La découverte optimisée pour les moteurs de recherche est-elle la seule solution pour accroître la consommation de contenus culturels locaux ? Sommes-nous à la recherche de nouveaux outils de marketing ou souhaitons-nous développer des bases de connaissances communes ? Les résultats attendus à court terme, par nos programmes et partenaires sectoriels, pèsent sur les choix qui orientent nos actions.
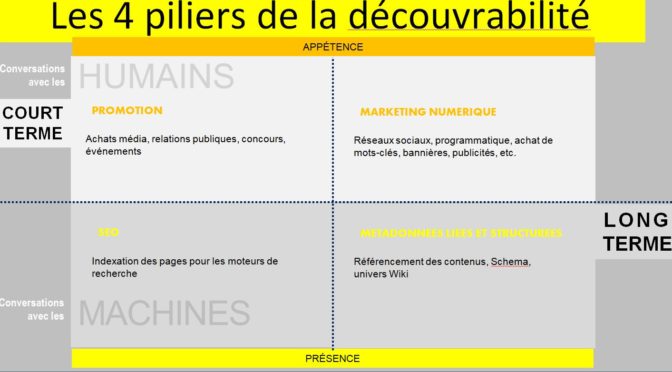
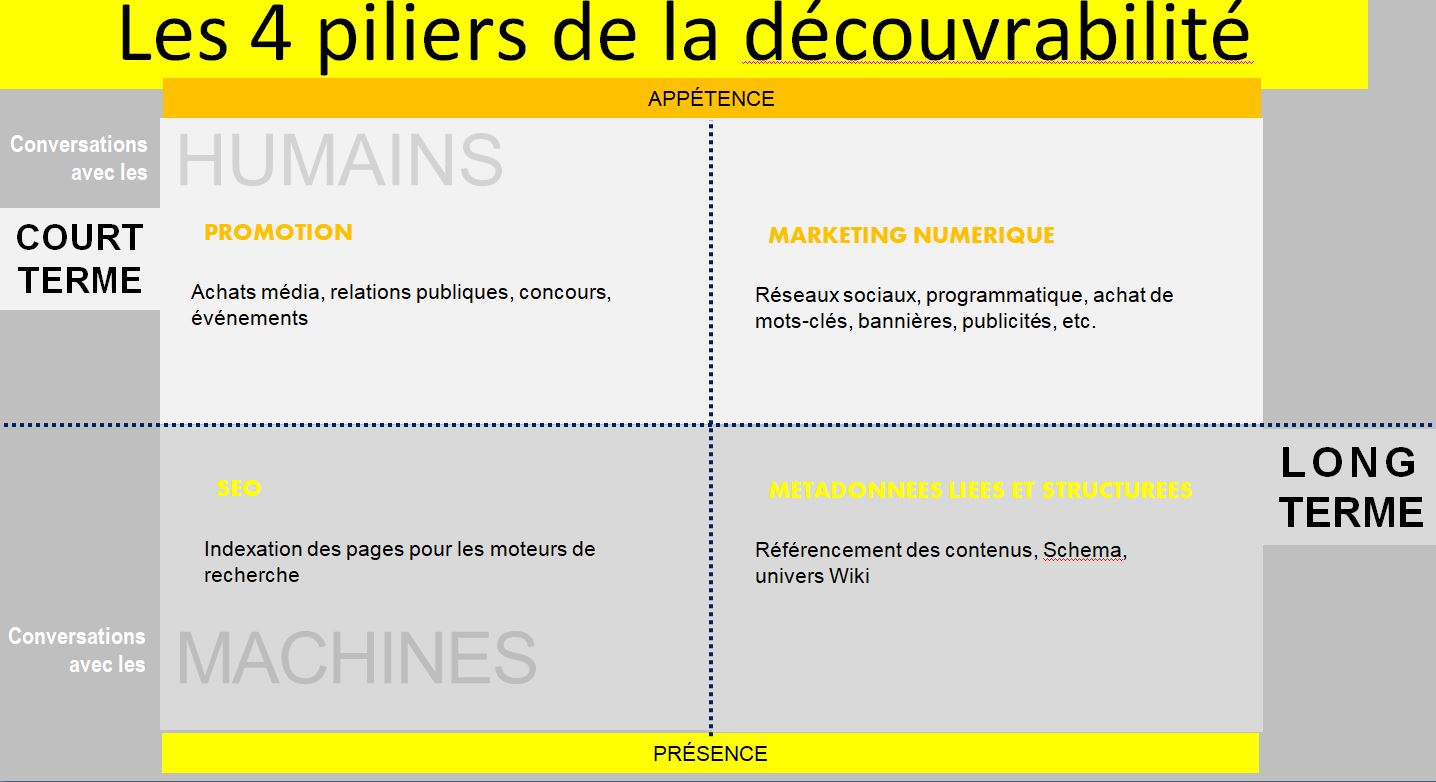
La découverte optimisée pour les moteurs de recherche
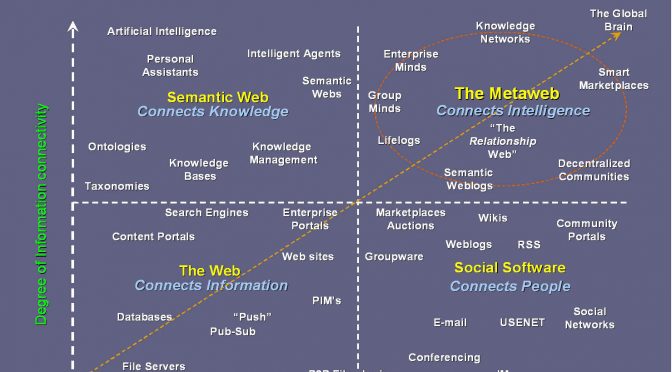
