Comment multiplier la portée des programmes de soutien à la transformation des organisations dans un contexte numérique ? En favorisant des initiatives qui ont pour objectifs des résultats durables et transmissibles à d’autres individus, organismes ou secteurs d’activités.
Ceux qui tirent la plus grande partie des bénéfices d’une économie numérique sont ceux qui en maîtrisent les concepts clés (collecte de données, organisation et classification de l’information, traitement algorithmique) et qui prennent les moyens pour profiter du réseau (contenu généré par les utilisateurs, mobilisation de capital intellectuel). Nous ne pouvons cependant pas tenter d’imiter des modèles qui ont nécessité des investissements colossaux et qui, après des années d’expérimentation, constituent des entités aussi riches et puissantes que des états. Mais nous ne devons pas non plus demeurer des fournisseurs de données et de contenus.
C’est pourquoi des programmes d’aide à la transformation numérique et à l’innovation, quel que soit le secteur d’activité, devraient permettre d’accroître de manière plus efficace nos connaissances en matière d’information numérisée , et de favoriser la collaboration entre organismes pour concevoir et expérimenter d’autres modèles de création de valeur.
Voici 3 notions qui sont essentielles pour sortir des vieux modèles :
1 – L’information avant les moyens technologiques
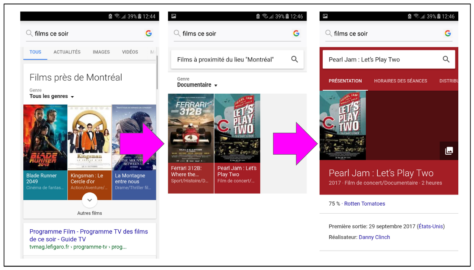
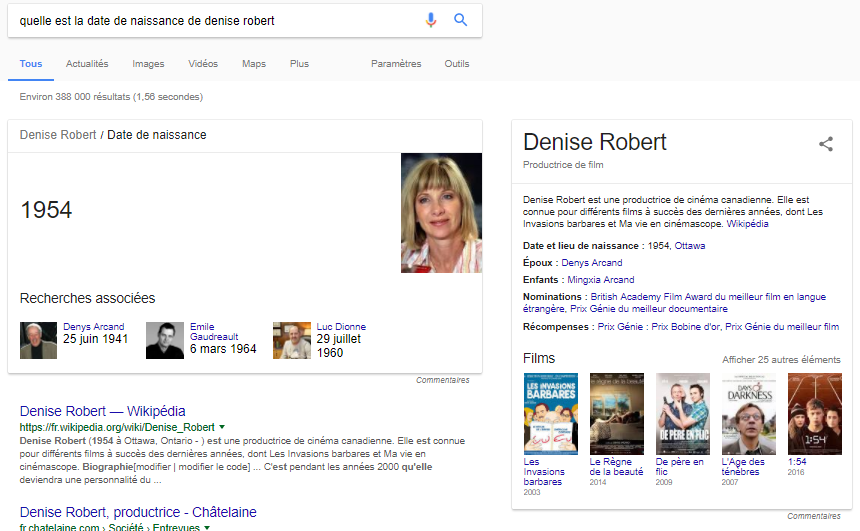
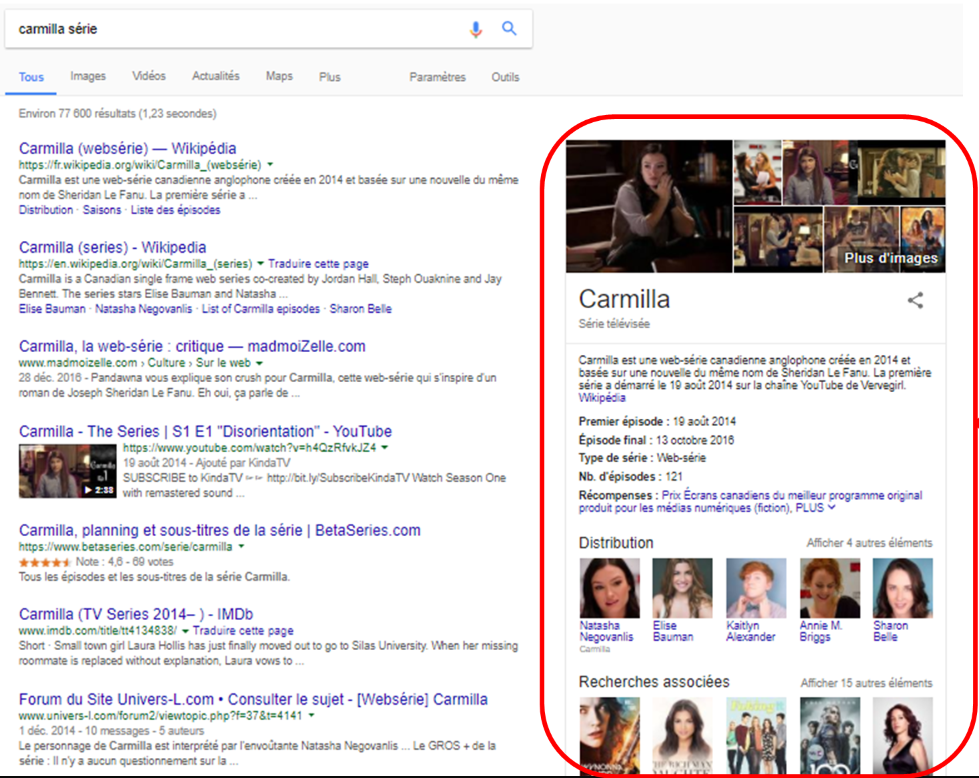
Découvrabilité, métadonnées, mise en commun de données, diffusion de contenu: bien avant d’être du développement logiciel ou la mise en place d’infrastructures, c’est un travail sur la définition et l’application de principes de traitement et d’organisation de l’information.
