Le Guide des bonnes pratiques: découvrabilité et données en culture, récemment publié par le Ministère de la Culture et des Communications du Québec, est un bel effort de synthèse. Il faut cependant plus qu’un exercice de rédaction pour transmettre à des non-initiés des connaissances sur des systèmes dont le fonctionnement et les interdépendances sont complexes, changeants et trop souvent, incompris.
Continuer la lecture de Wikipédia, Wikidata, Google et la découvrabilité: gare au solutionnismeArchives par mot-clé : participation
Solutionnisme et inégalités: gare aux écueils de la transformation numérique

Imaginer nos propres solutions
J’ai élaboré, dans un précédent billet, sur le piège du solutionnisme technologique: « Ce ne sont pas des plateformes numériques qui ont permis à Netflix et compagnie de bouleverser l’industrie. C’est d’avoir compris le potentiel du Web et pensé autrement l’accès, la distribution et la production de contenus audiovisuels, en osant remettre en question les modèles établis.»
Cette expression peut s’appliquer au sentiment d’urgence qui nous pousse vers le développement d’un outil avant même d’avoir défini le problème, exploré les causes possibles et analysé les systèmes sociaux et techniques.
Il ne faut pas tomber dans ce piège et nous contenter de reproduire des stratégies et des outils qui ont été conçus pour servir d’autres objectifs que les nôtres.
Internet pour réduire les inégalités
Voici quelques éléments qui favoriseraient la transformation numérique, en commençant par la condition de base:
- Accès Internet sur tout le territoire.
- Accès Internet à la maison (gratuit ou à coût modique).
- Bande passante nécessaire pour l’accès de qualité à du contenu audiovisuel.
- Ordinateur à la maison (échapper aux coûts de l’obsolescence programmée, promouvoir les logiciels libres). Équipement en nombre suffisant pour les besoins d’une famille confinée.
- Connaissances informatiques et habiletés numériques suffisantes (autonomie des utilisateurs, sécurité informatique, protection de la vie privée).
- Équipement adapté et logiciels et contenus web accessibles aux personnes en situation de handicap temporaire ou permanent.
- Service de médiation: outils d’accès –et de contribution– à la connaissance et à la culture, littératie de l’information (bibliothèques publiques, initiatives citoyennes).
- Commerçants, fonctionnaires, profs et professionnels ayant des compétences numériques suffisantes ou les ressources nécessaires pour offrir un bon niveau de services en ligne.
- Amélioration du niveau d’alphabétisation (compréhension des consignes d’utilisation des services en ligne et des instructions techniques).
Technologies plus simples, accessibles et durables
Dans une tribune, Jean-François Marchandise, cofondateur de la Fondation Internet nouvelle génération, partage ce constat sur le besoin de médiation numérique :
Aujourd’hui, une grande partie de l’innovation numérique repose sur un numérique de luxe. Nous allons vers des « toujours plus », adaptés à un monde en croissance éternelle et en ressources infinies…
A contrario, il va davantage falloir composer avec un numérique moins high tech, qui puisse fonctionner avec trois bouts de ficelle, de manière plus décentralisée, avec une moindre dépendance au lointain, une relocalisation des savoir-faire.
De plus, si tous les citoyens sont égaux, ne devrions-nous pas élaborer des propositions numériques en fonction du plus bas dénominateur numérique commun ?
Pilotage d’initiatives et intelligence collective
Cette pandémie devrait nous faire réaliser que nous devons changer nos méthodes de travail et prendre garde aux inégalités numériques et au solutionnisme technologique.
Si nous souhaitons tirer des apprentissages constructifs de la complexité de cette situation, nos équipes de projets doivent être interdisciplinaires et nos analyses doivent tenir compte de l’interdépendance des systèmes. Les outils de communication et de travail collaboratif peuvent faciliter la circulation des idées. Cependant, seule une réelle transformation du pilotage des initiatives numériques, vers une forme d’intelligence collective, pourrait les rendre plus efficaces et accroître leurs bénéfices.
Pour que le Québec puisse se relever le plus rapidement de cette crise, l’ensemble de la société doit participer à la création de valeur (savoir, culture, industrie). Et pour cela, il faudrait d’abord réparer la fracture numérique, faire de l’accès Internet un service public essentiel et apprendre à piloter des projets dans la complexité.
Tendance zéro clic: leçons à tirer pour des initiatives plus marquantes
Mise à jour 2019-10-02: ajout d’un exemple récent d’initiative à fort potentiel transformateur.
La tendance zéro clic se confirme. Les moteurs de recherche fournissent dans leurs propres interfaces, des réponses, à partir de données collectées sur des sites web. Ils sont ainsi les principaux bénéficiaires de l’information que nous structurons afin de rendre nos offres plus visibles.
Partenariat inéquitable
De plus, en développant des interfaces d’information spécialisées (voyage, musique, musées, entre autres), ils se substituent aux agrégateurs et portails traditionnels. Cette désintermédiation est particulièrement dommageable pour les structures locales qui produisent de l’information. Celles-ci sont privées de données d’usage qui leur permettraient de mieux connaître leur marché et de s’ajuster à leurs publics.
Effacement de la diversité culturelle
Donc, lorsque nous décrivons nos offres à l’aide de données structurées, sur le modèle Schema.org, et de services comme Google Mon entreprise, nous travaillons pour des moteurs de recherche. De plus, nous nous conformons à un vocabulaire de description, une classification et une vision du monde uniques. Ce constat est un problème pour la diversité culturelle, surtout pour les groupes ethniques et linguistiques en situation minoritaire.
Que faire ? Fournir un service minimum
Cependant, ne pas décrire nos offres avec des balises sémantiques équivaut à refuser de faire indexer nos pages web par les robots des moteurs et, par conséquent, à rendre nos offres et nos contenus invisibles et incompréhensibles pour Google, Bing, Yahoo! et Yandex (moteur de recherche russe).
Alors, que faire pour ne pas demeurer des fournisseurs de contenus et de données (voir l’exemple des musées virtuels sur Google Arts & Culture) ?
