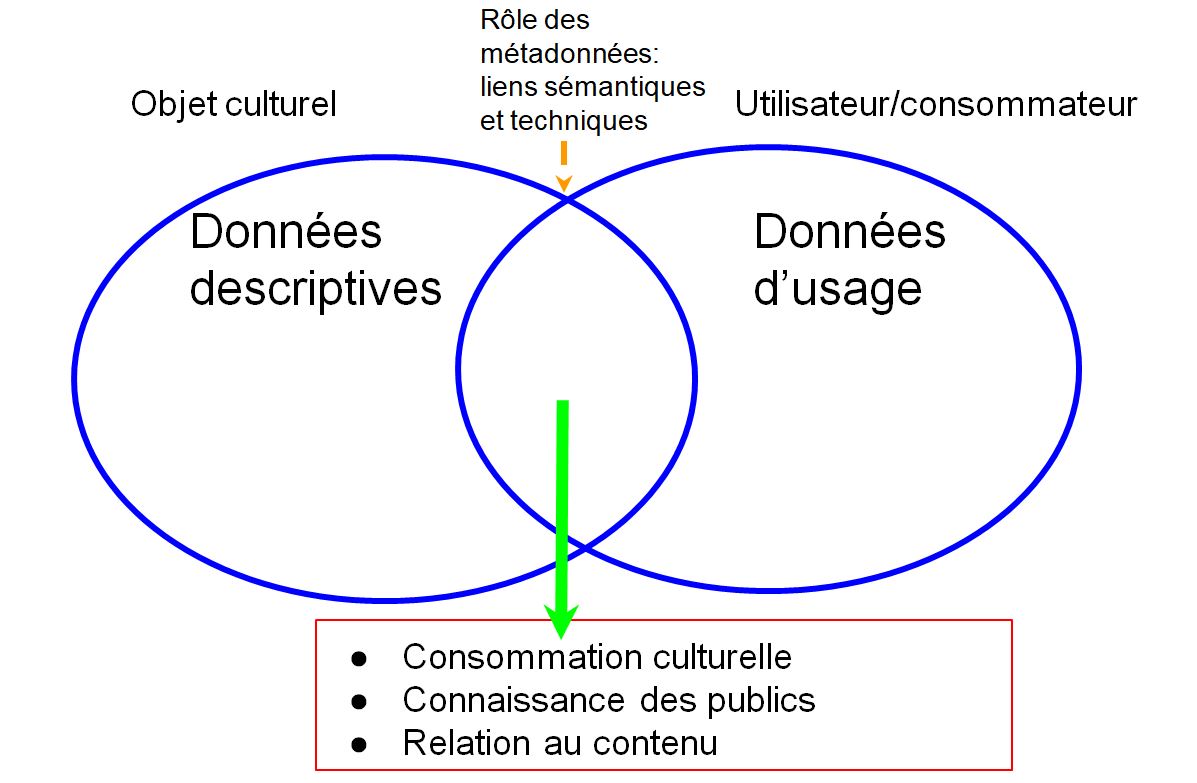
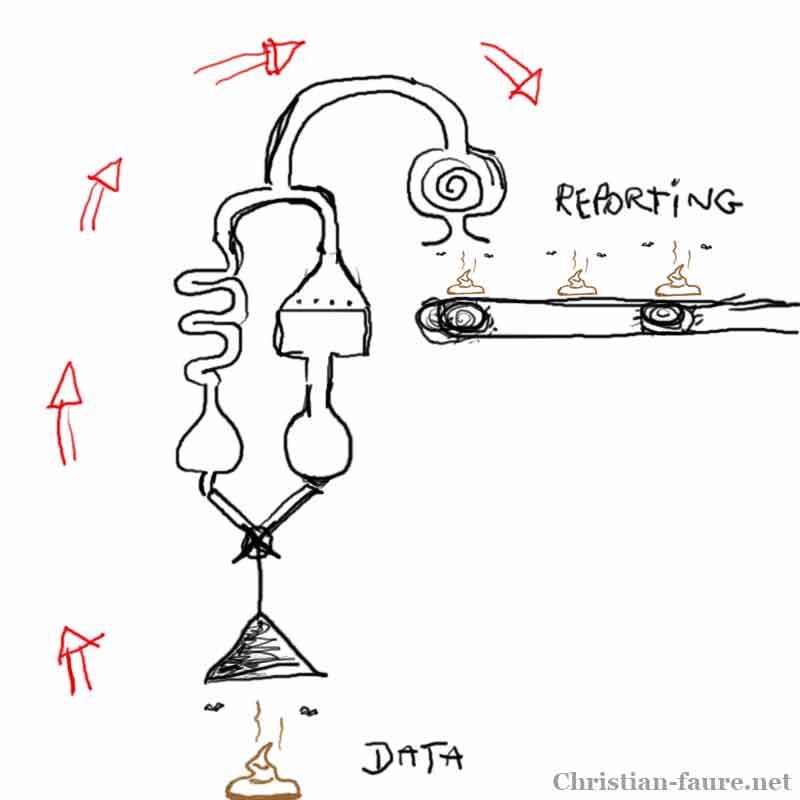
Les métadonnées, en culture, servent à décrire des choses pour les rendre repérables et à faire des liens d’association entre des éléments d’information pour générer de nouvelles connaissances. Voici trois enjeux pour la création de métadonnées culturelles qui devraient être abordés de façon prioritaire, au sein des organismes, institutions, entreprises et regroupements associatifs.
1. Mise à niveau de nos systèmes d’information
La problématique des métadonnées en culture origine de la conception des systèmes d’information. La source de la plupart des problème se situe en amont des processus de gestion de l’information, soit lors de la saisie des données dans un un système ou un logiciel qui n’a pas été conçu pour générer des métadonnées interopérables. Il est également plus facile de convaincre des gestionnaires d’investir dans un nouveau site web que dans un modèle de métadonnées normalisées et interopérables pour lequel il est difficile de fixer des indicateurs de rendement.
