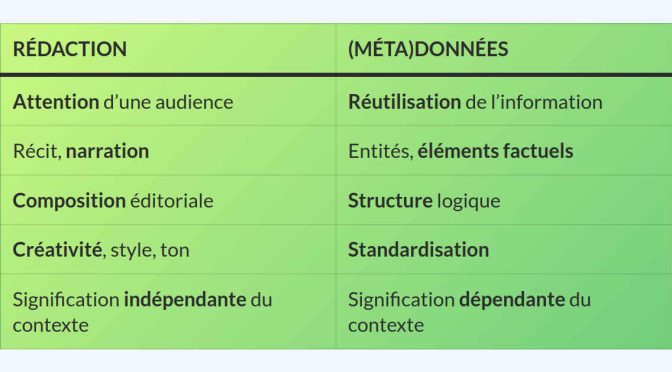
Wikidata améliore-t-il la découvrabilité sur Google? Non.
Contrairement à une hypothèse que j’ai parfois évoquée il y a plusieurs années, puis maintes fois remise en cause, Wikidata n’est pas une solution de découvrabilité sur Google. C’est l’une des bases de connaissances permettant de valider une entité, et non de fournir une réponse. Ce n’est pas un moyen de promouvoir une information pour quiconque interroge Google, et encore moins pour qui ne la cherche pas.
Verser des données dans Wikidata ne rend donc pas un objet culturel plus visible ou découvrable parmi les résultats du moteur de recherche. Cependant, c’est une initiative à fort potentiel de créativité et de transformation numérique si l’on poursuit un tout autre but que la promotion d’une offre, soit la réutilisation de données interopérables et interconnectables, partout sur la planète.
Wikidata pour le Web des données
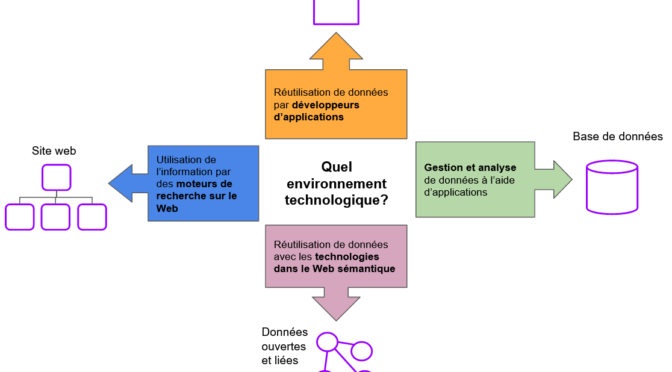
Par contre, comme je l’ai précisé dans un billet sur le choix d’un environnement technologique, contribuer à Wikidata peut favoriser la découverte de données sur cette plateforme. La maîtrise du langage d’interrogation SPARQL est cependant une courbe d’apprentissage plutôt abrupte pour les non-spécialistes. Même l’assistant de recherche est inaccessible pour qui n’a pas l’habitude de composer des requêtes destinées à des bases de données.
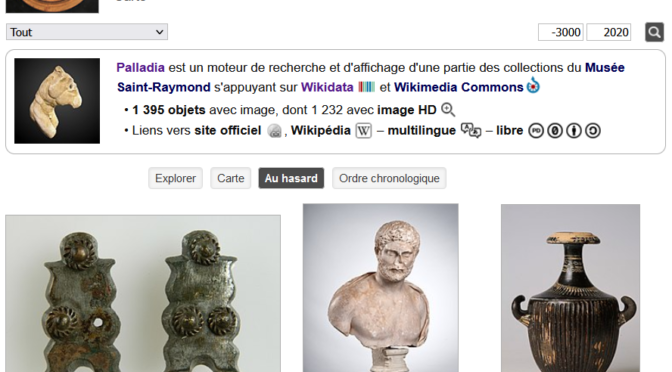
Les organisations versant leurs données dans Wikidata devraient offrir, sur leurs propres sites, des interfaces de recherche avec des requêtes pré-construites. L’exemple présenté ci-dessous est un projet réalisé par le Musée de Saint-Raymond à Toulouse (France) en partenariat avec Wikimedia France.
