Quelle est la probabilité que des données ouvertes et liées fassent découvrir une chose qu’on ne connaît ou ne cherche pas? Le potentiel de découvrabilité d’une offre culturelle sous forme de données avec les technologies du Web sémantique est très faible. Pourtant, l’Appel de projets pour le développement culturel numérique dans la francophonie canadienne privilégie la « production et la diffusion la plus large possible de métadonnées (idéalement sous forme de données ouvertes et liées) ». Les arguments qui soutiennent cette orientation gagneraient à être partagés et discutés au sein de comités scientifiques et techniques.
Continuer la lecture de Quel est le potentiel de découvrabilité des données ouvertes et liées?Tous les articles par Josée Plamondon

Redéfinir la découvrabilité pour une pensée stratégique
Potentiel pour un contenu, disponible en ligne, d’être aisément découvert par des internautes dans le cyberespace, notamment par ceux qui ne cherchaient pas précisément le contenu en question.
C’est une vision qui rend attrayante une solution aussi improbable que des métadonnées pour influencer Google. Mais surtout, une telle démarche élude l’étape la plus importante d’un projet qu’est la réflexion stratégique.
Comprendre une problématique multidimensionnelle
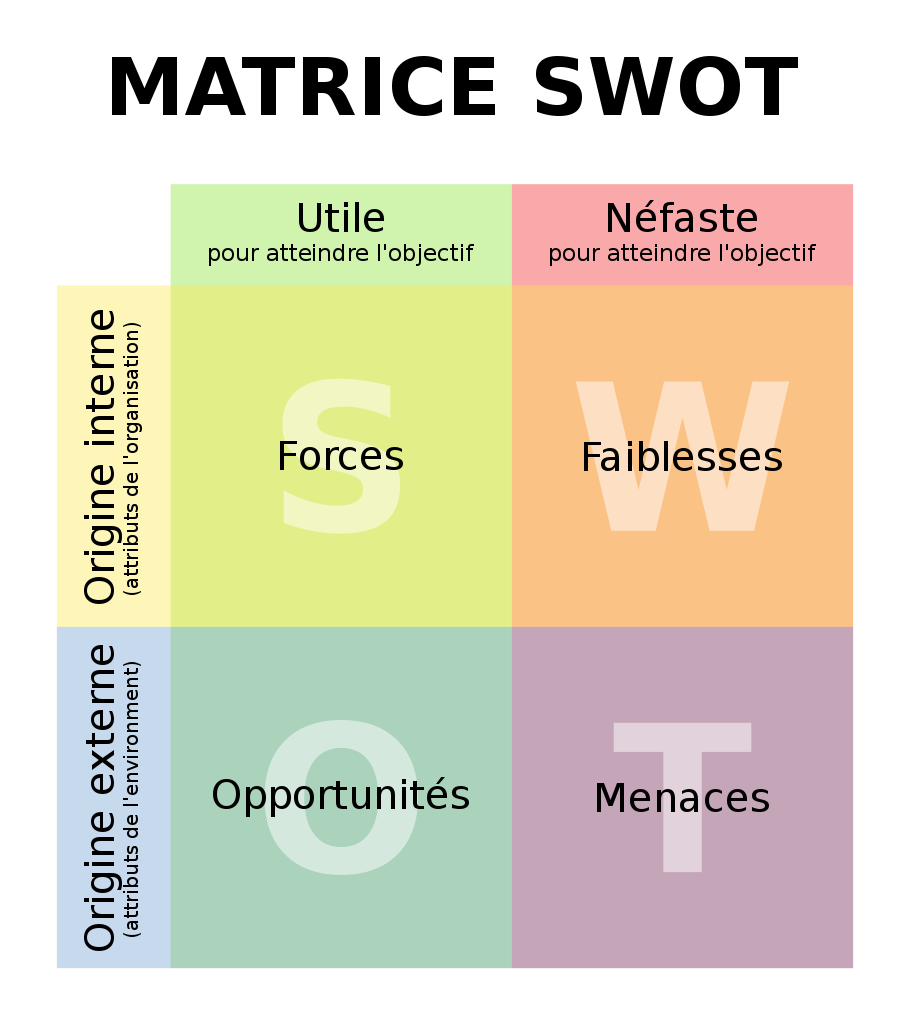
Une analyse stratégique permet pourtant d’identifier les facteurs internes (forces, faiblesses) et externes (opportunités, menaces) qui peuvent faciliter ou entraver la réalisation des objectifs souhaités. En voici des exemples:
Force (facteur interne): la connaissance de l’environnement technologique préconisé est suffisamment maîtrisée par la direction pour communiquer clairement sur les résultats tangibles attendus (ce que ça peut faire) et dissiper le fantasme du techno solutionnisme (ce que ça ne fait pas).
