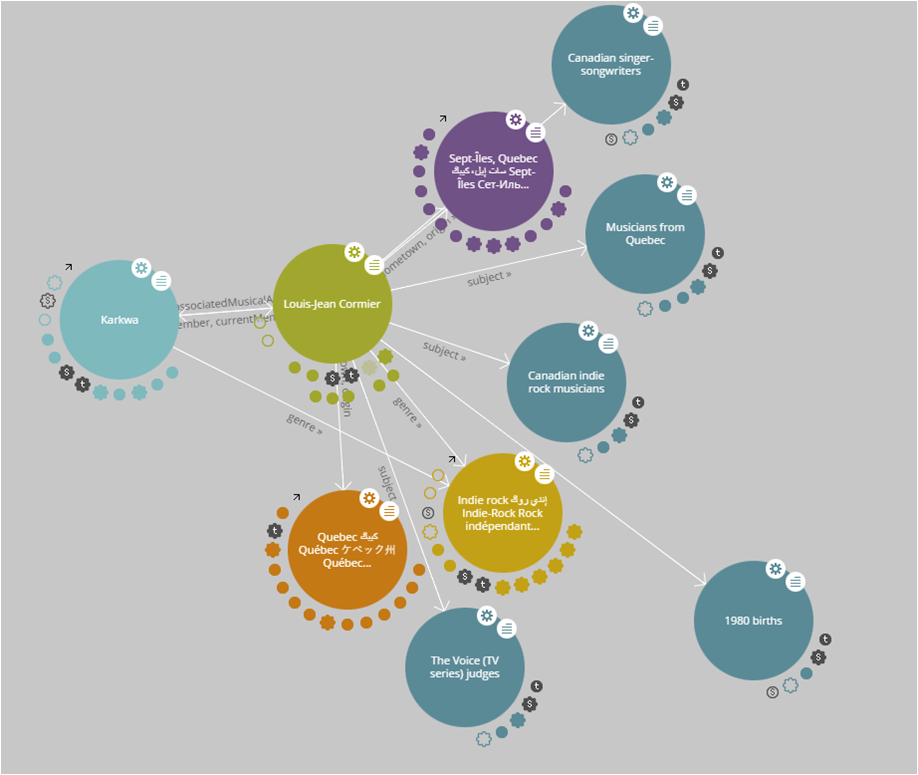
Il y a toujours une recherche de pages, mais ce sont les données qui décrivent des « ressources » (personnes, choses, concepts) qui sont désormais importantes. Au web documentaire, celui où l’information est présentée métaphoriquement en pages, s’ajoute le web des données, celui où toute connaissance est de la donnée qui peut être collectée et traitée par des machines. Celles des moteurs de recherche et celles de toute entité qui souhaite s’en servir pour développer un service ou un produit qui aurait de la valeur.
Schema: représentation pour moteurs de recherche
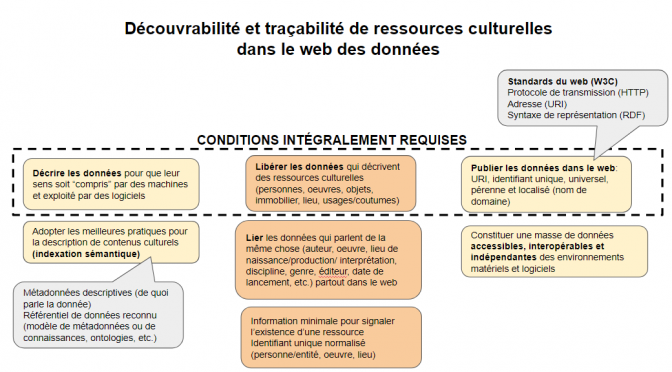
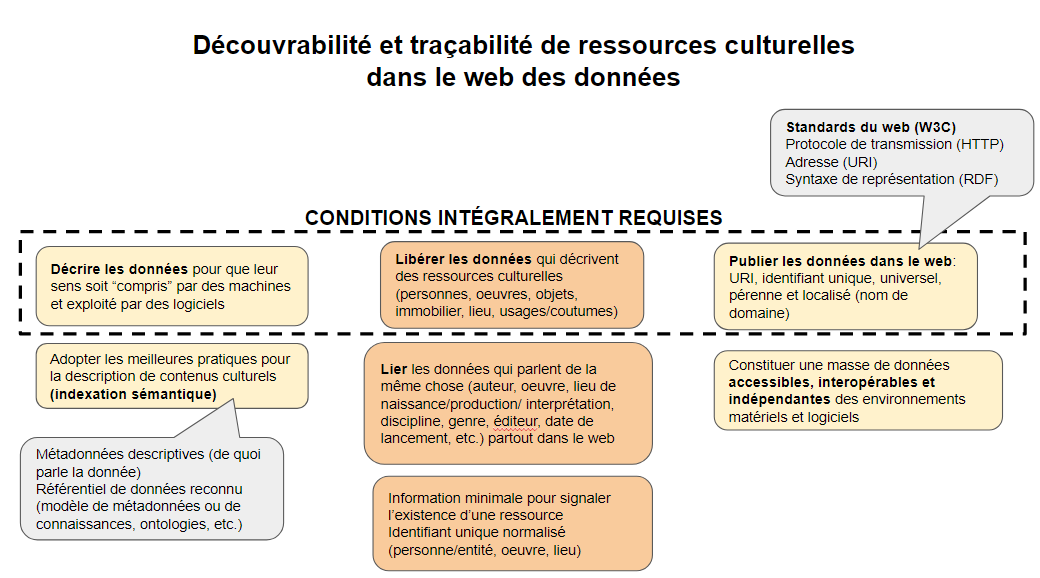
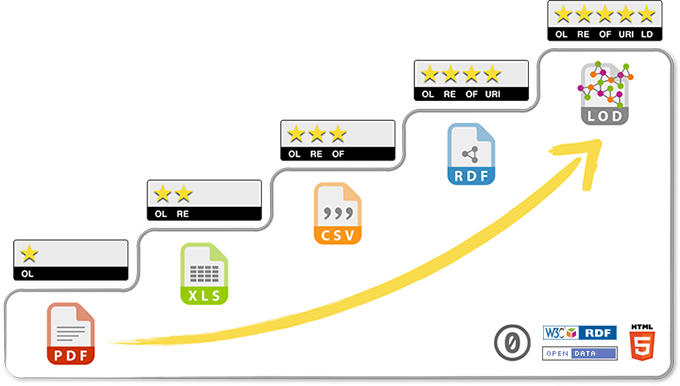
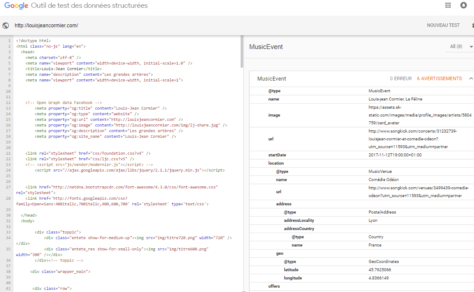
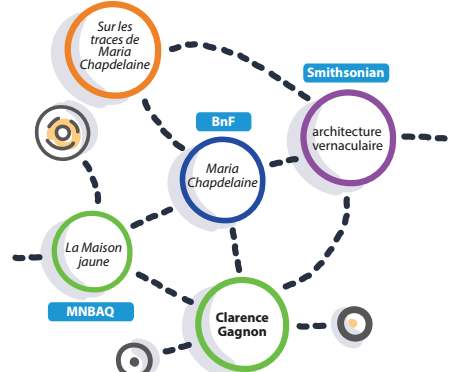
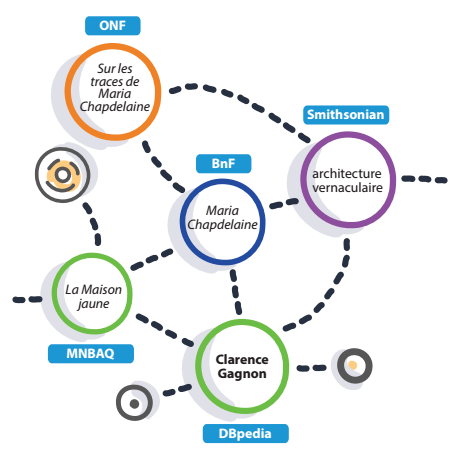
Les données structurées sont exprimées selon un modèle de métadonnées qui a été conçu par un regroupement de moteurs de recherche (Google, Bing, Yahoo! et le russe, Yandex). Ces données sont publiées dans le code HTML des pages où sont présentées les ressources qu’elles décrivent. Ces données sont publiques, mais pas ouvertes. Mais ce sont cependant des données liées puisque le modèle Schema permet de produire des triplets (symphonie pour un homme seul (sujet) – est de type (prédicat)- électroacoustique (objet)). Quelques exemples sont présentés dans un billet précédent l’usage de données structurées par Google. Le rôle des données structurées et des liens vers Wikipédia est expliqué plus en détail dans un guide sur la documentation des contenus produit pour le Fonds indépendant de production, avec la collaboration de TV5.ca et l’appui de la SODEC.
Apprendre à documenter: une étape nécessaire
Alors, documenter une ressource à l’aide de données structurées, en intégrant celles-ci dans la page web de la ressource, est-ce « travailler pour Google » ?
Oui, bien sûr. Mais, ce n’est qu’un premier pas dans l’apprentissage pratique du rôle clé des données dans une économie numérique. Mais s’en tenir à cette étape, c’est conformer notre représentation de la culture à un modèle de représentation et à des impératifs d’affaires qui sont hors de notre contrôle et qui ne répondent à des impératifs économiques qui avantagent la plateforme.
Ne pas dépendre d’entreprises qui se placent au-dessus des lois et des États est un des enjeux qui motivent des gouvernements et des institutions à soutenir, par des politiques et des programmes de financement, des projets basés sur les principes et les technologies du web sémantique qu’ils peuvent contrôler. Nous verrons, dans un prochain billet, les opportunités qu’offrent ces technologies pour l’innovation et la promotion de la culture.