Notre focalisation sur le marketing et les solutions technologiques est-elle un risque pour la diversité culturelle ? L’absence de vision partagée et la course aux résultats peuvent-elles faire perdre aux acteurs de la culture la maîtrise stratégique des choix en matière de diffusion et d’accès ?
Nous espérons des solutions mécanistes qui accroîtront la consommation en imposant des offres culturelles à la façon des vieux modèles publicitaires. La mise en données de contenus culturels ne doit pas nous faire oublier qu’il appartient à chacun de réaliser la partie la plus stratégique d’un projet numérique : décider de la façon dont une chose (une œuvre, par exemple) doit être documentée et déterminer ce qui la relie à d’autres informations dans le web des données.
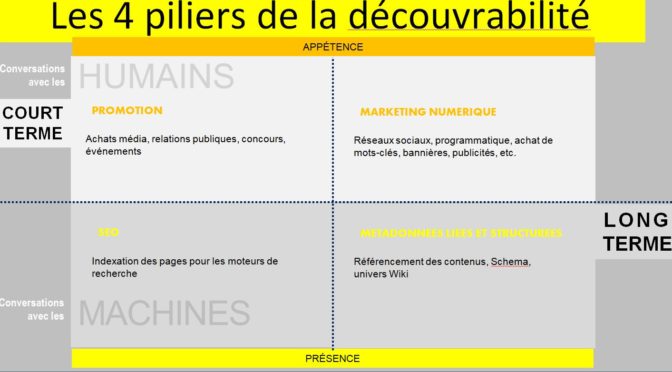
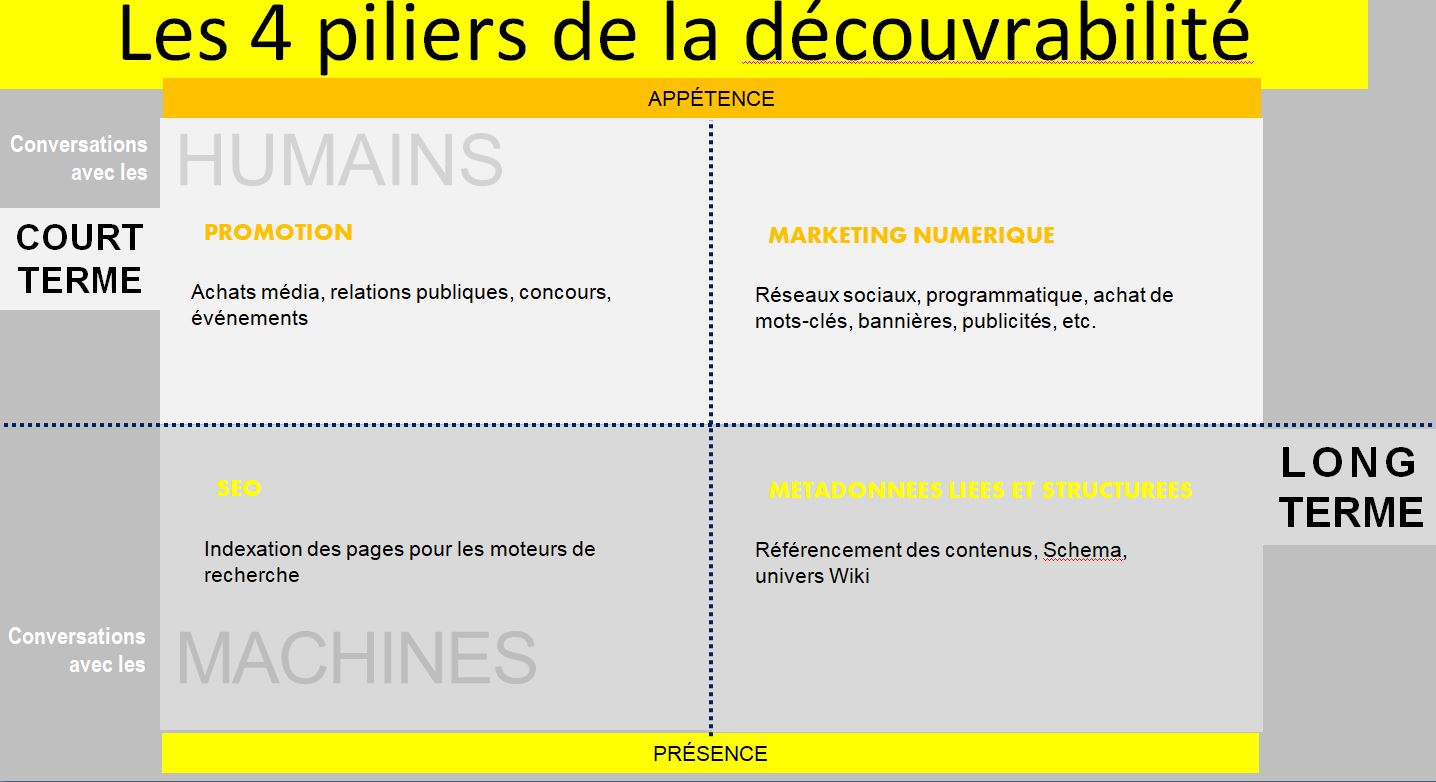
L’emploi du mot « initiative », de préférence à « projet », souligne l’importance de la démarche et des apprentissages, par rapport à la livraison d’un outil ou la modernisation d’un système. Voici comment nos initiatives pourraient être plus marquantes.
Miser sur l’éducation et l’accès à la culture
