Mise à jour 2019-05-24: ajout d’une question et sa référence, en conclusion.
La recherche du Graal de la découvrabilité, ce moyen qui accroîtra la «consommation» de nos produits culturels, peut-elle nous faire tomber dans le piège de la solution technologique qui nous fait oublier le problème ?
Solution simple et problématique complexe
Appelé « solutionnisme » par l’historien des sciences Evgeny Morozov, c’est la proposition d’une solution technologique à un problème d’origine complexe. Ceci a pour effet d’escamoter les débats qui sont essentiels à la recherche de solutions pour le bien commun.
Moins de quatre ans se sont écoulés depuis le sommet qui a propulsé le terme « découvrabilité » jusque dans les hautes sphères décisionnelles, en culture. Depuis lors, des événements et programmes de financement de la culture ont intégré cette thématique ou certains de ces éléments les plus emblématiques, comme les métadonnées.
Je réalise, depuis quelques années, des ateliers sur la découvrabilité et les métadonnées, avec les Fonds Bell et Fonds indépendant de production. Une collaboration avec Marie-Ève Berlinger apporte à ma démarche exploratoire la dimension stratégique de la promotion numérique. C’est dans ce contexte que nous avions échangé sur les mythes de la découvrabilité, au cours du Forum avantage numérique.
Voici quelques constats qui se rapportent aux mythes qui sont spécifiques à la production de métadonnées pour les moteurs de recherche.
La découvrabilité n’est pas une finalité
La finalité d’un plan de découvrabilité est le fruit d’une réflexion stratégique. Celui-ci fournit les questions, le contexte et le cadre sans lesquels la découvrabilité n’aurait pas d’autre objectif que de fournir des données à un moteur de recherche. Ce sont les activités de marketing et de promotion qui produisent des résultats mesurables.
L’exploitation des métadonnées par les moteurs de recherche n’est qu’un des piliers de la découvrabilité. Cette approche a été illustrée dansle cadre d’un projet auquel je collabore, avec Véronique Marino et Andrée Harvey (La Cogency).
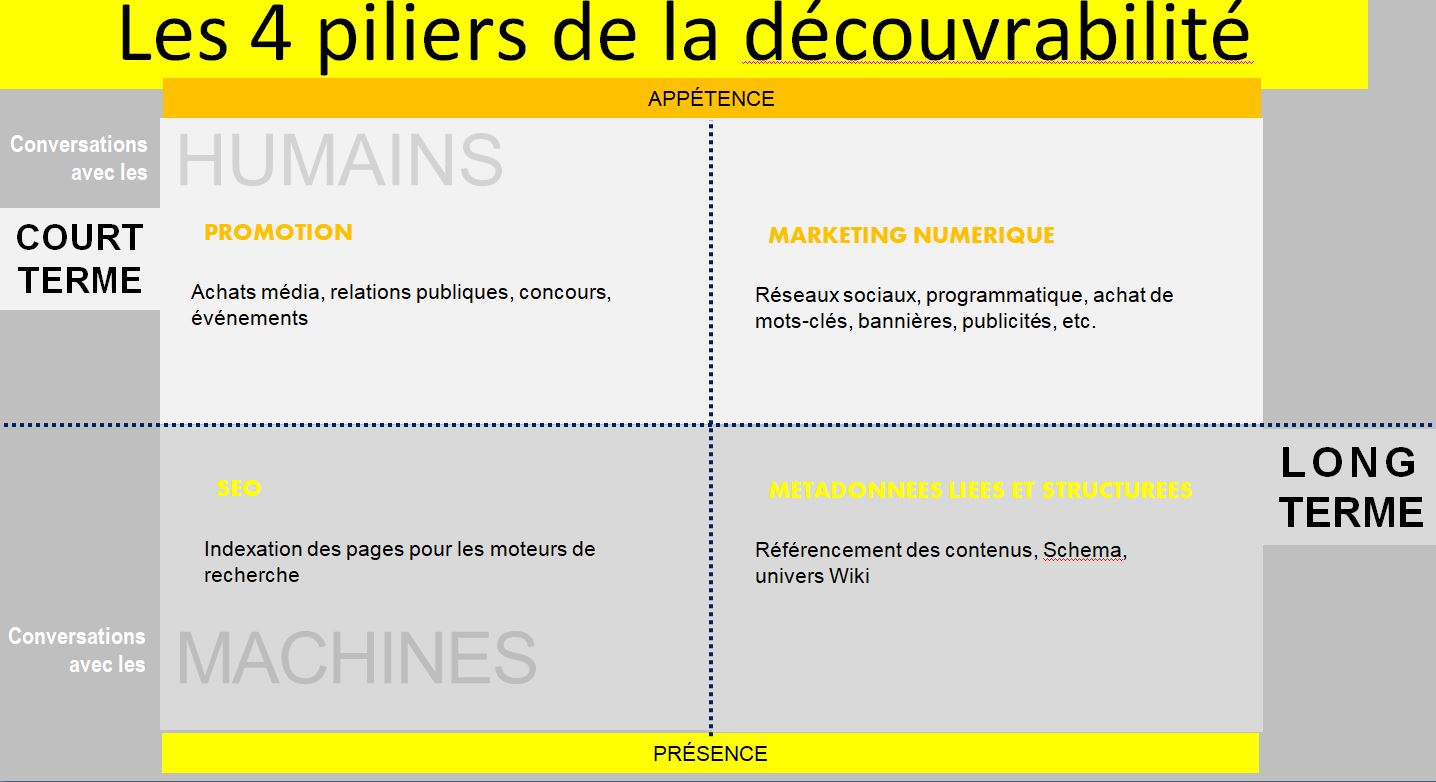
Il est surprenant de constater que la stratégie et les moyens techniques ne sont pas intimement intégrés dans des projets numériques. Il y a une importante mise à jour des connaissances conceptuelles et techniques à opérer au sein des agences qui conseillent et accompagnent les organismes et entreprises.