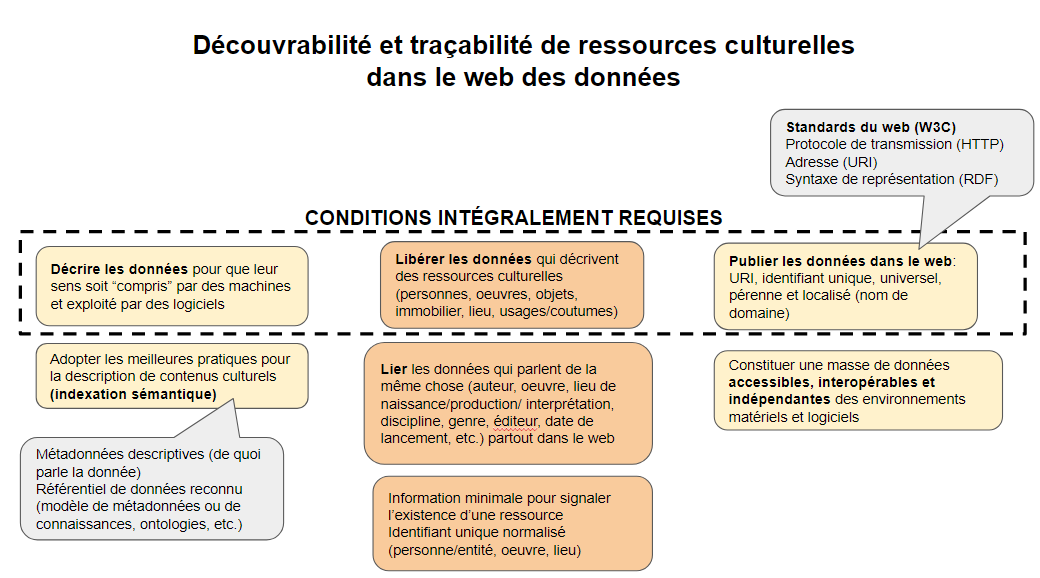
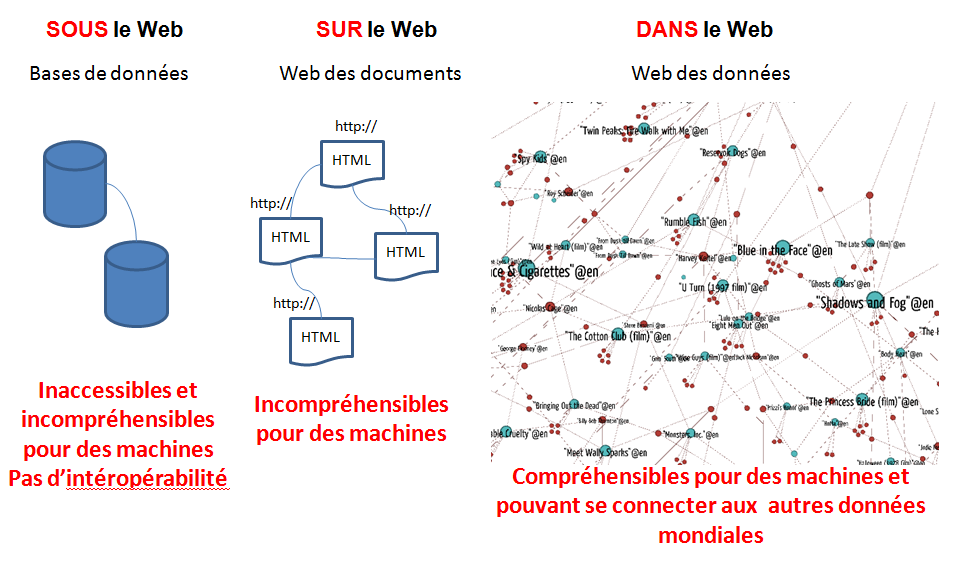
La mise en nombres binaires de l’information (soit des suites de 1 et de 0 qui représentent des caractères, puis des mots) est ce qui rend son traitement et sa transmission possibles par des machines. Par contre, pour que cette information numérisée puisse être repérable, « comprise » et exploitable par des machines qui sont, à présent, en quête de sens, il faut :
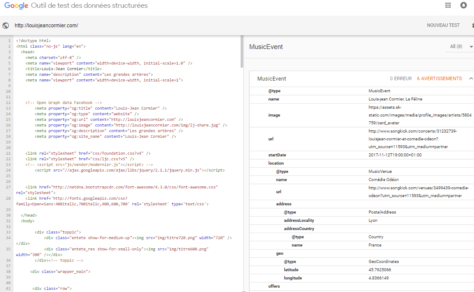
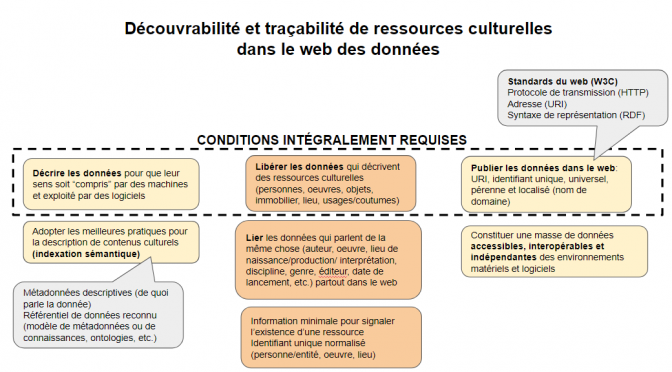
- Décrire les données pour qu’elles soient lisibles et utilisables pour des machines.
- Publier les données dans le web selon les standards du W3C pour les données ouvertes et liées (Linked Open Data).