Le marketing peut entraîner la consommation de produits et services culturels, mais ce sont l’éducation et l’accès à la culture qui peuvent faire découvrir et apprécier la culture. Or, il faudrait une plus grande porosité entre les politiques et projets éducatifs et culturels pour miser sur l’environnement familial et social pour faire connaître la culture.
Il faudrait également donner un rôle plus actif, dans nos plans et initiatives numériques, aux médiateurs de proximité que sont les professionnels des bibliothèques publiques et scolaires.
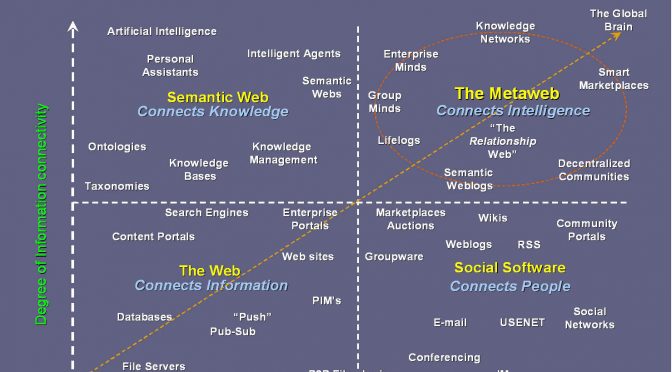
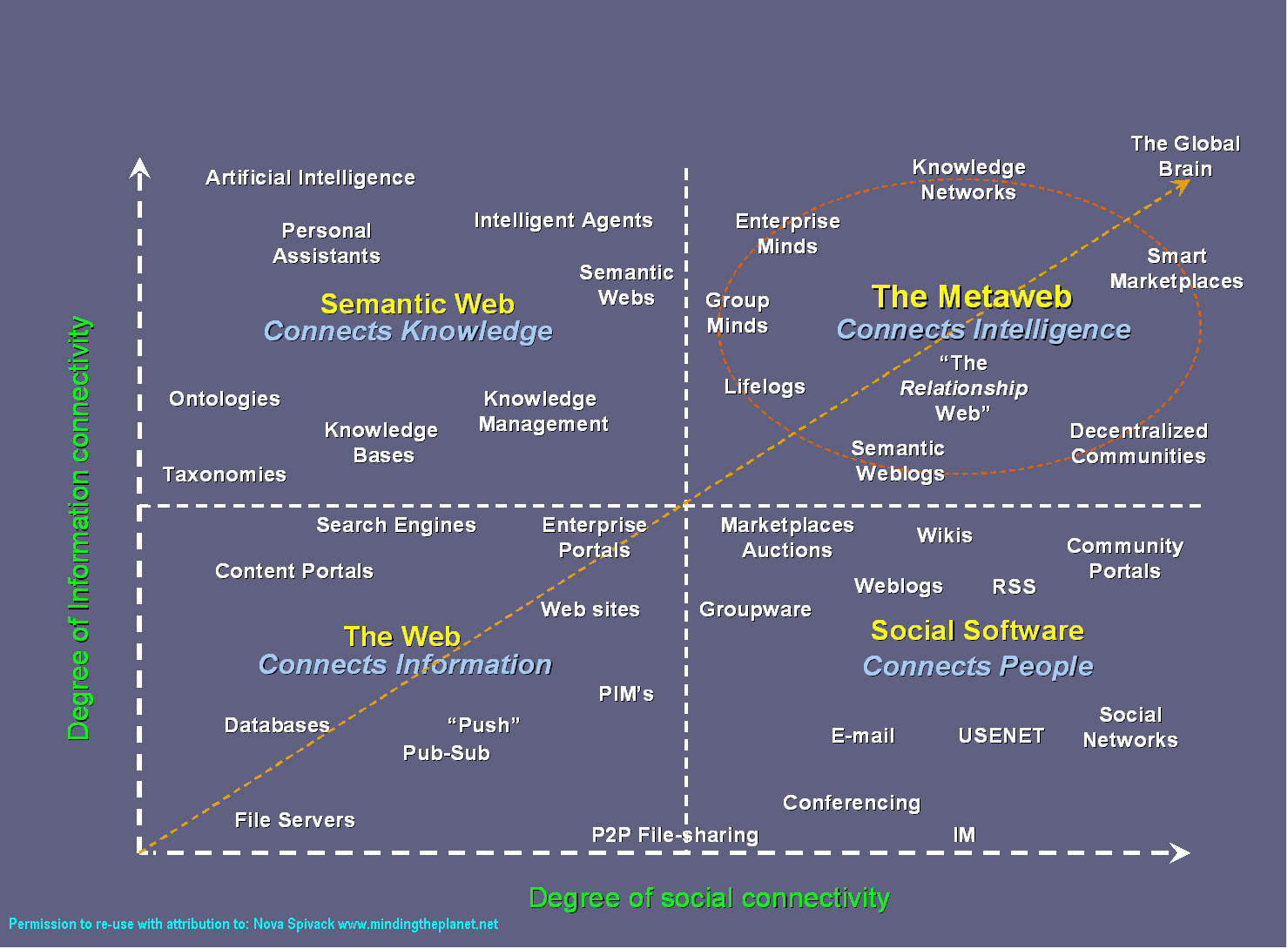
Privilégier les initiatives qui favorisent la diversité
Nous cherchons, par tous les moyens, à ce que la culture locale soit vue et consommée, de préférence à d’autres offres. Nos propositions techniques partagent cependant les défauts des plateformes dominantes. Qu’il s’agisse de baliser des contenus pour les moteurs de recherche ou de créer de nouvelles bases de données interrogeables, la façon dont sont conçues ces « solutions » technologiques nuit à la diversité des offres culturelles.
- La centralisation des décisions et du traitement de l’information renforce l’uniformisation.
- La popularité comme principal critère de sélection défavorise les contenus de niche, les cultures et langues en situation minoritaire dans un répertoire, sur un territoire ou par rapport au reste du monde.
- L’uniformisation du traitement documentaire, par l’imposition d’une méthode de classification, de vocabulaires et de référentiels spécifiques, appauvrit la qualité de l’information. Par conséquent, elle en diminue l’intérêt et la valeur pour différents publics. Les initiatives de décolonisation des modèles descriptifs tentent de réparer les ravages du rouleau compresseur de l’uniformisation sur la citoyenneté culturelle des peuples autochtones.
- Les systèmes de recommandations et de personnalisation des offres culturelles reposent sur la similarité des produits et services ou sur la similarité des profils des utilisateurs.
Ne pas céder des choix stratégiques
À l’arrivée de l’informatique, nous avons confié l’organisation de l’information à des systèmes de bases de données, selon les termes d’entreprises. Il est temps de remettre, selon nos propres termes, cette intelligence dans nos sites web et, plus spécifiquement, dans nos catalogues, collections, répertoires, fonds et archives. Nous ne devrions pas abandonner la création de sens et de liens à des opérateurs de plateformes et à des fournisseurs de services.