Menace (facteur externe): des pratiques industrielles et modèles d’affaires rendent des contenus indisponibles ou introuvables, comme l’affirme Philippe Falardeau dans cet article sur la possible fermeture d’un distributeur de films.
Rechercher des résultats concrets
Voici une définition plus précise de la découvrabilité et qui m’apparaît encourager une démarche stratégique:
La découvrabilité est le résultat potentiel de stratégies et moyens mis en œuvre, dans un environnement technologique donné, afin de favoriser des liens entre les intérêts de publics cibles et une offre qu’ils ne connaissent pas ou ne cherchent pas.
Elle comprend les éléments clés d’un questionnement préalable à la recherche d’une solution:
- Le but: problème ou besoin concret (achat, visite, développement de compétences)?
- Les publics cibles: quels sont-ils et quels sont leurs profils d’intérêts?
- L’environnement technologique choisi: quelles sont les particularités de l’espace numérique choisi pour favoriser la découverte? Quelles sont les expertises requises?
***
Il serait essentiel de redéfinir la découvrabilité afin que chaque initiative numérique du domaine des arts et de la culture entreprenne une analyse stratégique. C’est en réalisant une telle démarche, en amont de la recherche d’une solution, que les organisations peuvent développer leur capacité d’adaptation et d’innovation.
Wikidata: pour Google ou pour le Web des données?
Wikidata améliore-t-il la découvrabilité sur Google? Non.
Contrairement à une hypothèse que j’ai parfois évoquée il y a plusieurs années, puis maintes fois remise en cause, Wikidata n’est pas une solution de découvrabilité sur Google. C’est l’une des bases de connaissances permettant de valider une entité, et non de fournir une réponse. Ce n’est pas un moyen de promouvoir une information pour quiconque interroge Google, et encore moins pour qui ne la cherche pas.
Verser des données dans Wikidata ne rend donc pas un objet culturel plus visible ou découvrable parmi les résultats du moteur de recherche. Cependant, c’est une initiative à fort potentiel de créativité et de transformation numérique si l’on poursuit un tout autre but que la promotion d’une offre, soit la réutilisation de données interopérables et interconnectables, partout sur la planète.
Wikidata pour le Web des données
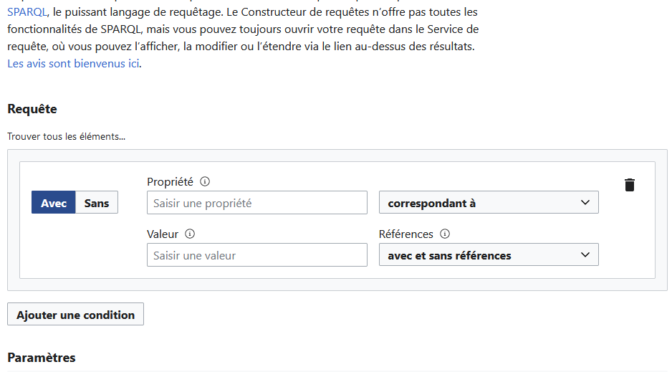
Par contre, comme je l’ai précisé dans un billet sur le choix d’un environnement technologique, contribuer à Wikidata peut favoriser la découverte de données sur cette plateforme. La maîtrise du langage d’interrogation SPARQL est cependant une courbe d’apprentissage plutôt abrupte pour les non-spécialistes. Même l’assistant de recherche est inaccessible pour qui n’a pas l’habitude de composer des requêtes destinées à des bases de données.