De plus, pour rendre cette information découvrable dans le web, il faut préalablement réaliser une étape essentielle:
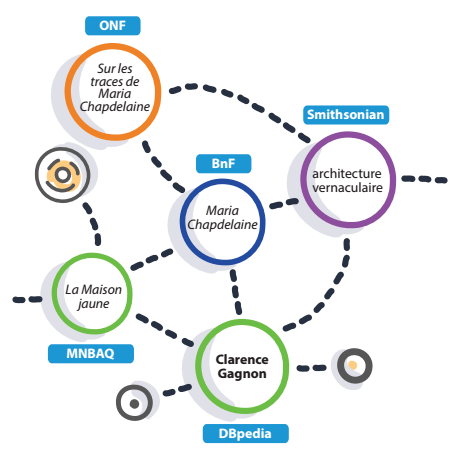
- Libérer les données qui décrivent des ressources (contenus culturels, patrimoine vivant et immatériel, produits, services, etc.).
2 – Les données comme actif plutôt que matière première
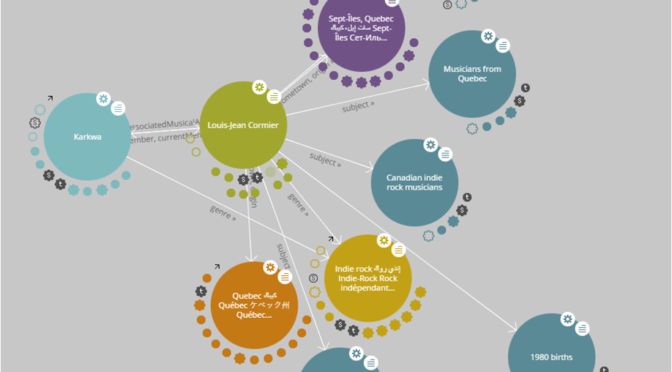
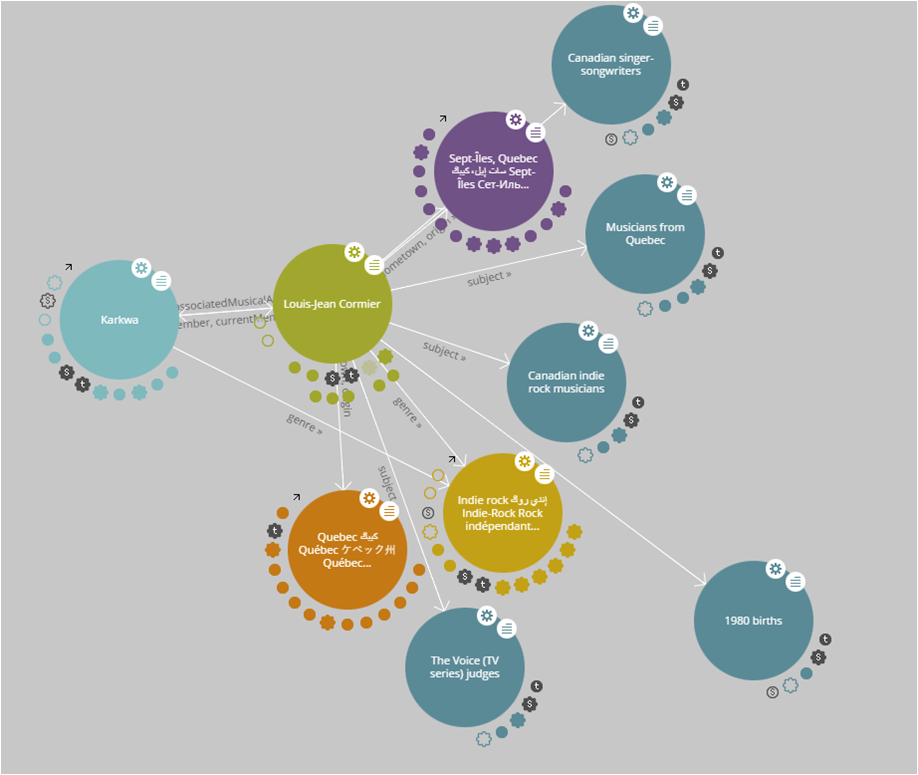
Nous souhaitons que les moteurs de recherche et autres types de technologie utilisés pour ratisser le web repèrent les données qui décrivent nos contenus, produits et services. Or, nous persistons à considérer la donnée comme une ressource alors que dans une économie numérique, il s’agit d’un actif. Cette nuance est extrêmement importante puisque cette ressource n’a de valeur que si elle est rare. Nous pourrions, par exemple, avoir à payer pour obtenir les données qui décrivent les titres d’un répertoire musical. Cependant, les données ne seraient donc pas repérables et accessibles pour les humains et les machines.
