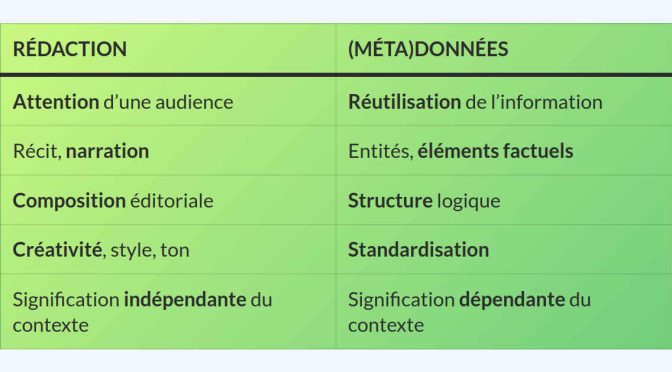
De façon générale, les initiatives visant à promouvoir une offre culturelle afin de favoriser sa « découvrabilité » concernent les moteurs de recherche comme Google ou des plateformes en ligne, existantes ou à concevoir. Ce sont cependant deux types de projets différents pour lesquels le type d’information à produire détermine des activités, compétences et ressources nécessaires différentes.
Continuer la lecture de Découvrabilité: les données et métadonnées sont-elles toujours utiles?Archives par mot-clé : wikipédia
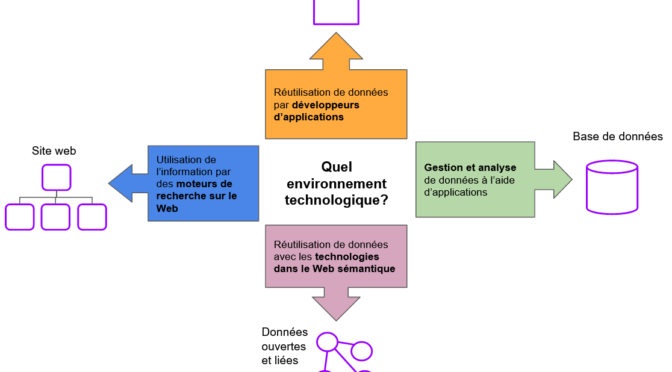
Découvrabilité: oui, mais dans quel environnement technologique?
Favoriser la découverte d’une offre pour atteindre un objectif c’est bien, mais dans quel environnement technologique? La réponse à cette question, rarement abordée, pourrait pourtant aiguiller certains projets ciblant les moteurs de recherche vers de meilleures pratiques de conception et de rédaction pour le Web plutôt que vers la création de métadonnées.
Continuer la lecture de Découvrabilité: oui, mais dans quel environnement technologique?
Wikipédia, Wikidata, Google et la découvrabilité: gare au solutionnisme
Le Guide des bonnes pratiques: découvrabilité et données en culture, récemment publié par le Ministère de la Culture et des Communications du Québec, est un bel effort de synthèse. Il faut cependant plus qu’un exercice de rédaction pour transmettre à des non-initiés des connaissances sur des systèmes dont le fonctionnement et les interdépendances sont complexes, changeants et trop souvent, incompris.
Continuer la lecture de Wikipédia, Wikidata, Google et la découvrabilité: gare au solutionnisme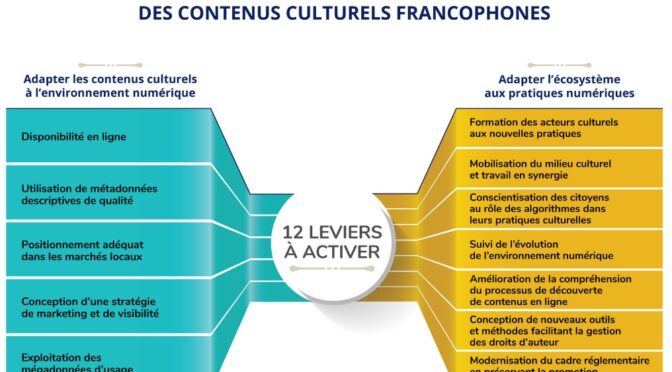
Deux leviers à ajouter au rapport de la mission franco-québécoise sur la découvrabilité
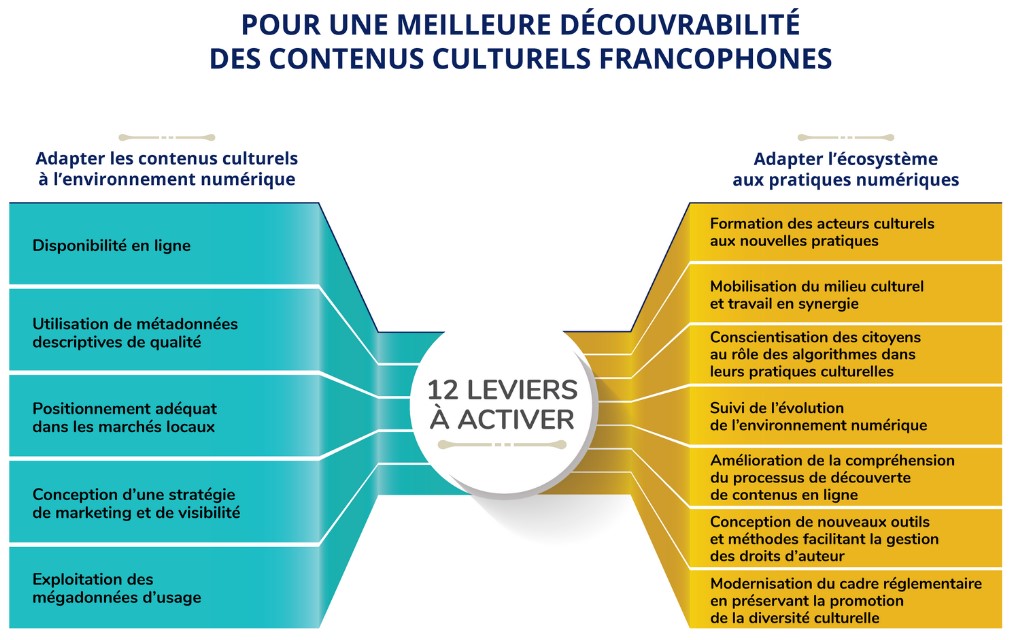
Le rapport sur la découvrabilité en ligne des contenus culturels francophones résulte d’une mission conjointe des ministères de la Culture du Québec et de la France. Il dresse un bon état des lieux d’un ensemble de phénomènes et d’actions, sans égarer le lecteur dans les détails techniques. Un excellent exercice de synthèse, donc, réalisé par Danielle Desjardins, auteure de plusieurs rapports pour le secteur culturel et collaboratrice du site de veille du Fonds des médias du Canada.