Tout d’abord, il faudrait donner un « service minimum » aux moteurs de recherche en fournissant uniquement l’information qui est exigée pour certaines offres. Google publie des instructions concernant les balises à renseigner, ainsi que les éléments de contenu à publier pour divers types d’offres.
Attention, Schema.org n’est qu’un vocabulaire. Ce n’est pas Google. Les moteurs de recherche exploitent les balises selon leurs propres règles. Celles-ci évoluent fréquemment, notamment, pour certains types de contenus. Par exemple, Google annonce clairement ses préférences, dans le domaine du livre, en réservant son attention aux distributeurs qui utilisent les balises selon ses instructions.
Que faire d’autre ? Aller vers le web des données
Nous mettons les moteurs de recherche et plateformes commerciales au centre de nos projets. Cependant, nous n’en maîtrisons pas le fonctionnement et nous n’avons aucun moyen de contrôle sur leur développement. Nous y investissons beaucoup d’efforts afin de positionner nos offres dans l’espoir d’accroître la consommation.
Et si nous élargissions notre définition de la découverte plutôt que de la centrer sur des activités de promotion? Ne pas nous limiter à la finalité économique de l’utilisation des données nous permettrait d’en embrasser le plein potentiel pour le développement de la culture et de l’éducation. Si nous choisissions de développer des initiatives en dehors des systèmes contrôlés par les acteurs dominants de l’économie numérique, nous pourrions être plus ingénieux et, finalement, créer plus de valeur pour nos propres écosystèmes.
Apprendre à jouer collectif
Il y a 25 ans, ce 1er octobre, Tim Berners-Lee fondait le World Wide Web Consortium pour permettre à une communauté mondiale de développeurs et spécialistes divers de collaborer afin de définir des standards pour maintenir un web ouvert, accessible et interopérable pour tous.
Accroître le potentiel de la découverte passe par la décentralisation de la gestion de l’information, le partage de connaissance sous forme de données ouvertes et liées, selon les standards du web et par une redistribution plus équitable du pouvoir décisionnel. Wikipédia, Wikicommons et Wikidata, qui sont des projets de la Wikimedia Foundation, exemplifient ce modèle contributif qui donne à chacun la possibilité de participer au contenu et à la gouvernance.
Inventer d’autres formes de découverte
Tous les acteurs du domaine culturel n’ont pas les compétences et les ressources requises pour évaluer, modéliser et connecter des données avec les technologies du web sémantique. Wikidata constitue une option plus accessible: le référentiel, le mode de gouvernance et l’infrastructure n’ont pas à être développés. Ceci a pour principal avantage d’expérimenter rapidement la production et l’utilisation de données liées.
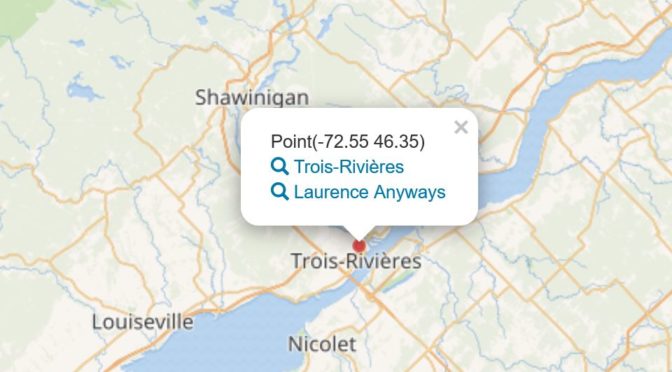
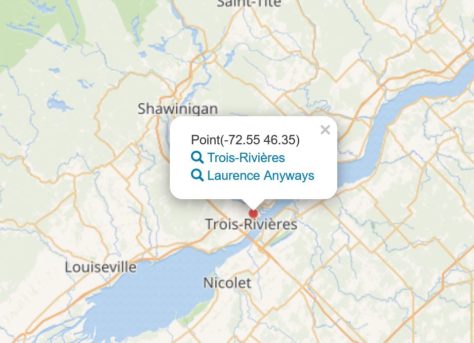
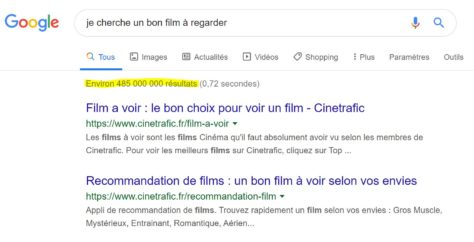
Les requêtes préconstruites qui permettent d’interroger les données de Wikidata offrent un aperçu du potentiel d’un projet contributif pour la valorisation de l’information. Par exemple, la requête 6.16 qui permet de cartographier tous les films en fonction du lieu où se déroule l’action. Lancez la requête en cliquant sur le pictogramme (flèche blanche sur fond bleu) à la gauche de l’écran. Les données des films localisés au Québec ne sont pas exhaustives et sont souvent imprécises (information incomplète, lieu fictif).
Si d’autres sources d’information étaient disponibles sous forme de données liées, on pourrait imaginer une interface où se croiseraient des images des lieux, des biographies d’acteurs et actrices ou des titres de chansons.
*** Mise à jour 2019-10-02
Voici un autre exemple d’initiative qui prend sa source hors des règles imposées par les moteurs de recherche et plateformes. Il s’agit de projets réalisés avec Wikipédia par le Musée national des beaux-arts du Québec. Cette initiative est à la fois, une contribution du musée à la connaissance mondiale, tout en permettant à l’institution d’explorer le potentiel du liage de données, de rejoindre des publics qui ne fréquentent pas de musées et de donner prise à une culture du réseau dans l’organisation. Nathalie Thibault, archiviste au MNBAQ, en mentionne les effets marquants:
Un des impacts positifs de ce chantier a été de bonifier la présence d’œuvres dans des collections d’autres musées au Québec et au Canada dans les articles bonifiés et non pas juste le MNBAQ. Nous souhaitons collaborer avec les autres musées du Québec, car les articles améliorés sur les artistes du Québec serviront certainement à d’autres institutions muséales.