Considérer les données comme un actif permet de capitaliser sur la valeur de l’information qu’elles permettent de générer et sur le potentiel de découvrabilité qu’elles accordent aux contenus qu’elles décrivent.
3 – Travailler ensemble autour des données
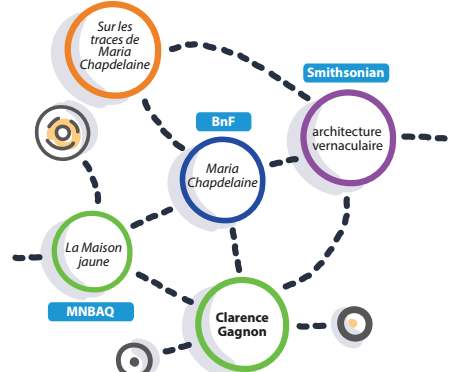
Collaborer au sein d’une même organisation, à travers les disciplines ou entre organismes favorise l’émergence d’idées novatrices et permet de surmonter des problématiques complexes. Travailler sur des données en diversifiant les perspectives permet de générer de l’information utile pour divers objectifs, domaines d’activité et types d’utilisateurs. C’est pourquoi des initiatives qui sont mises en oeuvre par des équipes pluridisciplinaires ont de meilleures chances de succès.
Travailler ensemble sur la valorisation ou la mise en commun de données, que ce soit au sein d’un même organisme ou en partenariat avec d’autres organisations, requiert l’adoption de véritables méthodes collaboratives, notamment, pour que des enjeux relatifs à la gestion des données et au processus décisionnel ne viennent faire obstacle à l’atteinte des objectifs. En s’éloignant des dynamiques de contrôle et de subordination habituelles, il est possible d’instaurer un climat de confiance et la cohésion nécessaires à un travail collaboratif.
Un vrai modèle collaboratif n’est pas centralisateur: chacun des contributeurs d’un système de traitement ou de mutualisation de données est responsable de leur production et de leur qualité.. Ceci a pour effet d’assurer une gouvernance équilibrée du système et le transfert et développement de compétences au sein de chacune des organisations.
Pour cela, il faut apprendre à élaborer des démarches de projets qui fédèrent les participants autour d’un objectif commun tout en reconnaissant les bénéfices individuels et les limites de chacun. Ainsi, les initiatives et projets peuvent profiter du partage de connaissances au sein de réseaux internes et externes.
