En culture comme en commerce, les initiatives de mise en commun de données numériques, constituent de nouveaux « milieux documentaires ». Au Québec, pourtant, les compétences et méthodes du domaine des sciences de l’information sont rarement sollicitées. Les institutions d’enseignement et les associations professionnelles concernées devraient pourtant reconnaître, dans ces projets, les notions et enjeux entourant les systèmes documentaires classiques.
Continuer la lecture de Nouveaux milieux documentaires en manque de spécialistes des sciences de l’informationArchives par mot-clé : gestion de la connaissance

Découvertes culturelles: au-delà du marketing et du techno-solutionnisme

Notre focalisation sur le marketing et les solutions technologiques est-elle un risque pour la diversité culturelle ? L’absence de vision partagée et la course aux résultats peuvent-elles faire perdre aux acteurs de la culture la maîtrise stratégique des choix en matière de diffusion et d’accès ?
Nous espérons des solutions mécanistes qui accroîtront la consommation en imposant des offres culturelles à la façon des vieux modèles publicitaires. La mise en données de contenus culturels ne doit pas nous faire oublier qu’il appartient à chacun de réaliser la partie la plus stratégique d’un projet numérique : décider de la façon dont une chose (une œuvre, par exemple) doit être documentée et déterminer ce qui la relie à d’autres informations dans le web des données.
L’emploi du mot « initiative », de préférence à « projet », souligne l’importance de la démarche et des apprentissages, par rapport à la livraison d’un outil ou la modernisation d’un système. Voici comment nos initiatives pourraient être plus marquantes.
Miser sur l’éducation et l’accès à la culture
Le marketing peut entraîner la consommation de produits et services culturels, mais ce sont l’éducation et l’accès à la culture qui peuvent faire découvrir et apprécier la culture. Or, il faudrait une plus grande porosité entre les politiques et projets éducatifs et culturels pour miser sur l’environnement familial et social pour faire connaître la culture.
Il faudrait également donner un rôle plus actif, dans nos plans et initiatives numériques, aux médiateurs de proximité que sont les professionnels des bibliothèques publiques et scolaires.
Privilégier les initiatives qui favorisent la diversité
Nous cherchons, par tous les moyens, à ce que la culture locale soit vue et consommée, de préférence à d’autres offres. Nos propositions techniques partagent cependant les défauts des plateformes dominantes. Qu’il s’agisse de baliser des contenus pour les moteurs de recherche ou de créer de nouvelles bases de données interrogeables, la façon dont sont conçues ces « solutions » technologiques nuit à la diversité des offres culturelles.
- La centralisation des décisions et du traitement de l’information renforce l’uniformisation.
- La popularité comme principal critère de sélection défavorise les contenus de niche, les cultures et langues en situation minoritaire dans un répertoire, sur un territoire ou par rapport au reste du monde.
- L’uniformisation du traitement documentaire, par l’imposition d’une méthode de classification, de vocabulaires et de référentiels spécifiques, appauvrit la qualité de l’information. Par conséquent, elle en diminue l’intérêt et la valeur pour différents publics. Les initiatives de décolonisation des modèles descriptifs tentent de réparer les ravages du rouleau compresseur de l’uniformisation sur la citoyenneté culturelle des peuples autochtones.
- Les systèmes de recommandations et de personnalisation des offres culturelles reposent sur la similarité des produits et services ou sur la similarité des profils des utilisateurs.
Ne pas céder des choix stratégiques
À l’arrivée de l’informatique, nous avons confié l’organisation de l’information à des systèmes de bases de données, selon les termes d’entreprises. Il est temps de remettre, selon nos propres termes, cette intelligence dans nos sites web et, plus spécifiquement, dans nos catalogues, collections, répertoires, fonds et archives. Nous ne devrions pas abandonner la création de sens et de liens à des opérateurs de plateformes et à des fournisseurs de services.
Être trouvé ou découvert et laisser des traces numériques sont les fruits d’un travail de documentation. Celui-ci est trop souvent escamoté par la recherche d’une solution technologique. De plus, les façons de décrire des productions ou des offres culturelles offrent peu de possibilité de mettre celles-ci en relation avec des intérêts et des passions.
Par exemple, les catalogues et répertoires en ligne pourraient grandement améliorer l’expérience des utilisateurs en devenant des bases de connaissances interactives et interconnectées. Il serait ainsi possible d’intégrer de nouvelles informations et des liens vers d’autres ressources grâce aux contributions de chercheurs et d’amateurs.
Documenter: laisser des traces, créer du lien et faire sa marque
Documenter la culture et rendre cette information pertinente, attrayante et utile pour divers publics et usages sont la responsabilité de tous les acteurs du milieu culturel. Il manque une méthode de travail et des outils faciles à utiliser pour réaliser, en équipe ou avec des partenaires, l’évaluation de l’information publiée sur le web et le choix des métadonnées qui feront des liens entre les offres culturelles et les publics cibles.