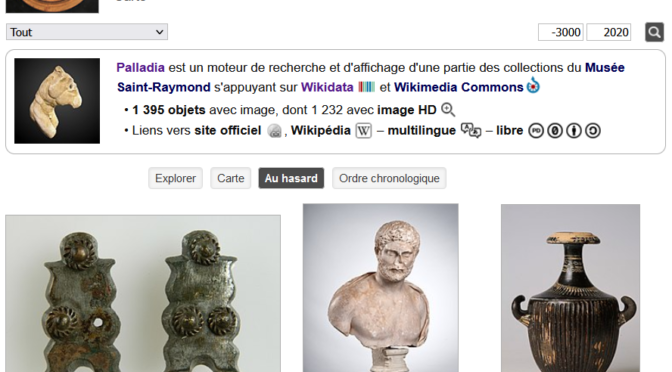
Les organisations versant leurs données dans Wikidata devraient offrir, sur leurs propres sites, des interfaces de recherche avec des requêtes pré-construites. L’exemple présenté ci-dessous est un projet réalisé par le Musée de Saint-Raymond à Toulouse (France) en partenariat avec Wikimedia France.
Pour s’en inspirer davantage, voici l’historique des projets Crotos et Palladia sur WikiArchives, avec un lien complémentaire vers un billet de Marie D. Martel datant de 2017 mais qui demeure tout à fait pertinent: #wikimania Le modèle d’une pratique professionnelle alternative à bâtir avec les GLAMs.
Cette réutilisation des données dans les deux sens — dans l’environnement ouvert et collaboratif de Wikidata et dans la perspective spécifique d’une institution — présente de précieux avantages:
Impulsion d’une véritable transformation
Un projet de données ouvertes et liées peut contribuer à la transformation d’une organisation dans un contexte numérique. Il ne s’agit pas d’informatisation, mais d’un projet fédérateur qui peut transformer les rapports à l’information et à la communication. Si c’est un choc culturel pour certaines institutions, c’est potentiellement un environnement d’apprentissage et, au final, une véritable transformation numérique pour toute forme d’organisation.
Modernisation d’un système de gestion documentaire
Des données liées offrent un énorme potentiel de découverte et de connaissance car elles ne sont pas figées dans un modèle où les relations sont prédéfinies. Ceci accorde à une base de données en graphe (appelée aussi graphe de données liées) la capacité d’effectuer du raisonnement, ce que la technologie des bases de données classiques n’offre pas.
Contournement des défis du Web sémantique
Wikidata réduit considérablement les coûts, délais et expertises requises pour la réalisation d’un projet de données ouvertes et liées en fournissant, entre autres, la plateforme et l’ontologie. Bien plus complexe qu’un vocabulaire, une ontologie est la spécification d’une conceptualisation, à l’aide de types d’objets, de leurs propriétés et de leurs différents types de relations. C’est un exercice d’abstraction réalisé par un petit nombre de spécialistes
Interopérabilité accrue des données
L’ontologie qui permet de modéliser les données pour Wikidata n’est pas conçue pour représenter le concepts propres à chaque domaine de connaissance. C’est un avantage: alors qu’une base de données classique est conçue pour répondre aux besoins et usages d’un domaine ou discipline, Wikidata ne cloisonne pas la connaissance et favorise, de ce fait, les interconnexions.
Petit rappel
Une base de données classique et un graphe de données liées ne sont pas exploitables pour les moteurs de recherche comme Google.
Deux grands défis d’un projet de données
Un projet de données liées comporte des défis qui doivent impérativement être identifiés et analysés en amont de toute conception ou acquisition de technologie. Voici deux de ces défis:
Expérience de recherche
Des données liées doivent permettre d’offrir des fonctions de recherche différentes de (et supérieures à) celles d’une base de données classique.