***
En conclusion, il est souhaitable que nous ayons une alternative aux grandes plateformes pour développer nos compétences et mettre en valeur nos collections, catalogues, fonds et portfolios. Il faut cependant favoriser les initiatives qui ciblent des résultats marquants et transmissibles tels que la décentralisation des prises de décision, l’abolition des silos organisationnels et la mise en commun de données.
Produire des données : entre outils de marketing et bases de connaissances
La découverte optimisée pour les moteurs de recherche est-elle la seule solution pour accroître la consommation de contenus culturels locaux ? Sommes-nous à la recherche de nouveaux outils de marketing ou souhaitons-nous développer des bases de connaissances communes ? Les résultats attendus à court terme, par nos programmes et partenaires sectoriels, pèsent sur les choix qui orientent nos actions.
La découverte optimisée pour les moteurs de recherche
Google poursuit son évolution pour devenir notre principale interface d’accès à la connaissance. La tendance zéro clic est une forme de désintermédiation des répertoires qui est similaire à celle que connaissent les sites des médias. Il y a quelques années que les réseaux de veille prédisent la transition des moteurs de recherche vers des moteurs de réponse.
Alors, est-il stratégique de baliser nos pages web avec des métadonnées (aussi appelées données structurées) pour que des machines comprennent et utilisent nos contenus dans leurs fiches de réponse ?
Améliorer le potentiel d’une information d’être repérée et interprétée par un agent automatisé est une bonne pratique à intégrer dans toute conception web, au même titre que le référencement de site web. Mais se contenter de baliser des pages pour les seules fins de marketing et de visibilité n’est pas stratégique. Voici pourquoi:
- Architecture de l’information conçue pour servir des intérêts économiques et culturels spécifiques.
- Aucun contrôle sur le développement de la base de connaissances.
- Uniformité de la présentation de l’information, quel que soit le pays ou la culture.
- Modèle et vocabulaire descriptifs simples, mais adaptés à des offres commerciales (une bibliothèque publique est une entreprise locale).
- Le moteur de recherche n’utilise que certains éléments du vocabulaire Schema.org et modifie son traitement des balises au gré de ses objectifs commerciaux (voir ce billet sur les mythes et réalité de la découvrabilité).
Des données pour générer de la connaissance
Les plans de marketing et de promotion ont des effets à court terme, mais ponctuels, sur la découverte. Cependant, nous devons parallèlement développer les expertises nécessaires pour concevoir de nouveaux systèmes de mise en valeur des offres culturelles et de recommandation qui répondent à nos propres objectifs. Ne pas également prioriser cette avenue, c’est accumuler une dette numérique et accroître notre dépendance envers les plateformes et tout promoteur de solution.
Comme je l’ai souligné en conclusion d’un billet rédigé lors de recherches sur la découvrabilité et la « knowledge card » de Google, « , apprendre à documenter des contenus sous forme de données est une étape vers le dévelopement de « nos propres outils de découverte, de recommandation et de reconnaissance de ceux qui ont contribué à la création et à la production d’œuvres. »
Pour cela, il faut élaborer collectivement nos propres stratégies pour faire connaître le contenu de répertoires et rejoindre de nouveaux publics. Nous serions, alors, en mesure de concevoir des moyens non intrusifs pour collecter l’information qui permet de comprendre la consommation culturelle.
Adopter une méthode de travail pour une réflexion stratégique
Concevoir et réaliser des projets autour de données liées (ouvertes ou non) demande un long temps de réflexion et d’échanges de connaissances entre des acteurs qui ont des perspectives différentes. L’initiative de la Cinémathèque québécoise peut être citée comme un excellent exemple de transformation organisationnelle par l’adoption d’une nouvelle méthode de travail. Marina Gallet pilote ce projet qui vise à formaliser les savoirs communs du cinéma en données ouvertes et liées. Elle a gracieusement partagé cette expérience lors de la dernière édition du Colloque sur le web sémantique.
Représentation de la diversité culturelle et linguistique
Il existe de nombreuses façons de décrire les oeuvres d’un album de musique ou un spectacle de danse. Pour représenter ces descriptions sous forme de données, il existe des modèles et vocabulaires pour différentes missions et utilisateurs. Une part grandissante de ces vocabulaires est en données ouvertes et liées. Ces descriptions ne sont pas toujours structurées ou conformes aux standards du web, mais leur diversité est essentielle à la richesse de l’information. Il est vital que les vocabulaires utilisés pour décrire des offres et des contenus soient en français pour que la francophonie soit présente dans le web des données et qu’elle soit prise en compte par les systèmes intelligents.
Le Réseau canadien d’information sur le patrimoine annonçait ce printemps, la réalisation de la version française de référentiels en données ouvertes et liées. Philippe Michon, analyse pour le RCIP, explique comment ces référentiels essentiels au patrimoine culturel seront rendus disponibles en données ouvertes et liées.
Recherche augmentée: découverte selon les goût et l’expérience recherchée
Il faut cesser de reproduire des interfaces et modes d’accès aux répertoires qui sont dépassés. On ne peut cependant améliorer la découverte sans investir le temps et les efforts nécessaires pour sortir de nos vieilles habitudes de conception.
Nos interfaces de recherche sont devenues obsolètes dès l’arrivée du champ unique des premiers moteurs de recherche. Nos stratégies de marketing de contenu pour le référencement de pages web aident les moteurs de recherche à répondre à des questions, mais effacent les spécificités en uniformisant l’architecture de l’information.
L’information qui décrit nos productions culturelles et artistiques est trop souvent limitée à des données factuelles. Il faut annoter des descriptions avec des attributs et caractéristiques riches et orientés vers divers publics et usages. Des outils d’analyse et de recommandation peuvent ainsi fournir de l’information ayant une plus grande valeur. Il ne faudrait pas espérer refiler ce travail à des intelligences artificielles: l’indexation automatique ne produira pas nécessairement des métadonnées utiles et pertinentes pour une stratégie de valorisation. De plus, il ne faut pas sous estimer la valeur que l’expérience humaine (éditorialisation, sélection, critique, mise en contexte) apporte à des services qui jouent un rôle prescripteur.