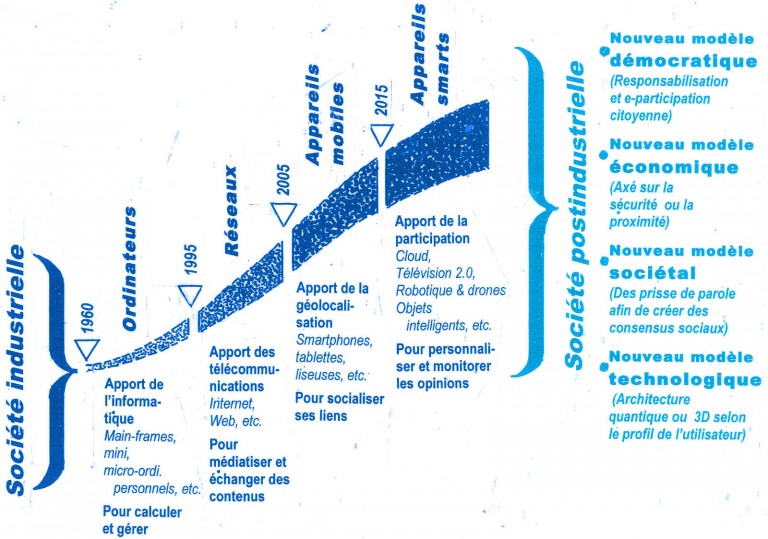
Pas d’évolution numérique sans maturité informationnelle
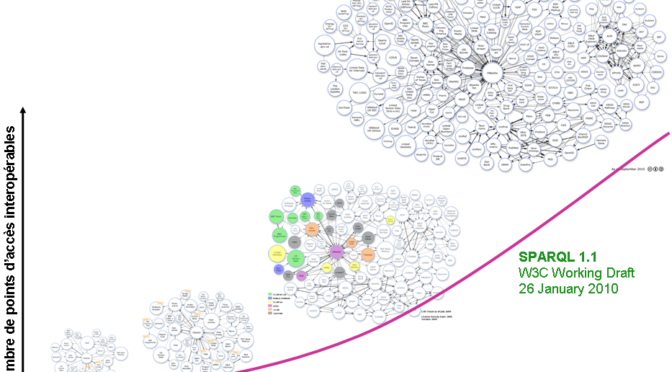
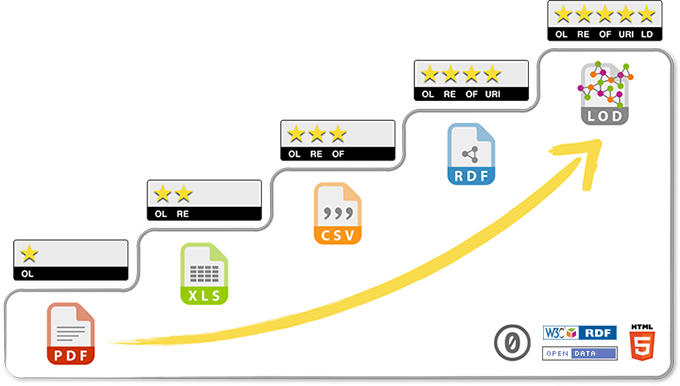
Voici la démarche des 5 étoiles du web des données, tel que conçue par Tim Berners-Lee et soutenu par les recommandations du W3C.
∗ Rendez vos données disponibles sur le Web (quel que soit leur format) en utilisant une licence ouverte.
** Rendez-les disponibles sous forme de données structurées (p. ex., en format Excel plutôt que sous forme d’image numérisée d’un tableau).
*** Utilisez des formats non exclusifs (p. ex., CSV plutôt que Excel).
**** Utilisez des URI pour identifier vos données afin que les autres utilisateurs puissent pointer vers elles.
***** Reliez vos données à d’autres données pour fournir un contexte. (Cote de degré d’ouverture des données, Gouvernement ouvert, Canada).
Voici l’échelle de la maturité informationnelle des organisations, telle qu’illustrée par Diane Mercier dans le cadre de sa thèse doctorale sur le web sémantique et la maturité informationnelle des organisations.
Thèse doctorale et références : Web sémantique et maturité organisationnelle sur Zotero.

Ces deux modèles participent de la même démarche graduelle et progressive vers l’ouverture et la participation, grâce à l’adoption de principes communs. C’est cette transformation que des initiatives numériques devraient permettre d’amorcer pour le bénéfice d’organismes et entreprises et, plus largement, pour la résilience d’un secteur d’activité ou d’un écosystème.