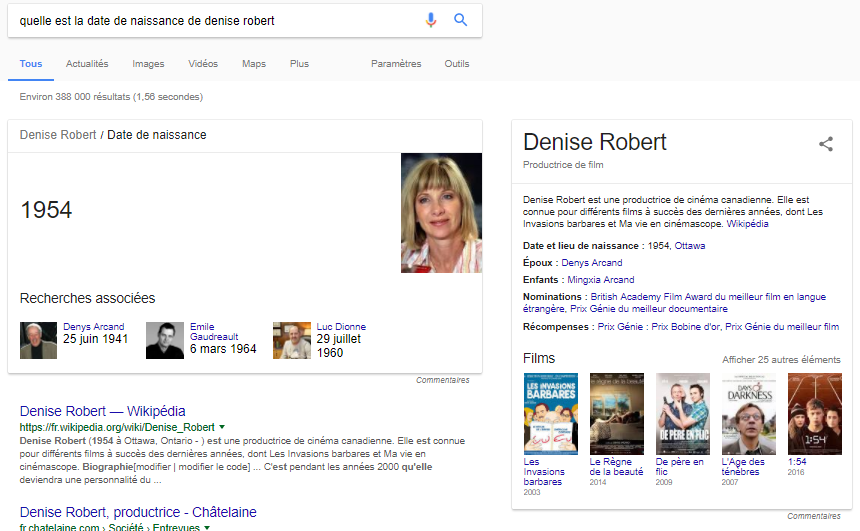
La réponse n’est pas une page web
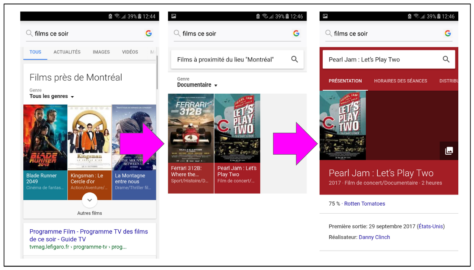
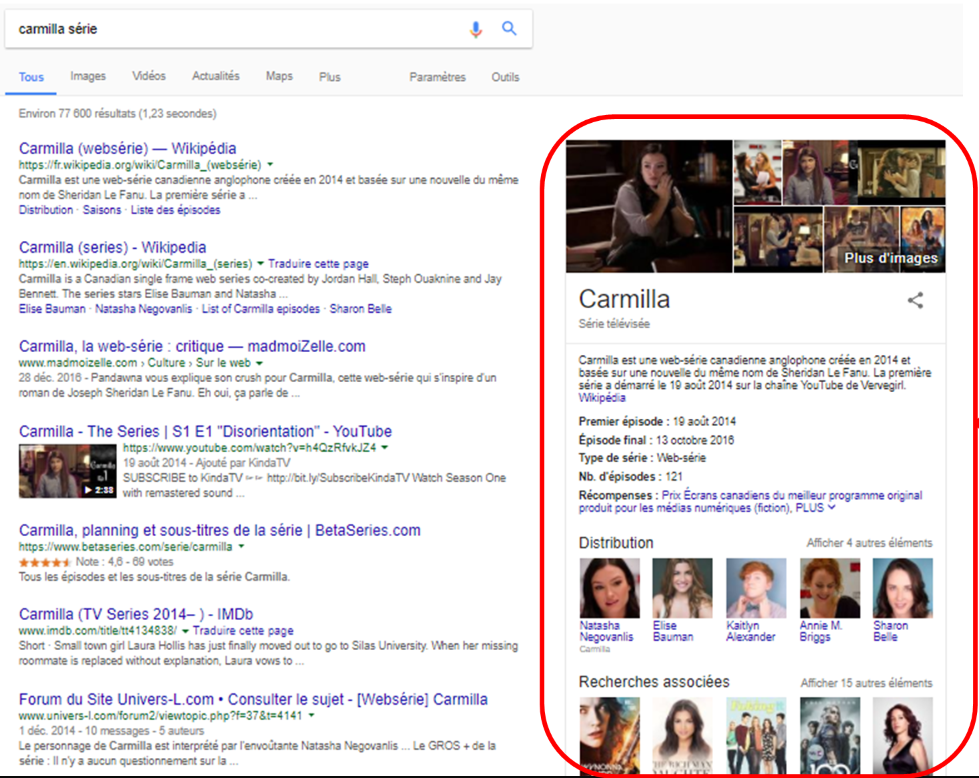
La fiche d’information qui constitue la réponse du moteur de recherche (à la droite de la liste de résultats) n’a pas pour objectif de diriger l’utilisateur vers une page web spécifique. Elle rassemble différents éléments d’information afin de fournir la réponse la plus précise possible. Il faut donc sortir de la logique de la liste de résultats et ne pas penser l’usage des métadonnées en fonction d’une destination.