Soutenir le dévelopement de bases de données en graphes
La mise en valeur de répertoires et collections, ainsi que des actifs informationnels (textes, images, sons) d’organisations ne devrait plus reposer sur des bases de données classiques. Les bases de données en graphes permettent de raisonner sur des données et de générer de la connaissance , en faisant des liens, à l’image de la pensée humaine:
Quelle est le parfum de glace préféré des personnes [qui] dégustent régulièrement des expresso, mais [qui] détestent les choux de Bruxelles ? Une base de donnée Graph peut vous le dire. Comment ? Avec des données de qualité, les bases de données Graph permettent de modéliser les données et de les stocker de la manière dont nous pensons et raisonnons dans le monde réel.
Ceci est tiré d’un bon article de vulgarisation sur les bases de données en graphe.
Choisir des méthodes de travail adaptées aux projets collectifs
Pour qu’un écosystème diversifié de connaissances (multidisciplinaire, multi acteurs) soit durable, il doit reposer sur la distribution des fonctions de production et de réutilisation des données entre des partenaires. Il faut aussi réunir des initiatives collectives dans une démarche où le développement de connaissances et l’expérimentation ne sont pas relégués au second plan par des intérêts individuels ou commerciaux. Enfin, il faut élaborer et adopter de nouvelles méthodes de travail pour des projets collectifs.
Je reviendrai bientôt sur les éléments nécessaire pour la gestion participative d’une base de connaissances commune.
Architectures et bases de connaissances
Définir les finalités et les modalités des projets de liage de données est un long cheminement qui demande des apprentissages, des efforts concertés et du temps. Nos programmes devraient être revus. Mettre en place les conditions de réussite d’un projet collectif est un projet en soi. Il faut tenir compte d’un cadre de formation, d’une nouvelle méthode de travail et d’une progression dans la durée. Exiger des résultats à court terme oriente les projets vers des « solutions » et laisse peu de place à la remise en question des habitudes.
Nos initiatives doivent être conjuguées pour élaborer une architecture commune de la connaissance. Parce qu’elle sort du cadre de nos actions habituelles, c’est une avenue qui offre plus de potentiel, à plusieurs titres, que des stratégies de visibilité et de marketing.

Trois enjeux communs pour les métadonnées en culture
Les métadonnées, en culture, servent à décrire des choses pour les rendre repérables et à faire des liens d’association entre des éléments d’information pour générer de nouvelles connaissances. Voici trois enjeux pour la création de métadonnées culturelles qui devraient être abordés de façon prioritaire, au sein des organismes, institutions, entreprises et regroupements associatifs.
1. Mise à niveau de nos systèmes d’information
La problématique des métadonnées en culture origine de la conception des systèmes d’information. La source de la plupart des problème se situe en amont des processus de gestion de l’information, soit lors de la saisie des données dans un un système ou un logiciel qui n’a pas été conçu pour générer des métadonnées interopérables. Il est également plus facile de convaincre des gestionnaires d’investir dans un nouveau site web que dans un modèle de métadonnées normalisées et interopérables pour lequel il est difficile de fixer des indicateurs de rendement.
Qualité des données
Plus de 60% du temps de travail des experts des données est consacré au nettoyage et à l’organisation des données. Il est possible de produire des données qui soient exploitables, plus facilement et à moindre coût, en mettant en application des principes de qualité inspirés, par exemple, de ceux qui guident la production de données ouvertes et liées pour l’Union européenne.
De la base de données au web de données
Au web des documents, s’est ajouté celui des données. Nous nous éveillons lentement à des modes de représentation et d’exploitation de l’information qui ne font plus référence à des pages, mais à des connaissances et à des ressources.
Dans le web, un contenu c’est de la donnée. Si les pages web s’adressant à des humains demeurent toujours utiles, ce sont les données décrivant des ressources (modèle Schema ou triplets du web sémantique) qui permettent à certaines technologies de classer et de relier l’information obtenue afin de nous fournir des réponses et, surtout, des suggestions.
Indexation de contenu et normalisation de données
Bien que des termes comme « métadonnées » et, même « web sémantique », se retrouvent désormais au programme de nombreux événements professionnels, au Québec et au Canada, trop rares sont les initiatives et projets où il est fait appel à des équipes pluridisciplinaires comme cela se fait au sein de gouvernements, d’institutions ou d’initiatives collectives, en Europe et aux États-Unis.
Est-il possible de réaliser des projets d’une complexité et d’une envergure que l’on peine à mesurer en dehors du cadre habituel d’un projet de développement technologique ? On peut en douter. Nous manquons de compétences en ce qui concerne la représentation de l’information sous forme de données liées, ainsi que sur les principes et méthodes de la documentation de ressources. Comment pourrions-nous, alors, atteindre des objectifs qui permettraient de tirer tous les avantages possibles des données qui décrivent nos contenus culturels ?
Plus concrètement, comment pourrions-nous entreprendre les démarches nécessaires à la réalisation d’objectifs similaires à ceux du projet DOREMUS qui réunit Radio France, Philharmonie de Paris et Bibliothèque nationale de France ?
«Permettre aux institutions culturelles, aux éditeurs
et distributeurs, aux communautés de passionnés
de disposer :
- de modèles de connaissance communs (ontologies)
- de référentiels partagés et multilingues
- de méthodes pour publier, partager, connecter, contextualiser, enrichir les catalogues d’œuvres et d’événements musicaux dans le web de données
Construire et valider les outils pédagogiques qui permettront le déploiement des standards, référentiels et technologies dans les institutions culturelles
Construire un outil d’assistance à la sélection d’œuvres
musicales.»
Il serait temps de moderniser les programmes de formation universitaire en bibliothéconomie et sciences de l’information et en technologies de l’information et d’encourager des intersections. Sans quoi, nous ne disposerons pas suffisamment de ressources compétentes pour passer du web des documents au web des données.