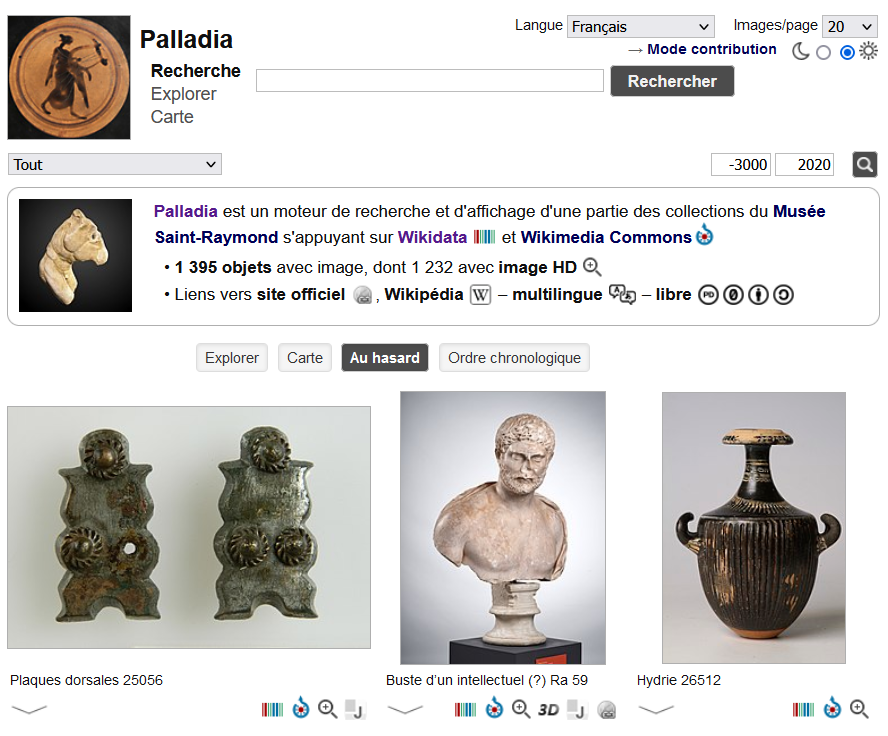
Pour s’en inspirer davantage, voici l’historique des projets Crotos et Palladia sur WikiArchives, avec un lien complémentaire vers un billet de Marie D. Martel datant de 2017 mais qui demeure tout à fait pertinent: #wikimania Le modèle d’une pratique professionnelle alternative à bâtir avec les GLAMs.
Cette réutilisation des données dans les deux sens — dans l’environnement ouvert et collaboratif de Wikidata et dans la perspective spécifique d’une institution — présente de précieux avantages:
Impulsion d’une véritable transformation
Un projet de données ouvertes et liées peut contribuer à la transformation d’une organisation dans un contexte numérique. Il ne s’agit pas d’informatisation, mais d’un projet fédérateur qui peut transformer les rapports à l’information et à la communication. Si c’est un choc culturel pour certaines institutions, c’est potentiellement un environnement d’apprentissage et, au final, une véritable transformation numérique pour toute forme d’organisation.
Modernisation d’un système de gestion documentaire
Des données liées offrent un énorme potentiel de découverte et de connaissance car elles ne sont pas figées dans un modèle où les relations sont prédéfinies. Ceci accorde à une base de données en graphe (appelée aussi graphe de données liées) la capacité d’effectuer du raisonnement, ce que la technologie des bases de données classiques n’offre pas.
Contournement des défis du Web sémantique
Wikidata réduit considérablement les coûts, délais et expertises requises pour la réalisation d’un projet de données ouvertes et liées en fournissant, entre autres, la plateforme et l’ontologie. Bien plus complexe qu’un vocabulaire, une ontologie est la spécification d’une conceptualisation, à l’aide de types d’objets, de leurs propriétés et de leurs différents types de relations. C’est un exercice d’abstraction réalisé par un petit nombre de spécialistes
Interopérabilité accrue des données
L’ontologie qui permet de modéliser les données pour Wikidata n’est pas conçue pour représenter le concepts propres à chaque domaine de connaissance. C’est un avantage: alors qu’une base de données classique est conçue pour répondre aux besoins et usages d’un domaine ou discipline, Wikidata ne cloisonne pas la connaissance et favorise, de ce fait, les interconnexions.
Petit rappel
Une base de données classique et un graphe de données liées ne sont pas exploitables pour les moteurs de recherche comme Google.
Deux grands défis d’un projet de données
Un projet de données liées comporte des défis qui doivent impérativement être identifiés et analysés en amont de toute conception ou acquisition de technologie. Voici deux de ces défis:
Expérience de recherche
Des données liées doivent permettre d’offrir des fonctions de recherche différentes de (et supérieures à) celles d’une base de données classique.
Une recherche par auteur, titre et sujet n’apportera pas de nouvelles connaissances. Les critères d’une recherche avancée ne sont pas de bons moyens pour faire découvrir une collection à qui ne cherche rien en particulier.
Mobilisation des utilisateurs(trices)
Changer le comportement de personnes qui accèdent à de l’information en posant simplement une question (Google, ChatGPT) ou de façon passive (flux des réseaux sociaux) est très certainement l’un des plus grands défis des nouvelles base de données en ligne.
Comment faire d’un site une destination préférée pour chercher ou découvrir de l’information? Hélas, nombreux sont les projets qui ne reposent que sur une campagne de promotion pour modifier des habitudes devenues des réflexes.
Wikidata: oui, mais pour des résultats concrets
Le versement de données dans Wikidata ne devrait pas être promu comme une bonne pratique de référencement web et de découvrabilité sur Google.
Cependant, un projet avec Wikidata peut faire converger deux buts: développer une culture de la donnée et amorcer une véritable transformation numérique impliquant de nouveaux modes d’organisation et de collaboration.