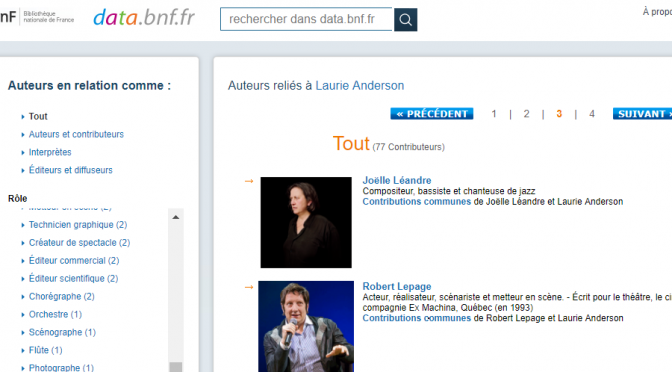
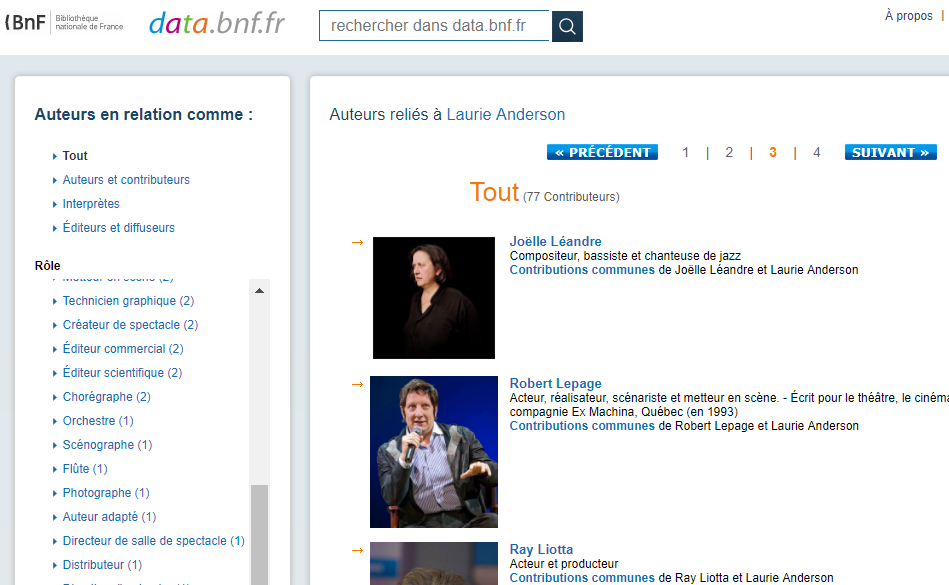
Être trouvé ou découvert et laisser des traces numériques sont les fruits d’un travail de documentation. Celui-ci est trop souvent escamoté par la recherche d’une solution technologique. De plus, les façons de décrire des productions ou des offres culturelles offrent peu de possibilité de mettre celles-ci en relation avec des intérêts et des passions.
Par exemple, les catalogues et répertoires en ligne pourraient grandement améliorer l’expérience des utilisateurs en devenant des bases de connaissances interactives et interconnectées. Il serait ainsi possible d’intégrer de nouvelles informations et des liens vers d’autres ressources grâce aux contributions de chercheurs et d’amateurs.
Documenter: laisser des traces, créer du lien et faire sa marque
Documenter la culture et rendre cette information pertinente, attrayante et utile pour divers publics et usages sont la responsabilité de tous les acteurs du milieu culturel. Il manque une méthode de travail et des outils faciles à utiliser pour réaliser, en équipe ou avec des partenaires, l’évaluation de l’information publiée sur le web et le choix des métadonnées qui feront des liens entre les offres culturelles et les publics cibles.
C’est dans cette perspective qu’a été conçu un guide destiné aux artistes et aux organisations du milieu de la danse. Cette approche, en trois étapes (stratégie, information, technologie) repousse les choix technologiques à la toute dernière étape afin de remettre la documentation de la danse à ceux et celles qui la font.
Extraits du lancement du guide Bien documenter pour favoriser la découverte en ligne, réalisé pour la Fondation Jean-Pierre Perreault, dans le cadre de l’initiative La danse dans le web des données.