2. Décentralisation de la production de métadonnées
La centralisation de la production de métadonnées est contraire à la culture numérique car elle favorise généralement les perspectives et besoins d’une entité ou d’acteurs majoritaires. Les initiatives qui présentent le plus grand potentiel pour le développement de compétences en matière de production et réutilisation de données sont celles où les organismes sont appelés à participer activement à l’élaboration de leurs modèles de données, aux décisions en ce qui a trait à l’utilisation des données et à la conception de produits ou services. C’est par la pratique que les gestionnaires et entrepreneurs sont sensibilisés à l’utilité et à la valeur des données qu’ils produisent et qu’ils collectent.
Comme le signale Fred Cavazza, dans un récent billet, il nous faut réduire la dette numérique avant d’entreprendre une véritable transformation:
«Nommer un CDO, créer un incubateur, organiser un hackathon ou nouer un partenariat avec Google ou IBM ne vous aidera pas à vous transformer, au contraire, cela ne fera que reporter l’échéance. Il est donc essentiel de réduire la distance au numérique pour chaque collaborateur, et pas seulement les plus jeunes ou ceux qui sont directement impliqués dans un projet.»
À ce titre, externaliser l’indexation des ressources culturelles (production de métadonnées) ne saurait être considéré comme un choix stratégique dans une économie numérique puisqu’il éloigne les acteurs du traitement des données et les confine à des rôles de clients ou d’utilisateurs, sans opportunités d’apprentissage pratique. En effet, se pencher sur l’amélioration et la valorisation de données descriptives et de données d’usage est le meilleur moyen de développer une culture de la donnée et d’acquérir les connaissances qui permettent de transformer des pratiques et de se réinventer. En plus de responsabiliser les organismes et entreprises et d’assurer la découvrabilité numérique de leurs ressources, la décentralisation de la production de métadonnées renforce la résilience de l’écosystème; chacun des acteurs devenant un foyer potentiel de partage de connaissances et d’expérience.
3. Reconnaissance de la diversité des modèles de représentation
La centralisation de la production de métadonnées ne favorise pas la diversité des modèles de représentation et, plus spécifiquement, une réflexion post-colonialiste sur la description de productions culturelles et œuvres d’art, comme le lieu de fabrication ou la nationalité ou l’ethnie. Une démarche centralisée conduit à adopter un seul modèle de représentation des ressources, au détriment de la diversité des missions, des cultures, et des pratiques. Dans le domaine du patrimoine culturel, par exemple, il existe près d’une centaine de modèles de description différents. Tous ne conviennent pas à la production de données ouvertes et liées, mais il demeure que cette diversité des modèles est essentielle car elle répond à des besoins et contextes d’utilisation spécifiques.
C’est dans le même esprit, qui a permis au web de devenir ce qu’il est (voir « small pieces loosely joined » de David Weinberger, un des penseurs du web), qu’il faut s’entendre sur des principes et des éléments permettant de faire des relations entre différents modèles de métadonnées. Cette démarche comporte des enjeux de nature conceptuelle, technologique, voire même économiques et de politiques publiques. Face à un tel niveau de complexité, nous ne devrions pas tarder à rassembler, autour de ces enjeux, des spécialistes du développement d’ontologies et des questions d’interopérabilité des métadonnées.
*
Ce ne sont pas de nouveaux portails, plateformes et applications qui nous permettront de ne pas dépendre totalement d’entreprises se plaçant au-dessus des états eux-mêmes. Une « solution technologique » aussi extraordinaire soit-t-elle, ne remplace pas une vision et des stratégies. Surtout lorsque les modèles économiques, dont nous tentons d’imiter les interfaces sans en maîtriser le fonctionnement, reposent sur l’exploitation de données par des algorithmes et des technologies d’intelligence artificielle.
Que faire pour multiplier l’impact des initiatives numériques ?
Comment multiplier la portée des programmes de soutien à la transformation des organisations dans un contexte numérique ? En favorisant des initiatives qui ont pour objectifs des résultats durables et transmissibles à d’autres individus, organismes ou secteurs d’activités.
Ceux qui tirent la plus grande partie des bénéfices d’une économie numérique sont ceux qui en maîtrisent les concepts clés (collecte de données, organisation et classification de l’information, traitement algorithmique) et qui prennent les moyens pour profiter du réseau (contenu généré par les utilisateurs, mobilisation de capital intellectuel). Nous ne pouvons cependant pas tenter d’imiter des modèles qui ont nécessité des investissements colossaux et qui, après des années d’expérimentation, constituent des entités aussi riches et puissantes que des états. Mais nous ne devons pas non plus demeurer des fournisseurs de données et de contenus.
C’est pourquoi des programmes d’aide à la transformation numérique et à l’innovation, quel que soit le secteur d’activité, devraient permettre d’accroître de manière plus efficace nos connaissances en matière d’information numérisée , et de favoriser la collaboration entre organismes pour concevoir et expérimenter d’autres modèles de création de valeur.
Voici 3 notions qui sont essentielles pour sortir des vieux modèles :
1 – L’information avant les moyens technologiques
Découvrabilité, métadonnées, mise en commun de données, diffusion de contenu: bien avant d’être du développement logiciel ou la mise en place d’infrastructures, c’est un travail sur la définition et l’application de principes de traitement et d’organisation de l’information.