C’est dans cette perspective qu’a été conçu un guide destiné aux artistes et aux organisations du milieu de la danse. Cette approche, en trois étapes (stratégie, information, technologie) repousse les choix technologiques à la toute dernière étape afin de remettre la documentation de la danse à ceux et celles qui la font.
Extraits du lancement du guide Bien documenter pour favoriser la découverte en ligne, réalisé pour la Fondation Jean-Pierre Perreault, dans le cadre de l’initiative La danse dans le web des données.
Le journalisme d’enquête et le graphe de connaissances de Google
Google annonce un changement à son algorithme afin de promouvoir le journalisme d’enquête.
Mais ceci servira surtout à améliorer la quantité de données contenues dans son graphe de connaissances (knowledge graph) et d’étendre son influence sur ce que nous voyons sur le web.
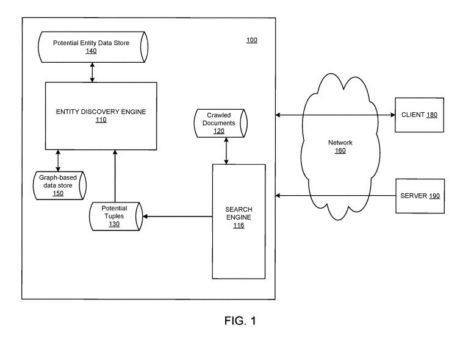
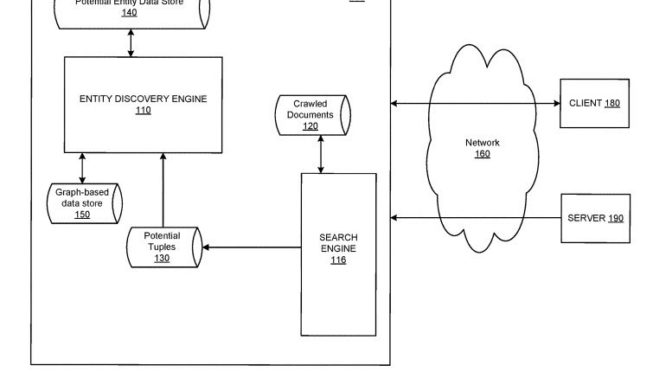
Bill Slawski est un spécialiste de l’optimisation pour moteurs de recherche. Sa formation de juriste lui permet de porte une attention particulière aux demandes de brevet. Il en commentait une, récemment, qui fait référence au développement du graphe de connaissances (knowledge graph) de Google. Elle concerne l’intégration, dans son graphe, d’information collectée sur le web, afin d’accroître la masse de données :
The patent points out at one place, that human evaluators may review additions to a knowledge graph. It is interesting seeing how it can use sources such as news sources to add new entities and facts about those entities.
Comme chez les autres entreprises dont le modèle d’affaires repose sur la donnée, une grande partie du traitement de l’information et de la production de données résulte du travail non rémunéré d’amateurs et passionnés:
How can you teach an algorithm to understand all these distinctions? Gingras said Google is doing so through its Quality Raters, a global network of more than 10,000 individuals who offer feedback on Google’s search results, which in turn is used to improve the company’s search algorithms.
Google says it will do more to prioritize original reporting in search
Ceci sert-il les intérêts du journalisme ? Probablement, mais il est trop tôt pour le vérifier. Cela sert surtout à développer une connaissance très poussée de nos rapports à l’information et de permettre à d’autres d’influencer notre vision du monde et de fabriquer des opinions. S’informer sur le scandale Facebook – Cambridge Analytica devrait nous faire prendre la mesure de l’intervention de ces systèmes dans notre développement social, notamment, la fabrication d’opinions et d’antagonismes.
À quelles questions répondent vos (méta)données ?
Mise à jour 2019-09-07: ajout, à la fin du billet, d’information concernant les cas d’usage, suite à un commentaire exprimé sur Facebook.
Produire et réutiliser des données descriptives, ce n’est pas travailler sur une solution, mais sur des questions.
Quelle est la finalité du projet ?
Comment savoir si les données d’une organisation ou d’un collectif ont un fort potentiel informationnel ? Comment ces données peuvent-elles répondre à des questions qui demandent de faire des liens entre des entités et d’interpréter des relations ? Si ces données ne sont pas suffisamment riches en information, comment les lier avec celles provenant d’autres sources, ouvertes et privées, pour les valoriser ?
La finalité de projets de données est de générer l’information la plus riche afin de répondre à des questions à la satisfaction des publics cibles. Toute initiative devrait donc débuter par un diagnostic de la disponibilité et de la qualité des données. Cependant, comment effectuer un tel exercice sans savoir à quels besoins répondront-elles ou, plus exactement, à quelles questions devront-elles répondre ?