Les liens entre les éléments d’information qui composent la fiche de réponse construisent des parcours qui orientent la recherche de l’utilisateur, sans nécessairement aboutir sur un site web. Par exemple, chercher une oeuvre de VanGogh, comme la Nuit étoilée, permet de mesurer la distance et les clics qui nous séparent du site web du Museum of Modern Art.
Ceci accroît la collecte des données d’usage qui permettent d’analyser l’intention, le comportement et la consommation de l’utilisateur. Plus les fonctions et choix offerts sont utiles, plus l’utilisateur demeure dans l’interface du moteur de recherche. Les agrégateurs d’information, qui font face à la désintermédiation de leur services, constateront probablement une diminution progressive du volume de données qui sont collectées sur leurs pages.
L’effet des métadonnées est dans la durée
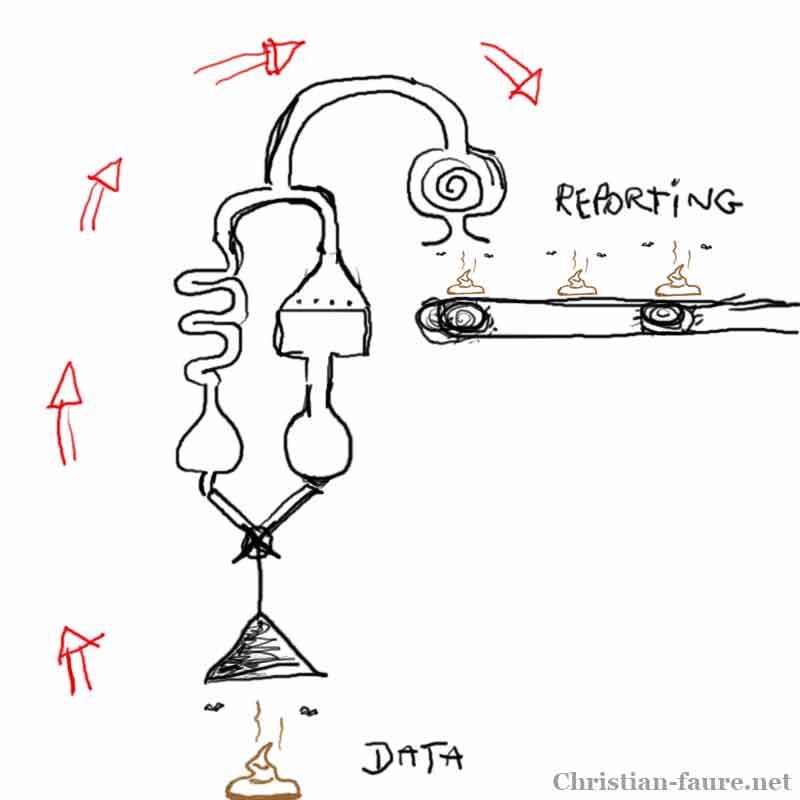
Les résultats de l’utilisation de métadonnées pour décrire des contenus ne sont pas mesurables, au sens strict.
La qualité de l’encodage des métadonnées peut être validée, mais l’outil de test ne peut juger la logique de la description (interprétation des balises uniquement). Une validation que peu de producteurs de métadonnées semblent se donner la peine de faire. Il est également possible d’attribuer un indice de découvrabilité à une information en fonction de critères spécifiques.
L’effet des métadonnées peut être observé sur un temps long. L’enrichissement progressif de la fiche de réponse illustre le potentiel qu’a une offre d’être liée par le moteur de recherche à d’autres informations. Il n’est pas possible de fournir des résulats immédiats et quantifiables, de façon similaire aux stratégies de référencement organique et payant de pages web.