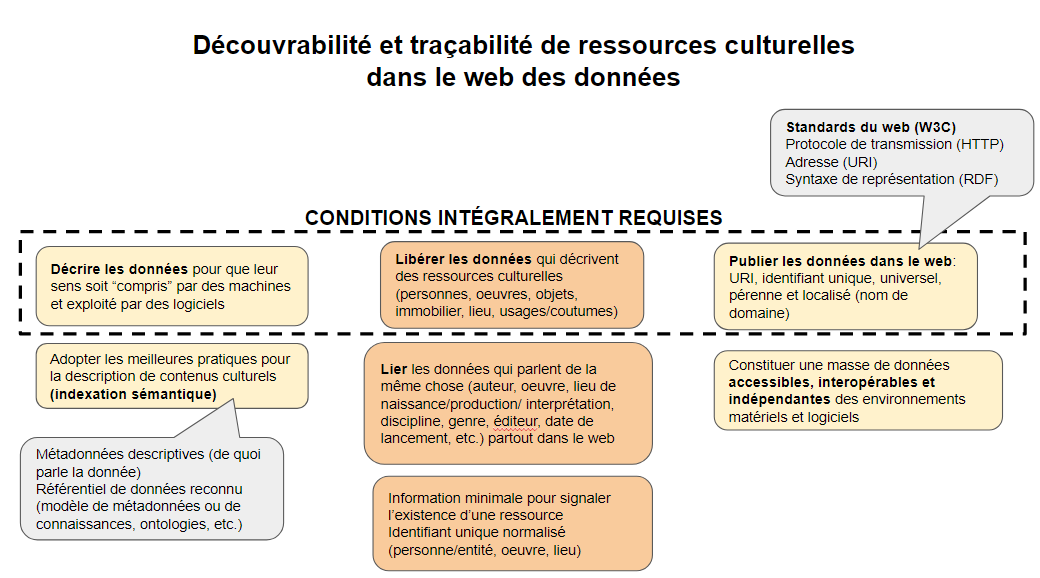
La mise en nombres binaires de l’information (soit des suites de 1 et de 0 qui représentent des caractères, puis des mots) est ce qui rend son traitement et sa transmission possibles par des machines. Par contre, pour que cette information numérisée puisse être repérable, « comprise » et exploitable par des machines qui sont, à présent, en quête de sens, il faut :
- Décrire les données pour qu’elles soient lisibles et utilisables pour des machines.
- Publier les données dans le web selon les standards du W3C pour les données ouvertes et liées (Linked Open Data).
De plus, pour rendre cette information découvrable dans le web, il faut préalablement réaliser une étape essentielle:
- Libérer les données qui décrivent des ressources (contenus culturels, patrimoine vivant et immatériel, produits, services, etc.).
2 – Les données comme actif plutôt que matière première
Nous souhaitons que les moteurs de recherche et autres types de technologie utilisés pour ratisser le web repèrent les données qui décrivent nos contenus, produits et services. Or, nous persistons à considérer la donnée comme une ressource alors que dans une économie numérique, il s’agit d’un actif. Cette nuance est extrêmement importante puisque cette ressource n’a de valeur que si elle est rare. Nous pourrions, par exemple, avoir à payer pour obtenir les données qui décrivent les titres d’un répertoire musical. Cependant, les données ne seraient donc pas repérables et accessibles pour les humains et les machines.
Considérer les données comme un actif permet de capitaliser sur la valeur de l’information qu’elles permettent de générer et sur le potentiel de découvrabilité qu’elles accordent aux contenus qu’elles décrivent.
3 – Travailler ensemble autour des données
Collaborer au sein d’une même organisation, à travers les disciplines ou entre organismes favorise l’émergence d’idées novatrices et permet de surmonter des problématiques complexes. Travailler sur des données en diversifiant les perspectives permet de générer de l’information utile pour divers objectifs, domaines d’activité et types d’utilisateurs. C’est pourquoi des initiatives qui sont mises en oeuvre par des équipes pluridisciplinaires ont de meilleures chances de succès.
Travailler ensemble sur la valorisation ou la mise en commun de données, que ce soit au sein d’un même organisme ou en partenariat avec d’autres organisations, requiert l’adoption de véritables méthodes collaboratives, notamment, pour que des enjeux relatifs à la gestion des données et au processus décisionnel ne viennent faire obstacle à l’atteinte des objectifs. En s’éloignant des dynamiques de contrôle et de subordination habituelles, il est possible d’instaurer un climat de confiance et la cohésion nécessaires à un travail collaboratif.
Un vrai modèle collaboratif n’est pas centralisateur: chacun des contributeurs d’un système de traitement ou de mutualisation de données est responsable de leur production et de leur qualité.. Ceci a pour effet d’assurer une gouvernance équilibrée du système et le transfert et développement de compétences au sein de chacune des organisations.
Pour cela, il faut apprendre à élaborer des démarches de projets qui fédèrent les participants autour d’un objectif commun tout en reconnaissant les bénéfices individuels et les limites de chacun. Ainsi, les initiatives et projets peuvent profiter du partage de connaissances au sein de réseaux internes et externes.
Pas d’évolution numérique sans maturité informationnelle
Voici la démarche des 5 étoiles du web des données, tel que conçue par Tim Berners-Lee et soutenu par les recommandations du W3C.
∗ Rendez vos données disponibles sur le Web (quel que soit leur format) en utilisant une licence ouverte.
** Rendez-les disponibles sous forme de données structurées (p. ex., en format Excel plutôt que sous forme d’image numérisée d’un tableau).
*** Utilisez des formats non exclusifs (p. ex., CSV plutôt que Excel).
**** Utilisez des URI pour identifier vos données afin que les autres utilisateurs puissent pointer vers elles.
***** Reliez vos données à d’autres données pour fournir un contexte. (Cote de degré d’ouverture des données, Gouvernement ouvert, Canada).
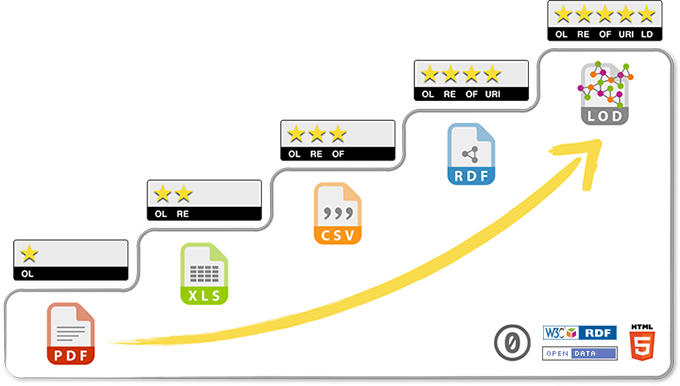
Voici l’échelle de la maturité informationnelle des organisations, telle qu’illustrée par Diane Mercier dans le cadre de sa thèse doctorale sur le web sémantique et la maturité informationnelle des organisations.