Trouver les bonnes questions: la dimension cognitive des projets
La dimension cognitive des projets numériques se rapporte à la sélection, l’organisation et le traitement de l’information. Ces activités doivent réunir des perspectives et compétences diversifiées: de la connaissance du domaine et des publics à la modélisation de l’information. Il s’agit d’un travail collaboratif qui doit être réalisé en amont de la conception technique. Cette étape est rarement bien planifiée et réalisée, faute de budget, ressources ou méthode de travail. Pourtant, elle constitue le coeur du projet. C’est, de plus, un processus qui permet d’améliorer la littératie numérique et développer des pratiques collaboratives au sein d’une organisation et d’un partenariat.
Interroger les données: repenser les vieilles interfaces
Les vieux modèles d’interfaces de recherche influencent notre conception des questions que nous posons aux ensembles de données. Elles forcent les utilisateurs à formuler leurs questions en fonction de critères limités. Ces interfaces pré web qui sont encore utilisées pour donner accès au contenu de catalogues en ligne sont nettement déclassées par la recherche en langage naturel.
Cocher des critères comme la date, l’auteur, le sujet ou le titre ont assez peu à voir avec les comportements et besoins des utilisateurs. L’indexation des contenus et le paramétrage du moteur de recherche des sites sont généralement peu élaborés. Par exemple, explorer les archives du journal Le Devoir est plus intéressant à partir de l’interface de Google. Il suffit de limiter la recherche au site et d’ajouter des expressions ou, même, des questions , comme ceci: « site:https://www.ledevoir.com/ causes du changement climatique ». On peut alors explorer les textes, images et vidéos. Les traces de nos usages ne serviront cependant pas les intérêts du média, mais le modèle économique du moteur de recherche.
Remplacer les cas d’usage par une approche narrative
Avant de développer de nouvelles plateformes, il y aurait place à amélioration pour répondre aux besoins d’information spécifiques des publics et accompagner le développement de services à valeur ajoutée.
Mais trouver les bonnes questions à poser requiert une connaissance des publics cibles et, pourquoi pas, leur participation. Pour cela, il convient de remplacer l’approche technologique (cas d’utilisation) par une approche narrative, plus concrète et plus proche du phénomène informationnel (lier des données pour raconter une histoire).
When we frame information about an object we focus attention on certain aspects of that object or its history. It’s just like choosing a new frame for a painting, which then highlights different qualities of the artwork. Framing is less about the information we feature in a label and more about how we present that information.
Le sujet de cet article dépasse le domaine muséal: What makes a great museum label?
Exploiter des données plus riches de sens
Notre relation aux contenus culturels est de l’ordre du ressenti, du goût et des intérêts. Cependant, nos bases de données et catalogues fournissent une information factuelle, organisée de façon uniforme et anodine, bien loin de la diversité des cultures et expériences humaines. D’autres métadonnées pourraient jouer un rôle aussi important que les métadonnées classiques de type catégorie-titre-auteur, pour la personnalisation des services et pour l’analyse des données d’usage.
Sous la direction d’Yvon Lemay et Anne Klein, de l’École de bibliothéconomie et des sciences de l’information, Archives et création: nouvelles perspectives en archivistique regroupe des publications de recherche sur l’exploitation des archives dans le domaine culturel (arts visuels, littérature, cinéma, musique, arts de la scène, arts textiles et Web). Cette publication devrait être lue par quiconque souhaite réfléchir sur la mise en réseaux des données sur la culture.
Indexation – Émotions – Archives, la recherche menée par Laure Guitard, se rapporte plus spécifiquement à l’enrichissement des modèles de données par la représentation de la charge émotionnelle des contenus et objets (page 151).
l’indexation – professionnelle et collaborative – pourrait permettre d’inclure l’émotion dans la description des archives afin que cette dernière soit reconnue comme une clé d’accès aux documents
Je souligne, avec cette référence, l’importance de la recherche académique et des regards croisés entre domaines d’étude pour apporter de la profondeur à des idées. Les monocultures sectorielle, disciplinaire et technologique nuisent à nos ambitions numériques.
Renforcer le volet cognitif des projets
Il faut revoir des modèles d’indexation de contenu, ou de production de métadonnées. Disposer de données plus riches permet d’analyser la relation de l’utilisateur au contenu, de mieux connaître les publics, de développer des algorithmes de recommandation et, finalement, d’imaginer d’autres façons de valoriser des catalogues, fonds et répertoires.
Nous ne devons pas nous laisser démonter par la complexité des projets ou, pire: brûler de précieuses ressources en « coupant les coins ronds». Nous pouvons y faire face en mettant en commun des ressources et des expertises diversifiées et en élaborant d’autres méthodes de travail. Donnons-nous du temps, mais commençons dès maintenant.