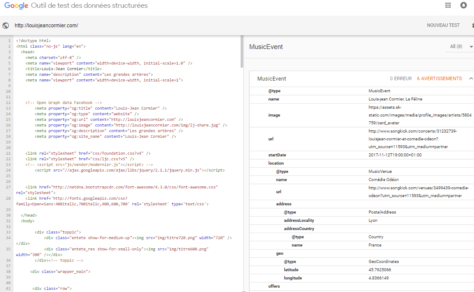
Schema.org n’est pas le moteur de recherche
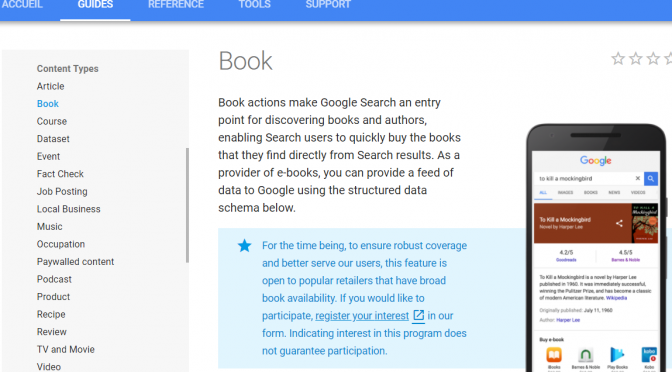
Schema est un vocabulaire commun de métadonnées qui a été développé pour les moteurs de recherche. Google recommande l’intégration des métadonnées sous forme de balises dans le code HTML d’une page afin de décrire l’offre qui y est présente. Cependant, les règles de l’algorithme évoluent au fil des expérimentations du moteur de recherche. Les métadonnées Schema qui étaient recommandées pour décrire des offres de type Movie, TVSeries et Music existent toujours. Cependant, Google n’en recommande plus l’usage et invite les entreprises concernées à faire une demande pour devenir des partenaires médias. Jusqu’où, alors, faut-il investir pour indexer une offre si le fonctionnement de l’algorithme et l’évolution du moteur de recherche nous sont inconnus ?
Une réflexion stratégique est nécessaire pour répondre à cette question. Deux avenues s’ouvrent:
1. Rendre des offres interprétables pour les moteurs de recherche (indexation) et appuyer la stratégie de référencement du site
- Fournir uniquement les métadonnées Schema qui sont obligatoirement requises par le moteur de recherche. Ceci fait partie des bonnes pratiques du développement de sites web.
- Tout comme pour le référencement, il est important d’assurer une veille sur l’évolution des fonctions analytiques et techniques des moteurs de recherche.
2. Valoriser les éléments d’un catalogue ou d’une collection en produisant un graphe de données liées
- Fournir des métadonnées très riches selon le vocabulaire Schema.
- Prévoir un important travail de modélisation (de préférence, par une personne compétente) afin de mettre en valeur des attributs et des liens, en travaillant sur les propriétés et les niveaux hiérarchiques.
Enjeux d’importance pour une stratégie numérique:
- Aucun résultat garanti sur le traitement des métadonnées par le moteur de recherche. Ceci ne doit donc pas être l’unique objectif d’un tel projet.
- Vocabulaire et modèle de représentation uniques: uniformisation de la représentation répondant aux objectifs d’affaires des moteurs de recherche.
Précision 2019-05-25: ce billet concerne uniquement le langage de balisage pour moteurs de recherche (métadonnées Schema) et non la représentation des connaissances avec les standards du web sémantique.
Pas de solution, mais quelques questions
L’uniformisation des modèles descriptifs est-elle un risque pour la diversité culturelle ?
La problématique de la «consommation culturelle» ne devrait-elle pas être abordée dans les deux sens ? En orientant nos projets sur la promotion, nous oublions la relation au public et l’analyse de ce qui rend une oeuvre de création attractive. Ce rapport sur les pratiques culturelles numériques et plateformes participatives, piloté par la chercheuse Nathalie Casemajor, contient des pistes de réflexion à ne pas négliger, dont cellec-ci:
Les efforts de découvrabilité ne suffisent pas à eux seuls à créer l’appétence culturelle, et l’analyse des données consommatoires et comportementales n’est pas la panacée pour agir sur le développement des goûts et des dispositions culturelles en amont.
Nous devrions nous donner des moyens pour définir les modalités et conditions de la découvrabilité que nous souhaitons. Celles-ce se trouvent quelque part, entre le monde vu par une entreprise et celui que nous voyons au travers du prisme de nos cultures et sensibilités, d’une part, et, d’autre part, entre lier des données pour un objectif de marketing et faire du lien social autour d’objectifs communs.