Thèse doctorale et références : Web sémantique et maturité organisationnelle sur Zotero.

Ces deux modèles participent de la même démarche graduelle et progressive vers l’ouverture et la participation, grâce à l’adoption de principes communs. C’est cette transformation que des initiatives numériques devraient permettre d’amorcer pour le bénéfice d’organismes et entreprises et, plus largement, pour la résilience d’un secteur d’activité ou d’un écosystème.
Déclaration des communs numériques pour un Québec postindustriel
Il n’est pas minuit moins cinq, nous avons dépassé minuit. C’est fait !
/…/ Nous allons vivre dans un monde postaméricain, postInternet, post néolibéral et postmoderne, Michel Cartier
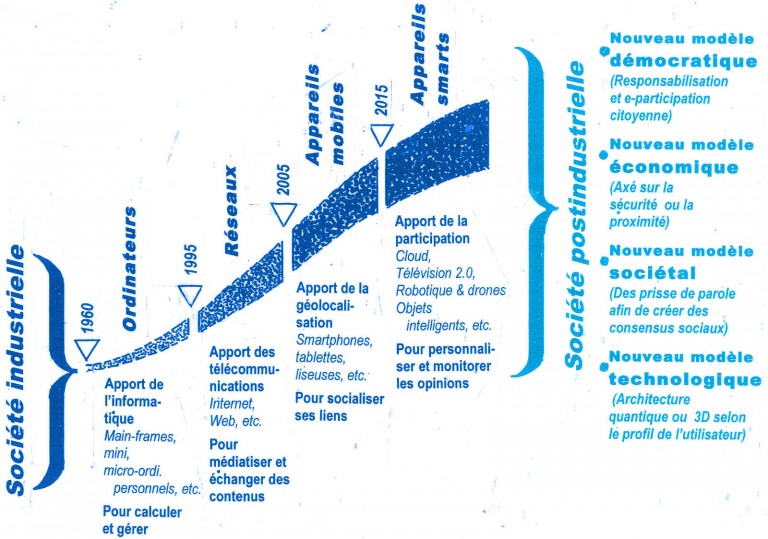
Dans Le 21e siècle, Michel Cartier réalise une extraordinaire synthèse des mutations que nous traversons, Bien plus qu’une révolution technologique, c’est un véritable changement de société qui s’est amorcé. Et il se fera avec ou contre nous.
C’est dans cette perspective que près d’une vingtaine d’associations, collectifs, entreprises et organismes sans but lucratif, qui jouent un rôle actif dans l’écosystème numérique québécois, s’unissent pour signer une Déclaration des communs numériques dans le cadre du processus de consultation de la Stratégie numérique du Québec.
La Déclaration affirme l’urgence de remettre le numérique au service de l’humain, de ses capacités fondamentales et des biens communs afin d’améliorer la vie des gens et de soutenir une démocratie plus inclusive.
Démarche de cocréation et processus itératif
FACIL et les collaborateurs du Café des savoirs libres se sont proposés d’inviter divers associations, collectifs, entreprises et organismes sans but lucratif à participer à la cocréation d’une déclaration commune plutôt que de contribuer individuellement à la consultation gouvernementale. Le 12 novembre 2016, lors d’une première rencontre, à Montréal, à la bibliothèque Mordecai Richler, les participants se sont entendus sur des principes généraux plutôt que sur des moyens, afin de rassembler des signataires partageant les mêmes préoccupations. La démarche se veut itérative et ouverte aux regroupements et associations qui se reconnaîtront dans cette déclaration ou qui souhaiteraient s’en inspirer pour élaborer leur propre document.
Les signataires de la Déclaration croient :
- Que le gouvernement doit s’assurer que les citoyen.ne.s et les membres de la société civile soient davantage engagé.e.s dans l’élaboration de cette Stratégie du numérique qui a des implications dans la fabrique de leur vie aujourd’hui et demain;
- Que le gouvernement se doit d’être exemplaire en s’engageant à amorcer en son sein les changements organisationnels et culturels requis afin de moderniser l’État, de s’ouvrir à la démocratie participative et d’améliorer les services aux citoyens (dépoussiérons le rapport Gouverner ensemble, présenté en 2012 par Henri-François Gautrin , alors député de Verdun et leader parlementaire adjoint du gouvernement);
- Que de nombreuses voix n’auront pas eu les moyens et les capacités d’être entendues et
- Que des questions fondamentales n’auront pas été posées et discutées à travers la méthode de consultation actuelle.
La Déclaration soulève certaines d’entre elles.
Lire la Déclaration des communs numériques (PDF, 56 Ko)

Stratégie numérique pour le Québec: sur les modèles d’une nouvelle économie

Mes contributions, dans le cadre de la consultation sur la stratégie numérique du Ministère de l’Économie, de la Science et de l’Innovation du Québec. Celles-ci témoignent de ma perspective, qui est essentiellement orientée vers les sciences de l’information. Et c’est d’une pluralité de regards et d’expertises sur les enjeux des transformations en cours dont nos dirigeants ont besoin.
C’est malheureusement, pour ceux et celles qui souhaiteraient offrir autre chose qu’une liste de souhaits, une démarche qui appartient plus à la réalisation d’une étude de marché qu’à un processus structuré d’écoute pour enrichir une réflexion (décision?) gouvernementale. Voici mes contributions fournies en quatre temps, compte tenu de l’espace accordé, mais qui sont ici, allongées de quelques mots afin d’en préciser le sens.
Économie numérique 1/4 – Les modèles
Des modèles d’affaires centrés sur l’exploitation de l’information: la donnée a plus de valeur que le produit qu’elle décrit et l’exploitation de données est plus rentable que la production de ressources. Nous n’avons pas de culture de la donnée (absence de normalisation et d’interopérabilité des bases de données, au sein d’un même système d’information et entre organisations apparentées).