Ajout d’information concernant les cas d’usage et l’approche narrative, à la suite d’une très bonne question posée par Frédéric Julien, sur Facebook.
Extrait du commentaire de Frédéric :
Je ne suis par contre pas certain de comprendre ce que tu entends par « remplacer les cas d’usage par une approche narrative ». Au cours de la dernière année, j’ai eu la précieuse occasion de participer à quelques exercices de consultation auprès de créateurs et usagers de données dans le cas du projet 3R. Ce que j’y entendu a énormément contribué à ma réflexion sur les cas d’usage dans le cadre de l’initiative ANL [Un avenir numérique lié]. Ces deux méthodologies ne me semblent pas du en contradiction l’une avec l’autre (ni avec ce que tu décris dans ton billet… à moins que certains détails ne m’échappent).
Réponse:
/…/ une approche narrative permet de réaliser des cas d’usage en les mettant en contexte (le « comment »). J’emploie un terme fort, « remplacer », pour attirer l’attention sur une étape du projet sur laquelle se fondent beaucoup d’objectifs (et d’espoirs). C’est une étape cruciale pour la mise en relation de l’information avec des utilisateurs. Elle est trop souvent escamotée ou sert uniquement à construire des exemples de requêtes.
Suivre une approche narrative ne signifie pas raconter une histoire, mais analyser des comportements, des usages, des interfaces et des structures de données pour produire des exemples qui vont démontrer l’utilité ou la valeur ajoutée du système.
Cependant, les cas d’usage réalisés de façon habituelle (comme en informatique), portent sur le « quoi » (les données, les étiquettes à mettre) alors que les éléments de la recherche et de la découverte ne sont plus les mêmes:
- Interrogation de données liées conçue comme des requêtes sur des BD tabulaires (où est le potentiel du liage de données?)
- Travail de terrain très rarement réalisé avec des utilisateurs finaux, dont des non-usagers (ex: non-visiteurs de musées) et des non-amateurs de certains type d’offres (ex: films québécois).
- Confusion entre parcours de recherche et de découverte (qu’est-ce que chercher? découvrir? comment cela se produit-il dans des contextes spécifiques, avec certains supports et chez certains types d’utilisateurs ?)
Web sémantique: de choc culturel à transformation numérique
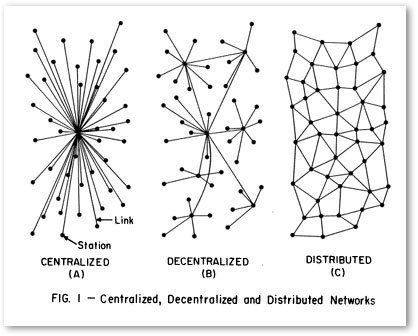
C’est que nous avons pu constater au fil des présentations de la troisième édition du Colloque sur le web sémantique au Québec. Quelle que soit la nature de la problématique, du projet et du secteur d’activité considéré, tous les conférenciers ont fait état de changements nécessaires pour profiter des avantages du web de données.
Ces changements se manifestent à plusieurs niveaux: technologique, organisationnel, culturel, professionnel et structurel.
De fragmentation à intégration
Changement technologique – Le web sémantique permet de fournir des solutions aux problèmes d’interopérabilité des systèmes en affranchissant les données des environnements matériels et logiciels ne favorisant pas les interconnexions. Il devient donc essentiel, pour les professionnels de l’informatique, de se familiariser avec les graphes de données liées et d’adopter des standards ouverts qui permettent de sortir les données des silos des bases de données classiques. Ces nouvelles connaissances sont nécessaires à l’accompagnement des autres secteurs métiers et à ce que le service informatique contribue à l’élaboration d’une définition partagée des normes, règles et processus pour la qualité des données.
▷ Pour aller plus loin: démonstration très accessible des limites de la base de données classique et des possibilités qu’offre le graphe de données liées pour le traitement des connaissances, par Gautier Poupeau, architecte de données à l’Institut national de l’audiovisuel (INA), France.
De centralisation à distribution
Changement organisationnel – Un projet de données liées (ou ouvertes et liées) est une démarche interdisciplinaire et collaborative. À l’image du Web, qui ne se développe pas de façon centralisée mais distribuée, la qualité des données devrait être une responsabilité partagée par toutes les fonctions d’une organisation.
Pour avoir des données et métadonnées utiles, il faut améliorer les compétences des personnes qui les produisent par l’apprentissage des bonnes pratiques — comme l’usage de référentiels communs pour catégoriser des documents et l’utilisation d’outils qui favorisent l’accessibilité et le partage de données. Ceci implique également, une maîtrise du cycle de vie des données (création/collecte, traitement, analyse, conservation, accès, réutilisation) par tous les services.