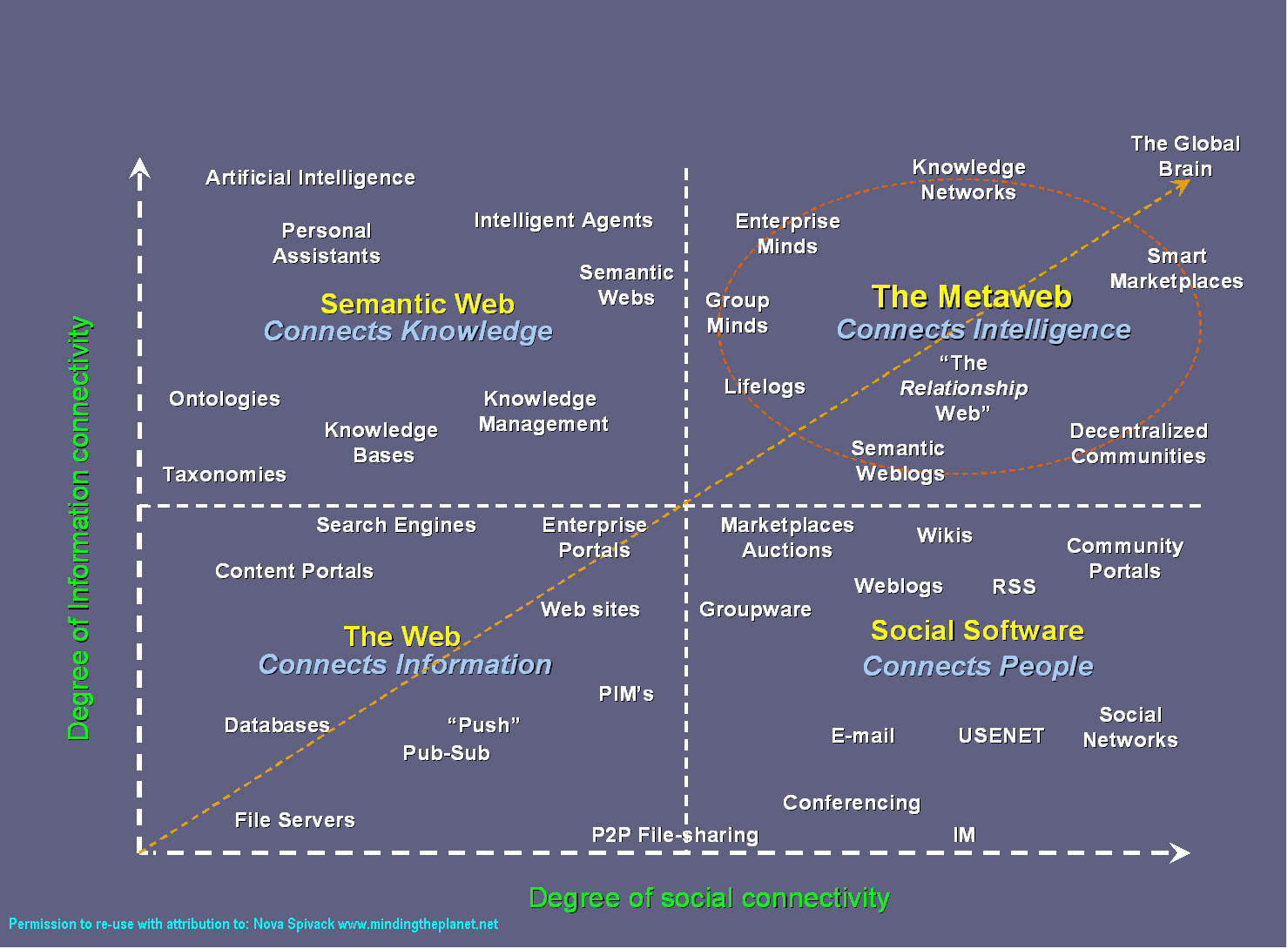
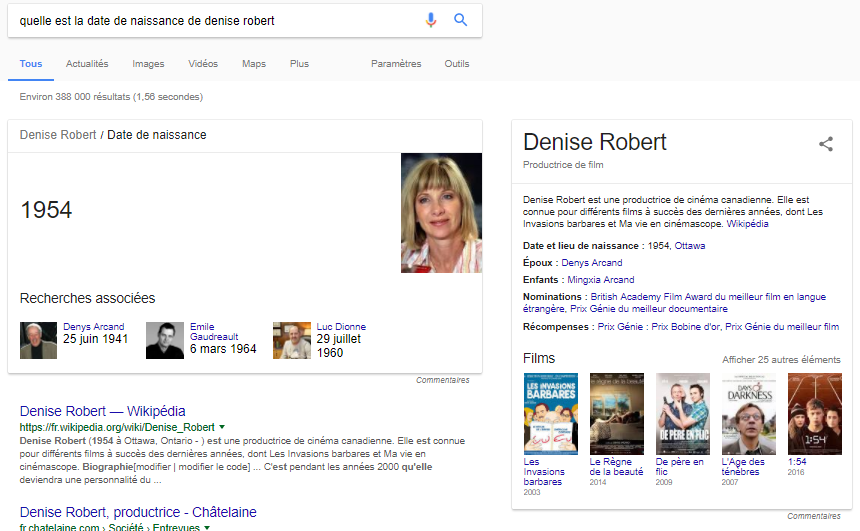
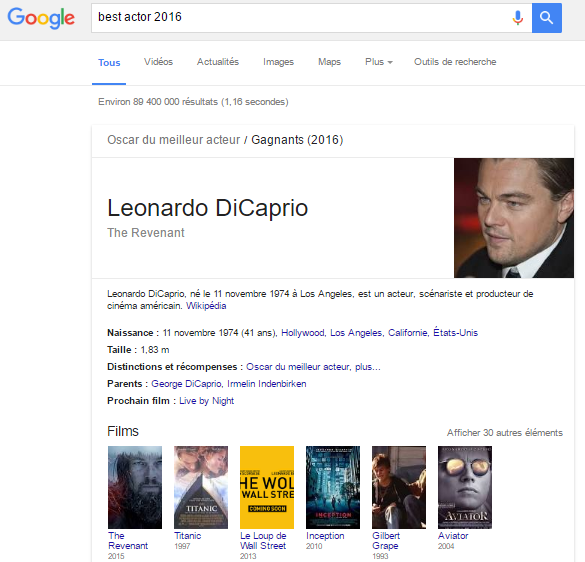
Google poursuit son évolution pour devenir notre principale interface d’accès à la connaissance. La tendance zéro clic est une forme de désintermédiation des répertoires qui est similaire à celle que connaissent les sites des médias. Il y a quelques années que les réseaux de veille prédisent la transition des moteurs de recherche vers des moteurs de réponse.
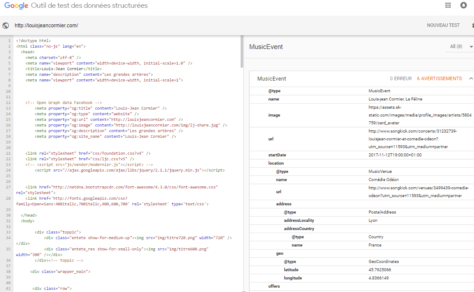
Alors, est-il stratégique de baliser nos pages web avec des métadonnées (aussi appelées données structurées) pour que des machines comprennent et utilisent nos contenus dans leurs fiches de réponse ?
Améliorer le potentiel d’une information d’être repérée et interprétée par un agent automatisé est une bonne pratique à intégrer dans toute conception web, au même titre que le référencement de site web. Mais se contenter de baliser des pages pour les seules fins de marketing et de visibilité n’est pas stratégique. Voici pourquoi:
- Architecture de l’information conçue pour servir des intérêts économiques et culturels spécifiques.