Qualité des données
Plus de 60% du temps de travail des experts des données est consacré au nettoyage et à l’organisation des données. Il est possible de produire des données qui soient exploitables, plus facilement et à moindre coût, en mettant en application des principes de qualité inspirés, par exemple, de ceux qui guident la production de données ouvertes et liées pour l’Union européenne.
De la base de données au web de données
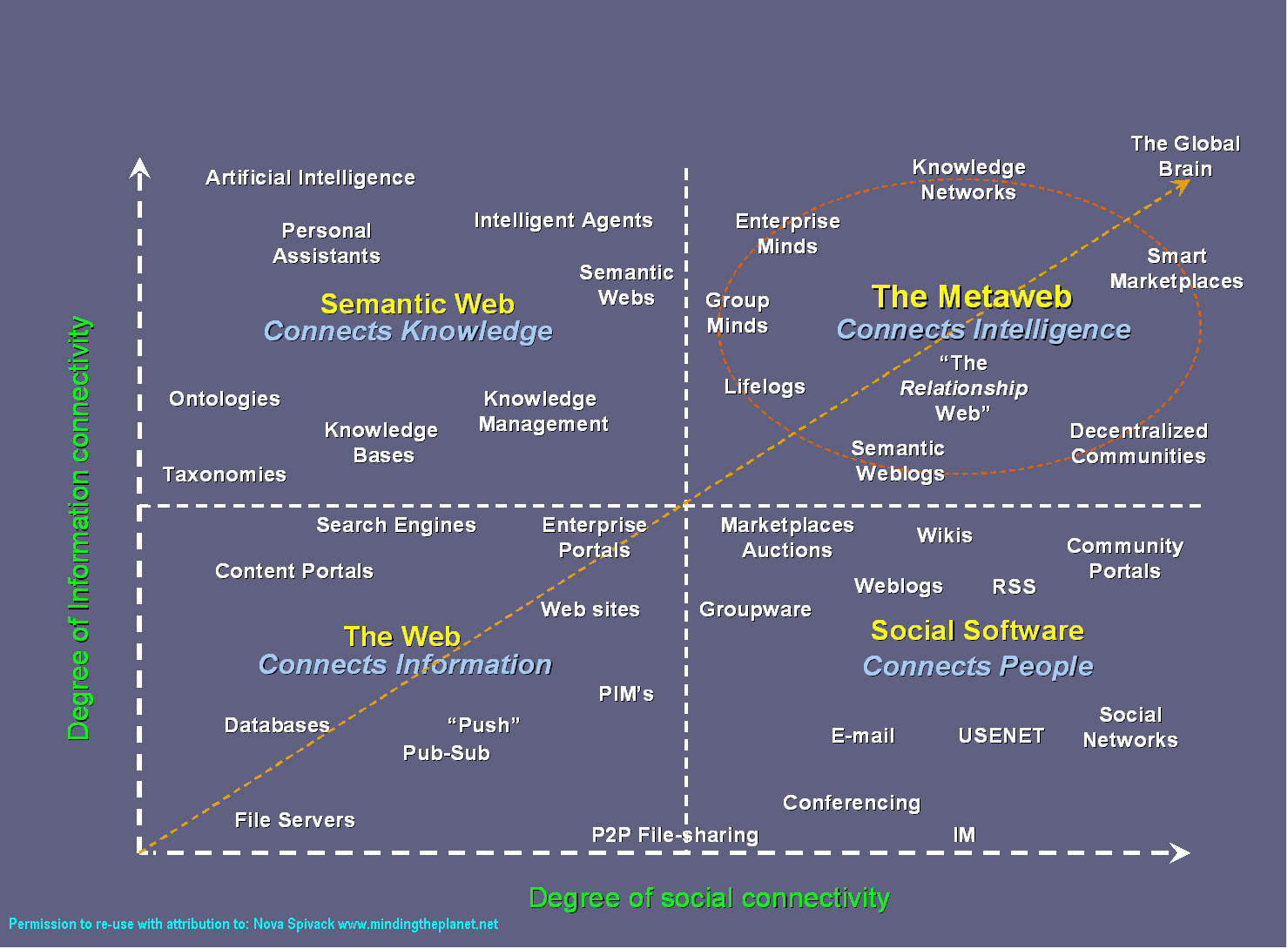
Au web des documents, s’est ajouté celui des données. Nous nous éveillons lentement à des modes de représentation et d’exploitation de l’information qui ne font plus référence à des pages, mais à des connaissances et à des ressources.
Dans le web, un contenu c’est de la donnée. Si les pages web s’adressant à des humains demeurent toujours utiles, ce sont les données décrivant des ressources (modèle Schema ou triplets du web sémantique) qui permettent à certaines technologies de classer et de relier l’information obtenue afin de nous fournir des réponses et, surtout, des suggestions.