Dans cette même perspective, la résilience et les bons résultats d’un projet de données liées se fondent sur de nouvelles méthodes de travail qui visent la décentralisation des décisions relatives à l’identification des problématiques, à la priorisation des projets et à la proposition de solutions. C’est une étape clé vers l’adoption de systèmes distribués et de modes de direction et d’action plus agiles et plus propices à l’innovation que les structures hiérarchiques.
▷ Pour aller plus loin: conférence de Diane Mercier, docteure en sciences de l’information, sur le web sémantique et la maturité informationnelle de l’organisation (2016). Après une véritable transformation numérique, la prise en charge de la qualité des données n’est plus uniquement du ressort de l’informatique, mais de tous les métiers et la gouvernance des données n’est plus fragmentée, mais globale.
D’uniformisation à harmonisation
Changement culturel – Lorsque différents acteurs internes et externes sont appelés à contribuer à la production de données liées, il n’est pas rare d’assister à une confrontation des savoirs, des perspectives et des vocabulaires utilisés. Pourtant, dans un projet de données liées, plusieurs modèles, standards et vocabulaires peuvent cohabiter dans un même système pour autant que ceux-ci soient conformes aux normes techniques du web sémantique. Il ne s’agit pas d’uniformiser les façons de décrire des ressources, mais de normaliser les référentiels pour les rendre interopérables, la diversité des perspectives venant alors enrichir la connaissance que nous avons de ces ressources.
Il est d’autant plus important d’accueillir cette diversité des pratiques descriptives que, dans divers domaines allant de la muséologie aux administrations publiques, nous sommes amenés à prendre conscience des biais culturels véhiculés par les différents modèles de représentation et de classification en usage au sein des organisations.
▷ Pour aller plus loin: exemple d’ONOMA, un projet du Ministère de la Culture et de la Communication (France) visant à lier les différents référentiels qui décrivent des auteurs, créateurs, producteurs et personnalités intervenant dans le cycle de vie d’un bien culturel. Une démarche d’harmonisation similaire peut être mise en œuvre dans bien d’autres domaines.
De technocentrisme à interdisciplinarité
Changement professionnel – Comment des spécialistes des TI et des sciences de la donnée peuvent-ils travailler sur le traitement de la connaissance d’un domaine hors de leur champ de compétences? Un projet web sémantique comporte des défis de nature technique et conceptuelle pour lesquelles il est impératif de rassembler une diversité de perspectives et d’expertises. Notamment, en ce qui a trait à l’organisation et au traitement de l’information, comme l’indexation de documents, la modélisation des connaissances ou la linguistique.
▷ Pour aller plus loin: billet de Fred Cavazza, spécialiste des transformations numériques, sur le rôle central des experts métiers dans des projets de traitement de données, dont des systèmes d’intelligence artificielle.
Du court terme au long terme
Changement structurel – Les programmes qui soutiennent organismes et secteurs d’activité sont généralement orientés vers l’atteinte de résultats à court terme. Or, il ne faut pas attendre de résultats immédiats de projet de données liées. Il y a donc peu d’incitatifs, pour les organisations, à réaliser des projets leur permettant d’entrer dans l’économie de la connaissance. Pour ce faire, il faut adapter les politiques et programmes afin d’encourager les investissements à moyen et long termes. Ceux-ci donneront lieu à des initiatives telles que des preuves de concept ou des prototypes, préalables nécessaires de projets plus ambitieux.
▷ En résumé – Le web sémantique ne constitue pas uniquement une évolution technologique mais avant tout une transformation profonde des modes de gestion de l’information et de gouvernance des données. Il nécessite la mise en place de nouvelles façons de travailler, tant pour la décentralisation des prises de décision que pour l’abolition des silos informationnels et la mise en commun de l’information.
Transformation pour un monde numérique
Le web sémantique nous amène à envisager le numérique comme un écosystème d’acteurs métiers et de moyens technologiques interdépendants. Contrairement aux projets informatiques « traditionnels », il nécessite l’aménagement d’un environnement d’apprentissage collaboratif et de conversations transversales dans l’organisation. Sa finalité est de faire émerger l’intelligence collective permettant de produire de la connaissance et non de développer des systèmes.
Déclaration des communs numériques pour un Québec postindustriel
Il n’est pas minuit moins cinq, nous avons dépassé minuit. C’est fait !