- Aucun contrôle sur le développement de la base de connaissances.
- Uniformité de la présentation de l’information, quel que soit le pays ou la culture.
- Modèle et vocabulaire descriptifs simples, mais adaptés à des offres commerciales (une bibliothèque publique est une entreprise locale).
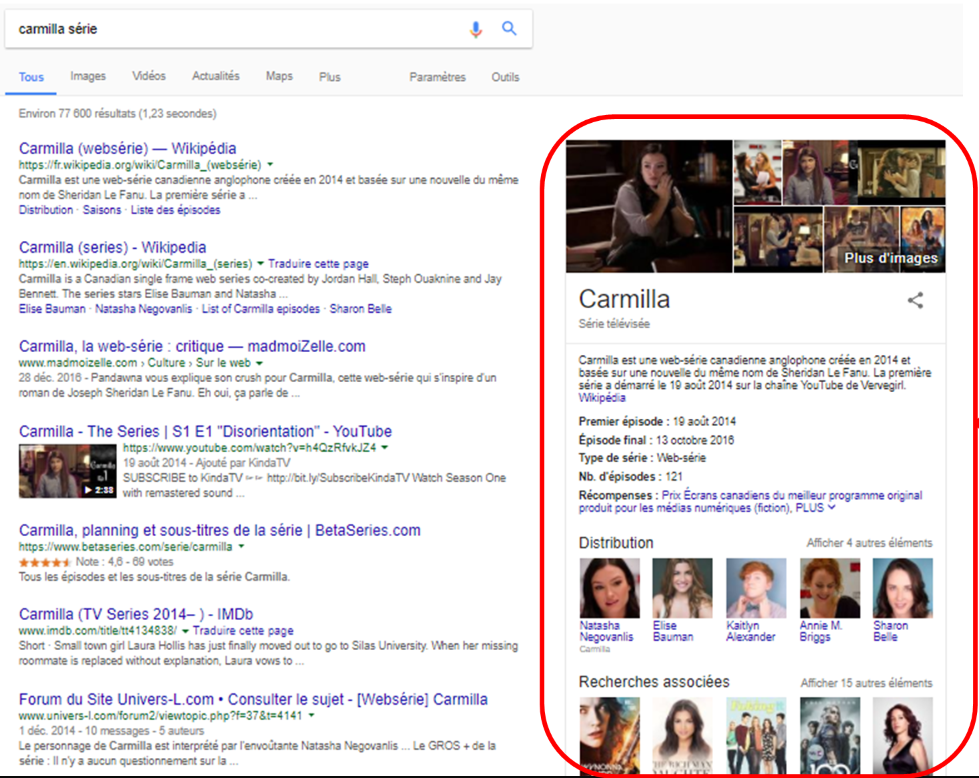
- Le moteur de recherche n’utilise que certains éléments du vocabulaire Schema.org et modifie son traitement des balises au gré de ses objectifs commerciaux (voir ce billet sur les mythes et réalité de la découvrabilité).
Des données pour générer de la connaissance
Les plans de marketing et de promotion ont des effets à court terme, mais ponctuels, sur la découverte. Cependant, nous devons parallèlement développer les expertises nécessaires pour concevoir de nouveaux systèmes de mise en valeur des offres culturelles et de recommandation qui répondent à nos propres objectifs. Ne pas également prioriser cette avenue, c’est accumuler une dette numérique et accroître notre dépendance envers les plateformes et tout promoteur de solution.
Comme je l’ai souligné en conclusion d’un billet rédigé lors de recherches sur la découvrabilité et la « knowledge card » de Google, « , apprendre à documenter des contenus sous forme de données est une étape vers le dévelopement de « nos propres outils de découverte, de recommandation et de reconnaissance de ceux qui ont contribué à la création et à la production d’œuvres. »
Pour cela, il faut élaborer collectivement nos propres stratégies pour faire connaître le contenu de répertoires et rejoindre de nouveaux publics. Nous serions, alors, en mesure de concevoir des moyens non intrusifs pour collecter l’information qui permet de comprendre la consommation culturelle.
Adopter une méthode de travail pour une réflexion stratégique
Concevoir et réaliser des projets autour de données liées (ouvertes ou non) demande un long temps de réflexion et d’échanges de connaissances entre des acteurs qui ont des perspectives différentes. L’initiative de la Cinémathèque québécoise peut être citée comme un excellent exemple de transformation organisationnelle par l’adoption d’une nouvelle méthode de travail. Marina Gallet pilote ce projet qui vise à formaliser les savoirs communs du cinéma en données ouvertes et liées. Elle a gracieusement partagé cette expérience lors de la dernière édition du Colloque sur le web sémantique.