Économie numérique 2/4 – Les données
Les données de nos BD sont inexploitables dans le web (normalisation, interopérabilité, sémantique) parce que nous concevons des systèmes sans penser à générer de l’information pour qu’elle soit largement diffusée. Nous formons des professionnels compétents mais nous les confinons à la gestion de bibliothèques.
Économie numérique 3/4 – Les compétences
Nous sommes mal équipés pour comprendre et réagir rapidement aux changements en cours. Nous passons du web des documents au web des données. Nous risquons d’être mis hors jeu par des joueurs qui participent à l’élaboration des règles que nous ne maîtrisons pas, alors que nous focalisons sur le développement d’outils.
Économie numérique 4/4 – Le web des données
La capacité de découvrabilité de nos produits dépend de plateformes étrangères qui, elles, s’enrichissent avec l’exploitation des données que nous générons. Allons-nous continuer à soutenir le développement de silos de données ou apprendre les changements qui sont à l’oeuvre dans le web et à quoi servent des métadonnées?
Fablabs en bibliothèques: documenter une démarche de cocréation

Par leur mission, les bibliothèques contribuent au réseau des communs (voir la définition à la fin de ce billet), ces ressources partagées qui permettent à chacun de créer de la valeur. Comment peuvent-elles se transformer afin d’accompagner leurs différents publics pour qu’ils puissent développer leur potentiel créatif ?
Alors que ces lieux et la profession même de bibliothécaire se transforment, les fablabs, ces laboratoires de fabrication ouverts au public, deviennent des terrains d’expérimentation de choix pour actualiser la fonction de médiation. Mais comment mutualiser les apprentissages et connaissances pour permettre à d’autres bibliothèques et, par extension, de nombreux citoyens, de faire cette expérience ? C’est sur ce sujet qu’une activité a été offerte dans le cadre de la Semaine québécoise de l’informatique libre (SQIL), en septembre dernier.
Proposée par le Café des savoirs libres (dernière mutation du collectif informel Bookcamp Montréal) et organisée par la Ville de Montréal (direction des bibliothèques publiques), cette activité réunissait des bibliothécaires et des représentants de fablabs québécois dont Monique Chartrand (Communautique).
Bibliothèques et fablabs: mode d’emploi des communs
Documenter une activité est une forme de reconnaissance offerte à ceux et celles qui ont donné de leur temps et partagé leurs connaissances. C’est également une information qui pourrait être partagée avec les citoyens qui sont concernés par ces services, ainsi qu’avec d’autres contributeurs potentiels.
Cahier des participants
Retour sur l’activité de cocréation: scénario, projets choisis, liste des participants, références utiles.
Cartographie collective des fablabs
État des lieux des fablabs en bibliothèques, au Québec: tableau à compléter.
Projet de collaboration professionnelle
Le Wiki Fabs labs Québec fera une place spéciale aux bibliothèques. Ce projet a pour cofondateur Guillaume Coulombe, qui maîtrise le wiki sémantique et qui a également réalisé une encyclopédie du violon traditionnel québécois.
Documenter pour faciliter la réutilisation
Voilà qui mérite d’être souligné: un excellent travail de documentation d’une démarche de cocréation. Une habitude à développer par tous les organisateurs d’activités participatives pour lesquelles on attend un résultat: cocréation, hackathon, maker space et même si ne n’est plus tendance, quelquechose-camp. (si vous n’êtes pas familier avec ce vocabulaire, lire Viens dans mon tiers-lieu, j’organise un hackathon en open source).
Documenter le déroulement d’une activité (scénario), la contribution des participants, les enjeux et propositions formulés, ainsi que, le cas échéant, les engagements pris est un le meilleur moyen pour obtenir des résultats concrets. C’est un effort indispensable pour partager plus largement, mobiliser et, surtout, préparer le passage à l’action.
Les communs, qu’est-ce c’est ?
Valérie Peugeot, présidente de Vecam, une organisation qui milite pour une appropriation des pratiques numériques par les citoyens, explique très clairement, en deux minutes, ce que sont les communs dans cette vidéo. Madame Peugeot a également participé, en présentiel, à la conférence sur les communs numériques.
{kind=link}
La donnée est l’élément pivot d’une nouvelle politique culturelle
Nos contenus culturels sont-ils dans le web des données ?
Mémoire déposé dans le cadre de la consultation publique pour le renouvellement de la politique culturelle du Québec, 8 mai 2016.

Parmi tous les documents publiés — tant par les gouvernements du Québec et du Canada que par les institutions et organismes préoccupés par le nécessaire renouvellement d’une politique culturelle dans un contexte de transition numérique — il n’est fait aucune mention de la donnée. Celle-ci est pourtant au cœur du « numérique » (peu importe la définition choisie) si bien qu’il est impossible d’élaborer une vision, une politique et des programmes qui soient cohérents et qui aient un impact réel et de longue durée sans une compréhension fine de ce dont il s’agit.
Comprendre la donnée, c’est être en mesure de répondre à la plupart des questions qui se trouvent sous les sept thèmes du document de consultation et, de manière plus générale, à celles-ci :
- Quels sont les éléments fondamentaux sur lesquels il faut agir pour que la politique culturelle fasse émerger des projets et actions ayant un impact transformateur et durable sur l’économie de la culture?
- Que devrait-on retenir des orientations qui façonnent les stratégies et les programmes d’états ayant une structure de soutien similaire à celle du Québec?
- Comment des programmes peuvent-ils avoir une portée transversale sur les trois principaux axes de la politique que sont :
(1) l’affirmation de l’identité culturelle,
(2) le soutien aux créateurs et aux arts et
(3) l’accès et la participation des citoyens à la vie culturelle?
Ces questions ont orienté la rédaction de ce mémoire. Celui-ci a été rédigé à partir d’un rapport-synthèse réalisé à la demande de la SODEC afin de dégager les éléments essentiels à son appréhension du contexte au sein duquel les créateurs et entreprises culturelles vivent désormais. Lire le mémoire