Une recherche par auteur, titre et sujet n’apportera pas de nouvelles connaissances. Les critères d’une recherche avancée ne sont pas de bons moyens pour faire découvrir une collection à qui ne cherche rien en particulier.
Mobilisation des utilisateurs(trices)
Changer le comportement de personnes qui accèdent à de l’information en posant simplement une question (Google, ChatGPT) ou de façon passive (flux des réseaux sociaux) est très certainement l’un des plus grands défis des nouvelles base de données en ligne.
Comment faire d’un site une destination préférée pour chercher ou découvrir de l’information? Hélas, nombreux sont les projets qui ne reposent que sur une campagne de promotion pour modifier des habitudes devenues des réflexes.
Wikidata: oui, mais pour des résultats concrets
Le versement de données dans Wikidata ne devrait pas être promu comme une bonne pratique de référencement web et de découvrabilité sur Google.
Cependant, un projet avec Wikidata peut faire converger deux buts: développer une culture de la donnée et amorcer une véritable transformation numérique impliquant de nouveaux modes d’organisation et de collaboration.
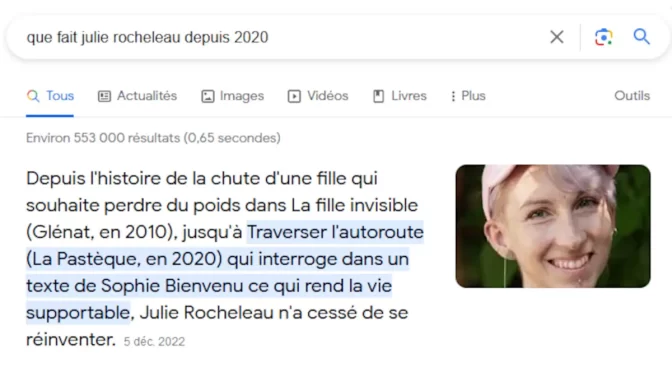
Comment améliorer la découvrabilité sur Google?
Pour améliorer la découvrabilité sur Google, mieux vaut utiliser les données là où elles sont vraiment utiles et comprendre les différents types de résultats présentés par le moteur de recherche. En effet, de nouvelles fonctionnalités transforment peu à peu la liste de liens classiques en une interface qui fournit des réponses et des suggestions pour amener les internautes à préciser leurs intentions.
Continuer la lecture de Comment améliorer la découvrabilité sur Google?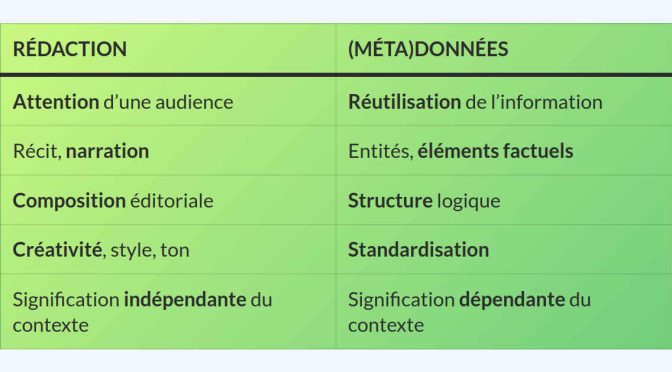
Découvrabilité: les données et métadonnées sont-elles toujours utiles?
De façon générale, les initiatives visant à promouvoir une offre culturelle afin de favoriser sa « découvrabilité » concernent les moteurs de recherche comme Google ou des plateformes en ligne, existantes ou à concevoir. Ce sont cependant deux types de projets différents pour lesquels le type d’information à produire détermine des activités, compétences et ressources nécessaires différentes.
Continuer la lecture de Découvrabilité: les données et métadonnées sont-elles toujours utiles?
Les données ne sont pas la panacée de la découvrabilité

Orienter toute initiative de découvrabilité vers la production de données relève de la pensée magique selon laquelle la technologie est la solution à toute problématique, aussi systémique et complexe soit-elle.