Cependant, dans le schéma des 12 leviers à activer pour une meilleure découvrabilité des contenus culturels francophones (voir plus haut), il manque à mon avis deux éléments essentiels:
- Est-ce aux acteurs culturels que revient la charge de rendre l’information concernant leurs créations ou leurs offres numériquement opérationnelle?
- Quel espace numérique offre les meilleures conditions de repérabilité, d’accessibilité et d’interopérabilité de l’information ?
Premier levier: mises à niveau des métiers du Web
Il est important de sensibiliser les acteurs culturels à l’adoption de pratiques documentaires telles que l’indexation de ressources en ligne. Ceci dit, la mise en application des principes, ainsi que le choix de modèles de représentation de contenus en ligne, sont des compétences qui ne s’acquièrent pas comme on apprend à se servir d’un logiciel. On ne peut pas attendre de toute personne et organisation du secteur culturel de tels efforts d’apprentissage. D’autant plus que la production de l’information pour le numérique fait appel à des méthodes et savoirs relevant des domaines du langage et de la représentation des connaissances autant que des technologies numériques.
Si les données structurées sont perçues comme des solutions pouvant accroître la visibilité d’offres culturelles sur nos écrans, elles appartiennent à des domaines de pratiques pas suffisamment maîtrisés au sein des métiers du Web. C’est pourtant bien vers des spécialistes en développement, intégration, référencement et optimisation que se tournent les acteurs culturels cherchant à rendre le contenu de leurs sites web plus interprétable par des machines. Or, à ma connaissance, il n’existe actuellement pas de formation et de plan de travail tenant compte de l’interdépendance des volets sémantiques, technologiques et stratégiques du web des données.
Il devient de plus en plus impératif d’identifier les connaissances à développer ou à approfondir chez les divers spécialistes contribuant à la conception de sites web aux contenus plus repérables. Il serait également souhaitable de soutenir un réseau de veille interdisciplinaire ayant pour objectif de contextualiser et d’analyser l’évolution de l’écosystème numérique.
Exemple: dans la foulée d’une étape importante de ses capacités d’interprétation (traitement automatique du langage), Google a mis à jour, cet été, ses directives d’évaluation de la qualité de l’information. Il va sans dire que c’est important.
Deuxième levier: modernisation des sites web
Dans le Web des moteurs de recherche intelligents, la reconnaissance des entités passe par l’indexation de pages web et l’analyse des contenus. Les sites web devraient donc être des sources d’information de première qualité, tant pour les internautes que pour les moteurs de recherche.
Est-il normal de ne pas trouver toute l’information, riche et détaillée, sur le site de référence d’une entreprise culturelle? Pour le bénéfice des projets numériques, il est vital de concevoir des contenus pertinents pour les machines, lesquelles évaluent à présent la qualité des sources d’information afin de générer la meilleure réponse à retourner à l’utilisateur.
Pour une productrice ou un artiste, il est beaucoup plus stratégique de faire de son site web une source primaire, en attribuant une page spécifique à la description de chaque œuvre, que de créer un article sur Wikipédia. Rappelons que Wikipédia n’est pas une source primaire pour les moteurs de recherche. De plus, l’usage du vocabulaire (Schema.org) ne leur fournit qu’un signal faible sur la nature d’une offre.
Un savoir commun, entre information et informatique
L’adaptation des contenus culturels à l’environnement numérique repose, avant tout, sur de meilleurs sites web. Ces espaces offrent les conditions optimales d’autonomie, repérabilité, accessibilité et interopérabilité. Leur modernisation requiert des acteurs clés, que sont les spécialistes du Web, une mise à niveau rapide de leurs connaissances et de leurs pratiques.
Finalement, afin d’opérer cette mise à niveau et de développer ces savoirs communs, il faut bien entendu insister sur l’interdisciplinarité entre les métiers du web et, notamment, le domaine des sciences de l’information.