I want AI-driven products to come with questions, suggestions or answers I wouldn’t have thought of.
Design Principles for AI-driven UX, Joël Van Bodegraven
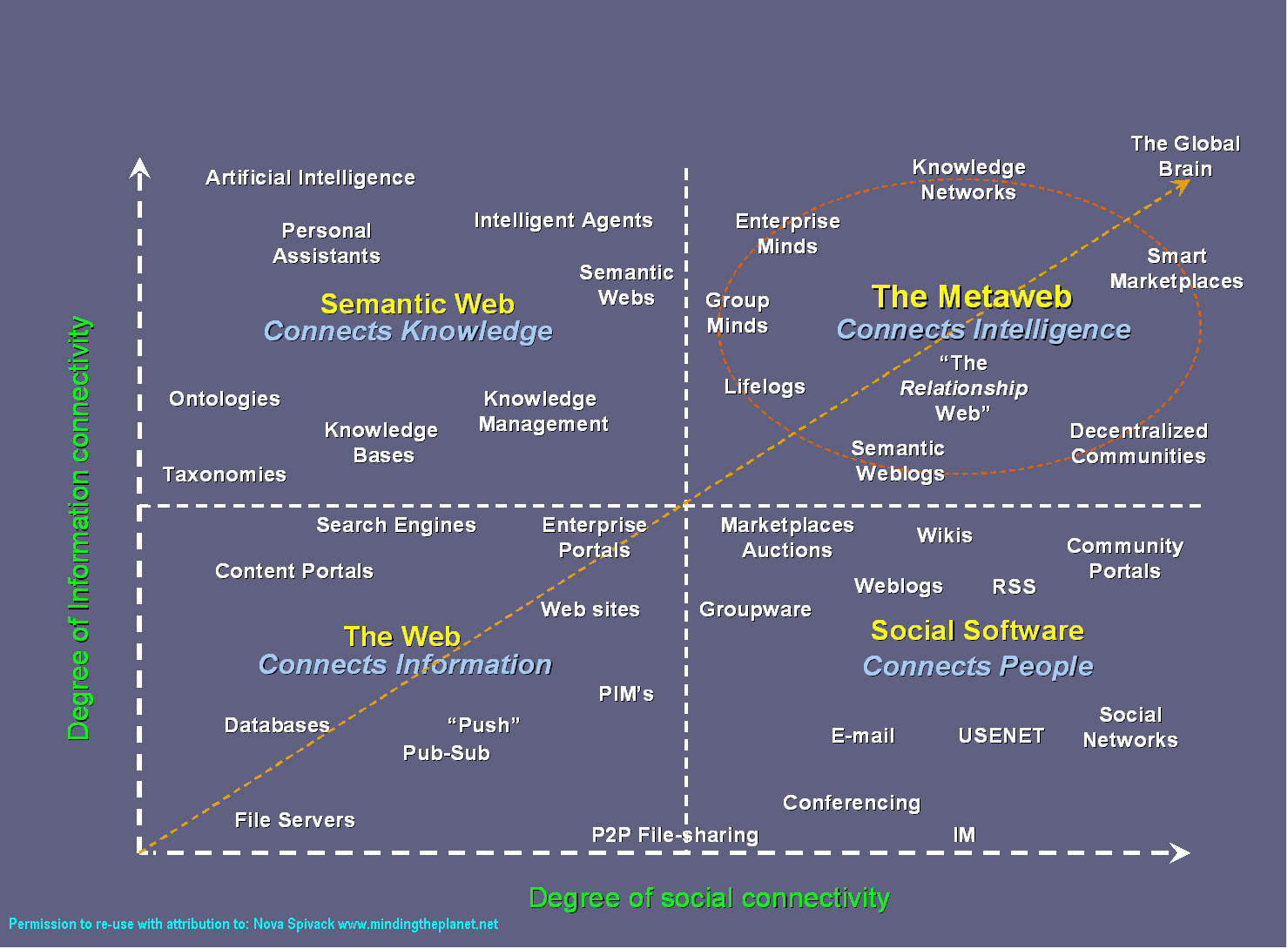
Le web sémantique est cette évolution du web dont une des formes est l’utilisation d’un modèles de données structurées par des moteurs de recherche comme Google. Faire des relations sémantiques entre des données, à l’aide de métadonnées, facilite le raisonnement automatisé sur des inférences. Le web sémantique favorise la découvrabilité, mais permet surtout de repousser les limites que sont nos modèles de pensée et nos systèmes actuels.
Il est essentiel d’améliorer nos systèmes d’information et nos processus et d’adopter les meilleures pratiques du web des données (diapos à visionner absolument) pour produire des données facilement exploitables.