/…/ Nous allons vivre dans un monde postaméricain, postInternet, post néolibéral et postmoderne, Michel Cartier
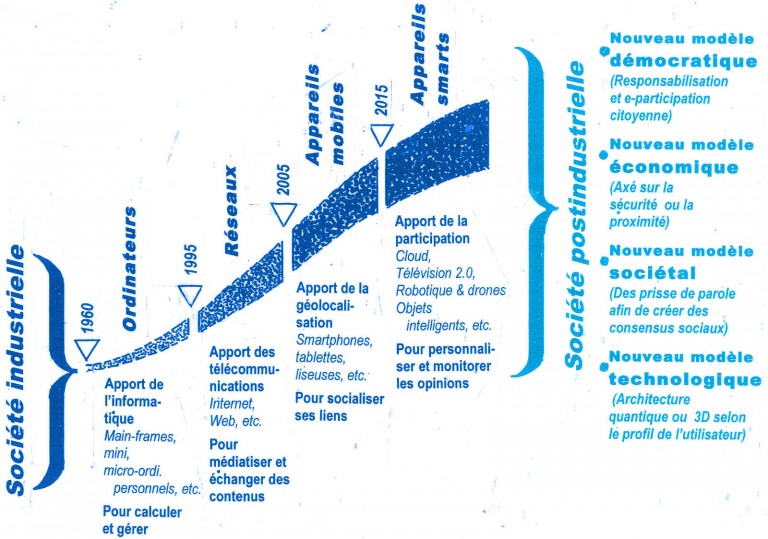
Dans Le 21e siècle, Michel Cartier réalise une extraordinaire synthèse des mutations que nous traversons, Bien plus qu’une révolution technologique, c’est un véritable changement de société qui s’est amorcé. Et il se fera avec ou contre nous.
C’est dans cette perspective que près d’une vingtaine d’associations, collectifs, entreprises et organismes sans but lucratif, qui jouent un rôle actif dans l’écosystème numérique québécois, s’unissent pour signer une Déclaration des communs numériques dans le cadre du processus de consultation de la Stratégie numérique du Québec.
La Déclaration affirme l’urgence de remettre le numérique au service de l’humain, de ses capacités fondamentales et des biens communs afin d’améliorer la vie des gens et de soutenir une démocratie plus inclusive.
Démarche de cocréation et processus itératif
FACIL et les collaborateurs du Café des savoirs libres se sont proposés d’inviter divers associations, collectifs, entreprises et organismes sans but lucratif à participer à la cocréation d’une déclaration commune plutôt que de contribuer individuellement à la consultation gouvernementale. Le 12 novembre 2016, lors d’une première rencontre, à Montréal, à la bibliothèque Mordecai Richler, les participants se sont entendus sur des principes généraux plutôt que sur des moyens, afin de rassembler des signataires partageant les mêmes préoccupations. La démarche se veut itérative et ouverte aux regroupements et associations qui se reconnaîtront dans cette déclaration ou qui souhaiteraient s’en inspirer pour élaborer leur propre document.
Les signataires de la Déclaration croient :
- Que le gouvernement doit s’assurer que les citoyen.ne.s et les membres de la société civile soient davantage engagé.e.s dans l’élaboration de cette Stratégie du numérique qui a des implications dans la fabrique de leur vie aujourd’hui et demain;
- Que le gouvernement se doit d’être exemplaire en s’engageant à amorcer en son sein les changements organisationnels et culturels requis afin de moderniser l’État, de s’ouvrir à la démocratie participative et d’améliorer les services aux citoyens (dépoussiérons le rapport Gouverner ensemble, présenté en 2012 par Henri-François Gautrin , alors député de Verdun et leader parlementaire adjoint du gouvernement);
- Que de nombreuses voix n’auront pas eu les moyens et les capacités d’être entendues et
- Que des questions fondamentales n’auront pas été posées et discutées à travers la méthode de consultation actuelle.
La Déclaration soulève certaines d’entre elles.
Lire la Déclaration des communs numériques (PDF, 56 Ko)
L’information n’est pas la priorité des organisations
Initialement publié dans le blogue de Direction informatique, le 31 octobre 2013.
On dit que Lewis Platt, PDG de Hewlett-Packard dans les années 80, se serait un jour exclamé : « Si, au moins, HP savait ce que HP sait, nous serions trois fois plus productifs. »
Chef d’entreprise clairvoyant et progressiste, Platt reconnaissait que la technologie, seule, ne peut apporter de solution à la difficulté d’accéder à l’information dans son organisation et de faire les connexions nécessaires pour faire du sens.
Si l’offre de solutions technologiques est aujourd’hui abondante, l’information ne semble toujours pas un enjeu prioritaire pour bon nombre d’organisations.
Un actif stratégique, vraiment?
Selon le célèbre théoricien du management Peter Drucker, les données, sans la perspective que donnent les connaissances et l’expérience, ont peu de valeur dans le cadre d’un processus de décision:
Information is data endowed with relevance and purpose
Traduction libre :
L’information c’est des données pertinentes et qui ont une utilité.