Représentation de la diversité culturelle et linguistique
Il existe de nombreuses façons de décrire les oeuvres d’un album de musique ou un spectacle de danse. Pour représenter ces descriptions sous forme de données, il existe des modèles et vocabulaires pour différentes missions et utilisateurs. Une part grandissante de ces vocabulaires est en données ouvertes et liées. Ces descriptions ne sont pas toujours structurées ou conformes aux standards du web, mais leur diversité est essentielle à la richesse de l’information. Il est vital que les vocabulaires utilisés pour décrire des offres et des contenus soient en français pour que la francophonie soit présente dans le web des données et qu’elle soit prise en compte par les systèmes intelligents.
Le Réseau canadien d’information sur le patrimoine annonçait ce printemps, la réalisation de la version française de référentiels en données ouvertes et liées. Philippe Michon, analyse pour le RCIP, explique comment ces référentiels essentiels au patrimoine culturel seront rendus disponibles en données ouvertes et liées.
Recherche augmentée: découverte selon les goût et l’expérience recherchée
Il faut cesser de reproduire des interfaces et modes d’accès aux répertoires qui sont dépassés. On ne peut cependant améliorer la découverte sans investir le temps et les efforts nécessaires pour sortir de nos vieilles habitudes de conception.
Nos interfaces de recherche sont devenues obsolètes dès l’arrivée du champ unique des premiers moteurs de recherche. Nos stratégies de marketing de contenu pour le référencement de pages web aident les moteurs de recherche à répondre à des questions, mais effacent les spécificités en uniformisant l’architecture de l’information.
L’information qui décrit nos productions culturelles et artistiques est trop souvent limitée à des données factuelles. Il faut annoter des descriptions avec des attributs et caractéristiques riches et orientés vers divers publics et usages. Des outils d’analyse et de recommandation peuvent ainsi fournir de l’information ayant une plus grande valeur. Il ne faudrait pas espérer refiler ce travail à des intelligences artificielles: l’indexation automatique ne produira pas nécessairement des métadonnées utiles et pertinentes pour une stratégie de valorisation. De plus, il ne faut pas sous estimer la valeur que l’expérience humaine (éditorialisation, sélection, critique, mise en contexte) apporte à des services qui jouent un rôle prescripteur.
Soutenir le dévelopement de bases de données en graphes
La mise en valeur de répertoires et collections, ainsi que des actifs informationnels (textes, images, sons) d’organisations ne devrait plus reposer sur des bases de données classiques. Les bases de données en graphes permettent de raisonner sur des données et de générer de la connaissance , en faisant des liens, à l’image de la pensée humaine:
Quelle est le parfum de glace préféré des personnes [qui] dégustent régulièrement des expresso, mais [qui] détestent les choux de Bruxelles ? Une base de donnée Graph peut vous le dire. Comment ? Avec des données de qualité, les bases de données Graph permettent de modéliser les données et de les stocker de la manière dont nous pensons et raisonnons dans le monde réel.
Ceci est tiré d’un bon article de vulgarisation sur les bases de données en graphe.
Choisir des méthodes de travail adaptées aux projets collectifs
Pour qu’un écosystème diversifié de connaissances (multidisciplinaire, multi acteurs) soit durable, il doit reposer sur la distribution des fonctions de production et de réutilisation des données entre des partenaires. Il faut aussi réunir des initiatives collectives dans une démarche où le développement de connaissances et l’expérimentation ne sont pas relégués au second plan par des intérêts individuels ou commerciaux. Enfin, il faut élaborer et adopter de nouvelles méthodes de travail pour des projets collectifs.
Je reviendrai bientôt sur les éléments nécessaire pour la gestion participative d’une base de connaissances commune.
Architectures et bases de connaissances
Définir les finalités et les modalités des projets de liage de données est un long cheminement qui demande des apprentissages, des efforts concertés et du temps. Nos programmes devraient être revus. Mettre en place les conditions de réussite d’un projet collectif est un projet en soi. Il faut tenir compte d’un cadre de formation, d’une nouvelle méthode de travail et d’une progression dans la durée. Exiger des résultats à court terme oriente les projets vers des « solutions » et laisse peu de place à la remise en question des habitudes.
Nos initiatives doivent être conjuguées pour élaborer une architecture commune de la connaissance. Parce qu’elle sort du cadre de nos actions habituelles, c’est une avenue qui offre plus de potentiel, à plusieurs titres, que des stratégies de visibilité et de marketing.