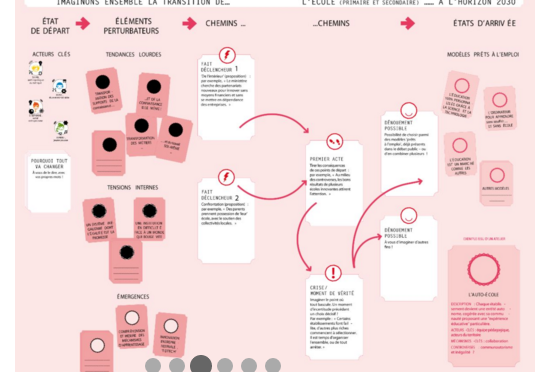
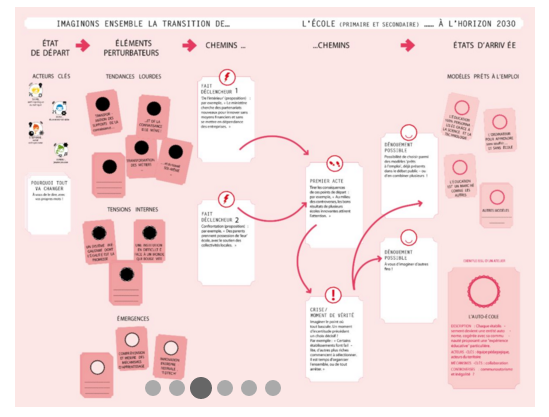
Initialement publié dans le blogue de Direction informatique, le 4 novembre 2015.
Peut-on faire entrer le Québec dans l’ère numérique avec une démarche, des politiques et des programmes de l’ère industrielle?
C’est pourtant l’impression que donne la consultation annoncée il y a une quinzaine de jours par le gouvernement. Comment, alors, échapper au darwinisme numérique, cette sélection naturelle des cerveaux qui met hors jeu ceux qui n’ont pas appris à se réinventer?
La véritable nature du changement
S’il s’agissait uniquement d’un enjeu technologique, la modernisation des infrastructures et des équipements constituerait une piste de solution toute tracée. Cependant, les défis auxquels la société, les industries et les institutions font face sont d’une toute autre nature. Il est important de rendre explicite cette « transformation numérique » dont on parle afin de bien saisir la véritable nature d’une transformation qui est souhaitée ou redoutée, selon notre niveau de confort face à un monde qui change.
Le modèle mental de l’ère industrielle
Consultant et conférencier, Fred Cavazza analyse et commente la progressive adoption des nouveaux usages par les entreprises depuis les premiers âges du web. Selon lui, il est tentant d’adopter de nouvelles technologies, comme un site de commerce en ligne, sans opérer les transformations qui sont pourtant vitales pour les dirigeants et organisations de l’économie numérique. Il insistait encore tout récemment sur l’urgence d’acquérir les connaissances et aptitudes qui sont essentielles à la transformation:
/…/même si c’est plus valorisant et beaucoup moins risqué, résistez à l’envie de procéder à des transformations de surface pour gagner du temps. L’important n’est pas de sauver les apparences, mais de s’intéresser à la partie immergée de l’iceberg. Pour ce faire, la formation est un élément-clé pour transmettre rapidement des savoirs, faire évoluer les mentalités et initier une dynamique de changement en interne.
Victime ou acteur du changement?
Mais pourquoi changer si tout fonctionne encore de manière acceptable? En affaires, comme dans notre vie personnelle, le changement nous est imposé par des circonstances extérieures. Nous ne modifions nos stratégies et nos projets que lorsque nous rencontrons des écueils ou que nous sommes en situation d’échec. Certains esprits clairvoyants tentent d’identifier et de décoder les signaux faibles des discontinuités afin d’avoir le temps de se repositionner. Or, en général, par aversion aux efforts intellectuels et matériels que requiert tout changement, la majorité des individus et des organisations attendent d’être au pied du mur pour réagir. Ce fut le cas des médias. C’est actuellement le cas, entre autres, du commerce de détail et c’est peut-être déjà le cas de plusieurs institutions.
Le numérique, c’est complexe
La révolution numérique étant un phénomène qui transcende les secteurs d’activité humaine, sa définition varie selon la perspective de celui ou celle qui l’expérimente ou l’observe. Cependant, une des plus efficaces démonstrations de la complexité et de l’envergure du changement est l’excellente vidéo (moins de 8 minutes) produite par Michel Cartier il y a déjà cinq ans: Êtes-vous prêts pour le 21e siècle.
Mais alors, comment réussir à prendre le virage numérique avant de frapper le mur? Certainement pas en adoptant des solutions simplistes, limitées aux avancées technologiques et compartimentées par secteur d’activité. Et, surtout pas, en excluant la dimension humaine et sociale du phénomène. Peter Drucker a relevé dès 1967 cet enjeu incontournable de la révolution numérique:
We are becoming aware that the major questions regarding technology are not technical but human questions,
Si la maîtrise des nouveaux outils et usages, qu’il s’agisse de mobilité, d’objets connectés ou de science des données, nous accordait une certaine maturité technologique, il manquerait malgré tout à nombre de nos élus et dirigeants la capacité ou la volonté de sortir du schéma mental qui conditionne actuellement leurs décisions.
Connecter les réseaux
Évidement, on ne devient pas visionnaire en suivant une formation, mais on peut se mettre à l’écoute de ceux qui décodent et expérimentent les changements. On peut également se sensibiliser aux enjeux qui bouleversent les écosystèmes socioéconomiques comme l’on fait les élus, ailleurs dans le monde, qui ont rassemblé les forces vives de l’innovation dans divers domaines au cours d’états généraux ou d’assises publiques.
Comment transformer les mentalités, les usages et les modèles afin que des écosystèmes complets se reconfigurent et que nous ne devenions pas que les clients, mais les bâtisseurs de la nouvelle économie? Dans un billet publié récemment, j’écrivais : « Si nous retirions le mot « numérique » de l’expression « transformation numérique », nous inviterions probablement les bonnes personnes autour des tables de discussion ».
Sommes-nous prêts, élus, dirigeants, chercheurs, créateurs et citoyens, pour ce type de changement?
Une réflexion sur « Québec numérique: le vrai changement n’est pas technologique »