Les enjeux et usages stratégiques de la gestion de l’information sont nombreux et distribués dans toute l’organisation :
- accès à l’information – soit la bonne information, au bon moment;
- connexions entre les données et les ensembles de données;
- des données qui font du sens (contexte sémantique);
- moteurs de recherche performants;
- intranets facilitant les échanges de connaissances et le partage d’expertise.
Si l’information est un actif stratégique, rares sont pourtant les entreprises et gouvernements qui accordent autant de ressources à son organisation, son traitement et son analyse qu’à l’acquisition de technologies permettant de la stocker et de la manipuler.
Où sont les ressources?
Thomas Davenport est l’auteur de Information Ecology, le premier ouvrage sur l’approche intégrée de la gestion stratégique de l’information. Selon lui, il y a confusion entre « information » (le contenu) et « informatique » (le contenant).
Despite titles like » Information Services », « Chief Information Officer » and « Information Center », most such functions are preoccupied with technology – if not hardware, then software, applications development, and communications. /…/ If you approached the Information Systems help desk of the typical company and asked, « Where can I find information on our competitors in South America? » I doubt you’d get more than a blank stare.
Traduction libre :
En dépit de titres comme « Services d’information », « Directeur principal de l’information » et « Centre d’information », la plupart de ces fonctions sont concernées par la technologie – voire par le matériel, puis les applications, le développement de logiciels et les communications. /…/ Si vous vous adressiez au service d’assistance technique du service informatique de n’importe quelle entreprise et que vous demandiez, « Où puis-je trouver de l’information sur nos compétiteurs d’Amérique Latine ? » je doute que vous n’obteniez plus qu’un regard déconcerté.
Une piste pourtant maintes fois invoquée, mais rarement mise en œuvre, consisterait à implanter une gouvernance de l’information réunissant les spécialistes de l’informatique et de l’information. Il s’y élaborerait une vision commune de la gestion des actifs informationnels. La gouvernance des projets numériques est un sujet que j’ai d’ailleurs abordé récemment.
Le mirage de la solution technologique
L’informatique n’est pas une fin en soi : c’est une affirmation souvent entendue, mais les pratiques des entreprises et des administrations publiques traduisent une toute autre réalité. Yves Marcoux, spécialiste des documents structurés et professeur à l’École de Bibliothéconomie et des sciences de l’information de l’Université de Montréal, observe dans une étude de la gestion de l’information au gouvernement :
On vivait avec l’impression que la solution résidait dans des investissements toujours plus grands en ressources technologiques (matériel d’abord, puis programmeurs, analystes, infrastructures réseau et logiciels ensuite). Il est maintenant généralement admis que cette façon de concevoir les choses est un cul-de-sac. À la rescousse se sont succédés des courants comme la programmation structurée, l’orientation-objet et une multitude de méthodologies d’analyse, de modélisation, de développement et d’évaluation de systèmes.
Le rapport d’étude a été déposé à l’intention du Directeur principal de l’information, en 2004. Il recommandait entre autres:
La gestion de l’information devait être abordée avec un mélange de pragmatisme et de méthodologie, mais surtout, en mettant l’accent sur les humains qui produisent et utilisent l’information plutôt que sur les technologies qui les aident à le faire.
Sommes-nous prêts pour l’économie du savoir?
Aucune solution de Big data ne pourra toute seule venir à bout d’une accumulation de données et de documents non structurés et sans attributs communs. Nous persistons à ne voir que le volet technologique de la solution. Or, nous passons actuellement d’une ère industrielle à une ère numérique au cours de laquelle le savoir aura autant de valeur que la production.
Si l’information est réellement le carburant de l’économie du savoir, alors il semble que nous soyons en train de construire des réseaux de pipelines sans nous soucier de l’approvisionnement en pétrole !
Big data : ces données que nous ne savons pas exploiter
Les barrières technologiques et organisationnelles sont des freins à l’exploitation des données. Ajoutons à ceux-ci l’absence de compétences. Un problème qui n’est pas spécifique au commerce de détail.
Retail’s BIG Blog | 5 digital retail trends to watch in the next 5 years
Data
We all know analytics are important. Heck, we’ve been trying to use them for years! But Joel predicts a massive transition in which retailers combine their current very linear relationship with data with the more cyclical silo that comes from gathering data from many different places.Social CRM is imminent (and we probably won’t be calling it that for very long!). The problem Joel foresees is that retailers just aren’t staffed for this kind of analytics yet. (Mitch Joel)
À l’ère de la fragmentation des marchés et des audiences, la problématique de l’exploitation des données est une tendance lourde.
Big data: The next frontier for innovation, competition, and productivity (McKinsey)
There will be a shortage of talent necessary for organizations to take advantage of big data. By 2018, the United States alone could face a shortage of 140,000 to 190,000 people with deep analytical skills as well as 1.5 million managers and analysts with the know-how to use the analysis of big data to make effective decisions.
