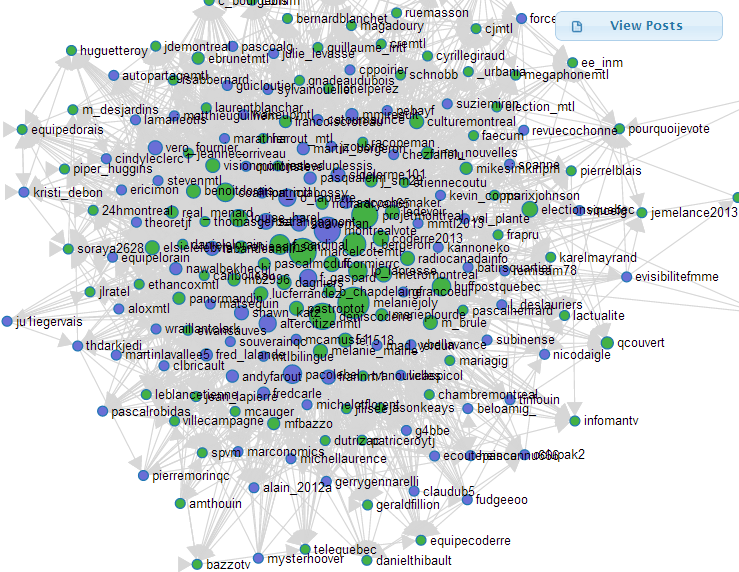
Google annonce un changement à son algorithme afin de promouvoir le journalisme d’enquête.
Mais ceci servira surtout à améliorer la quantité de données contenues dans son graphe de connaissances (knowledge graph) et d’étendre son influence sur ce que nous voyons sur le web.
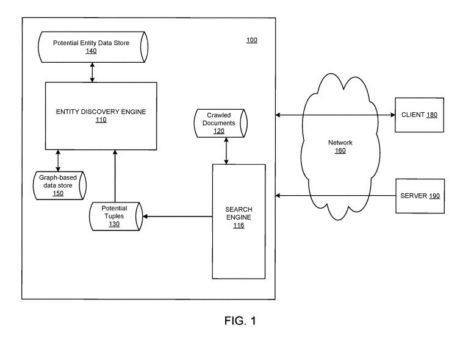
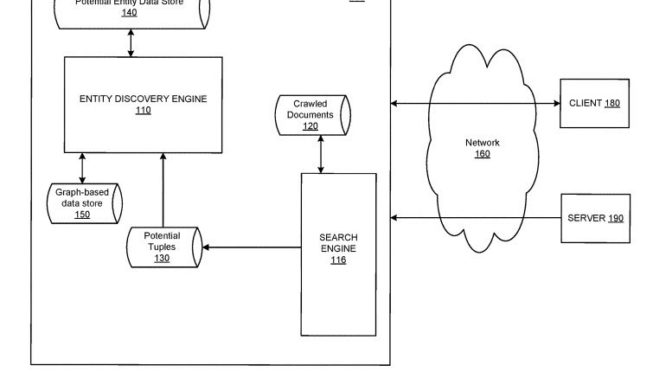
Bill Slawski est un spécialiste de l’optimisation pour moteurs de recherche. Sa formation de juriste lui permet de porte une attention particulière aux demandes de brevet. Il en commentait une, récemment, qui fait référence au développement du graphe de connaissances (knowledge graph) de Google. Elle concerne l’intégration, dans son graphe, d’information collectée sur le web, afin d’accroître la masse de données :
The patent points out at one place, that human evaluators may review additions to a knowledge graph. It is interesting seeing how it can use sources such as news sources to add new entities and facts about those entities.
Comme chez les autres entreprises dont le modèle d’affaires repose sur la donnée, une grande partie du traitement de l’information et de la production de données résulte du travail non rémunéré d’amateurs et passionnés:
How can you teach an algorithm to understand all these distinctions? Gingras said Google is doing so through its Quality Raters, a global network of more than 10,000 individuals who offer feedback on Google’s search results, which in turn is used to improve the company’s search algorithms.
Google says it will do more to prioritize original reporting in search
Ceci sert-il les intérêts du journalisme ? Probablement, mais il est trop tôt pour le vérifier. Cela sert surtout à développer une connaissance très poussée de nos rapports à l’information et de permettre à d’autres d’influencer notre vision du monde et de fabriquer des opinions. S’informer sur le scandale Facebook – Cambridge Analytica devrait nous faire prendre la mesure de l’intervention de ces systèmes dans notre développement social, notamment, la fabrication d’opinions et d’antagonismes.