Continuer la lecture de Les données ne sont pas la panacée de la découvrabilité
Découvrabilité: sens commun et connaissances partagées
Les formations, référentiels, trousses à outils, programmes de financement et experts en découvrabilité abondent. Tous peuvent se saisir des termes et notions qui circulent sans avoir une compréhension approfondie du Web. C’est, à mon avis, préoccupant car il n’existe pas de traité sur ce qu’il faut faire, dans le numérique, pour qu’une information soit vue. À la différence du génie ou de la médecine, par exemple, il n’y a pas de socle commun de connaissances pour les divers métiers du Web. Un projet numérique est souvent une tour de Babel de concepts. Que des non-spécialistes du numérique, comme des directions d’entreprises, soit dépassés n’est pas étonnant.
Continuer la lecture de Découvrabilité: sens commun et connaissances partagées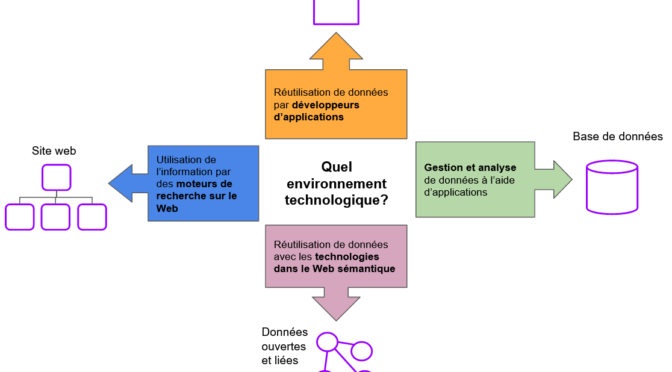
Découvrabilité: oui, mais dans quel environnement technologique?
Favoriser la découverte d’une offre pour atteindre un objectif c’est bien, mais dans quel environnement technologique? La réponse à cette question, rarement abordée, pourrait pourtant aiguiller certains projets ciblant les moteurs de recherche vers de meilleures pratiques de conception et de rédaction pour le Web plutôt que vers la création de métadonnées.
Continuer la lecture de Découvrabilité: oui, mais dans quel environnement technologique?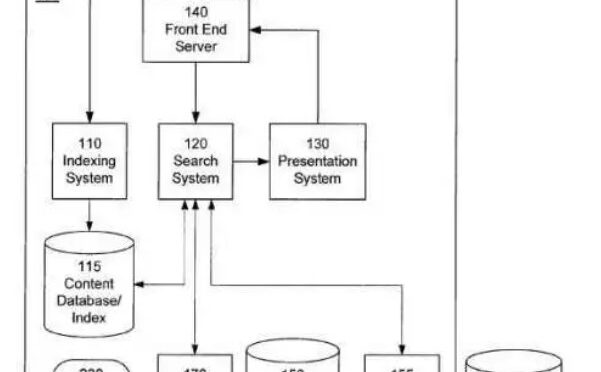
Wikipédia, Wikidata, Google et la découvrabilité: gare au solutionnisme
Le Guide des bonnes pratiques: découvrabilité et données en culture, récemment publié par le Ministère de la Culture et des Communications du Québec, est un bel effort de synthèse. Il faut cependant plus qu’un exercice de rédaction pour transmettre à des non-initiés des connaissances sur des systèmes dont le fonctionnement et les interdépendances sont complexes, changeants et trop souvent, incompris.
Continuer la lecture de Wikipédia, Wikidata, Google et la découvrabilité: gare au solutionnisme
{kind=link}
Découvrabilité: comment aiguiller des initiatives numériques vers la bonne voie

Il est temps d’apporter un peu de clarté dans le méli-mélo de concepts qui ne sont pas très bien maîtrisés. Voici une petite mise au point qui pourrait être bénéfique pour les promoteurs d’initiatives numériques, ainsi que les organisations qui les financent.
Continuer la lecture de Découvrabilité: comment aiguiller des initiatives numériques vers la bonne voie