Un nombre incalculable d’applications et de technologies analogiques et numériques recueillent des données dont le volume est en croissance exponentielle. Il y a de nombreux enjeux, dont la sécurité, la protection des renseignements personnels et la censure. La meilleure façon d’y faire face est l’ouverture.

The Data Deluge (The Economist)
The best way to deal with these drawbacks of the data deluge is, paradoxically, to make more data available in the right way, by requiring greater transparency in several areas. First, users should be given greater access to and control over the information held about them, including whom it is shared with. Google allows users to see what information it holds about them, and lets them delete their search histories or modify the targeting of advertising, for example. Second, organisations should be required to disclose details of security breaches, as is already the case in some parts of the world, to encourage bosses to take information security more seriously. Third, organisations should be subject to an annual security audit, with the resulting grade made public (though details of any problems exposed would not be). This would encourage companies to keep their security measures up to date.
Reconfiguration des professions de la « gestion du savoir » (bibliothécaires, documentalistes, archivistes) dont les compétences sont codifiées et qui font une place importante aux enjeux d’éthique.
Vers des architectes de l’information
L’enjeu pour ces nouveaux professionnels sera de concilier les pratiques des différents mondes du document. Il leur faudra, de façon très pragmatique, construire à la fois des prestations et des institutions qui soient réellement dédiées à la communauté qu’ils servent, reprenant à leur compte la longue tradition des infrastructures épistémiques, sans l’inféoder aux stratégies industrielles qui visent à verrouiller le Web ni la réduire à la logique performative des ingénieurs. (Jean-Michel Salaün)
J’adore mon métier.
Passages : Les intranets sociaux pour répondre aux besoins informationnels de l’entreprise
The Content Economy by Oscar Berg: The business case for social intranets
Ce billet d’Oscar Berg fait la démonstration de la pertinence (et même, de la nécessité) des intranets sociaux auprès des entreprises qui font un usage intensif de leur capital intellectuel.
Les coûts de production et de gestion de l’information, dans un intranet traditionnel, forcent les gestionnaires à prioriser les besoins informationnels de l’entreprise. Ceci réduit considérablement la sérendipité des rencontres informationnelles qui constitue un terreau fertile pour l’innovation.
En faisant littéralement fondre le coût des communications, la technologie et les nouveaux usages du web ont ouvert à tous la production de contenu. Nous sommes passés de consommateurs à « prosumers » (à la fois producteurs et consommateurs d’information).
De plus, les réseaux sociaux ont propulsé les communauté d’intérêt et favorisé l’infiltration de la culture web (participation spontanée et non hiérarchique) en entreprise.
Le problème n’est pas la surabondance d’information, c’est la satisfaction de la demande
La surabondance d’information n’est pas le problème qu’il faut solutionner. L’abondance, à la différente de la rareté, permet d’assurer une plus grande disponibilité et plus de diversité. Le problème, c’est de répondre à la demande d’information; de satisfaire la longue traîne des besoins informationnels. Il faut donc améliorer les filtres (mécaniques ou sociaux) pour repérer, qualifier, commenter, remixer l’information.
/…/ we need to focus more on creating filters to handle the abundance of information than trying to stop the inflow of information. We need to stop seeing information supply as a problem to be solved (by trying to delimit it) and instead focus on how to satisfy information demand.
Passages : Il faut socialiser l’intranet
The Content Economy by Oscar Berg: Why traditional intranets fail today’s knowledge workers
Si les intranets connaissent autant d’échecs auprès des métiers qui font une consommation/production intensive du savoir (données, information, documents) c’est que leur conception repose sur la poussée automatique de contenu (« push technology »).
Caractéristiques d’un intranet du modèle « push » :
- Contenu produit à l’avance ou sélectionné;
- Besoins informationnels anticipés;
- Contenu produit par un ensemble de ressources spécialisées;
- Le contrôle du message, le format et l’organisation de l’information sont sous la responsabilité d’un groupe d’individus.
Ce modèle ne peut donc pas répondre adéquatement aux besoins d’information imprévus, aux contributeurs potentiels issus de l’ensemble des membres de l’organisation et à la nécessaire sérendipité (« découverte d’individus ou d’information que nous ne savions pas que nous cherchions »), autrement dit, la longue traîne de l’information.
L’intranet du modèle « pull » est un intranet social :
- Abondance de contenu;
- Diversité de sources et de contributeurs;
- Rôle essentiel des filtres (technologie et effet de réseau);
- Auto régulation (communautés d’intérêt).
Le principal enjeu d’un intranet est la longue traîne de l’information.
Un intranet pourrait combiner un système d’information stable pour répondre aux besoins courants et prévisibles et un système d’information organique (social) pour favoriser la recherche de solutions créatives à des situations imprévisibles.