Indexation de contenu et normalisation de données
Bien que des termes comme « métadonnées » et, même « web sémantique », se retrouvent désormais au programme de nombreux événements professionnels, au Québec et au Canada, trop rares sont les initiatives et projets où il est fait appel à des équipes pluridisciplinaires comme cela se fait au sein de gouvernements, d’institutions ou d’initiatives collectives, en Europe et aux États-Unis.
Est-il possible de réaliser des projets d’une complexité et d’une envergure que l’on peine à mesurer en dehors du cadre habituel d’un projet de développement technologique ? On peut en douter. Nous manquons de compétences en ce qui concerne la représentation de l’information sous forme de données liées, ainsi que sur les principes et méthodes de la documentation de ressources. Comment pourrions-nous, alors, atteindre des objectifs qui permettraient de tirer tous les avantages possibles des données qui décrivent nos contenus culturels ?
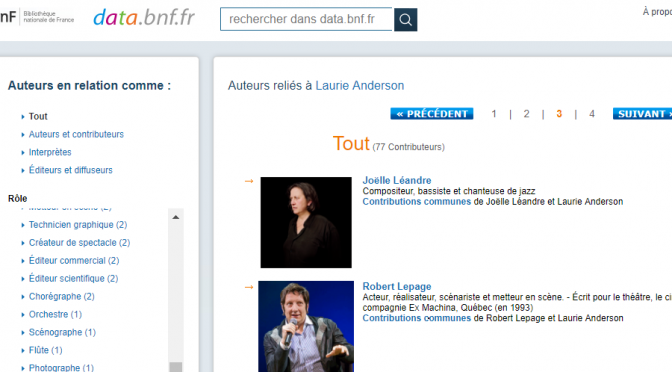
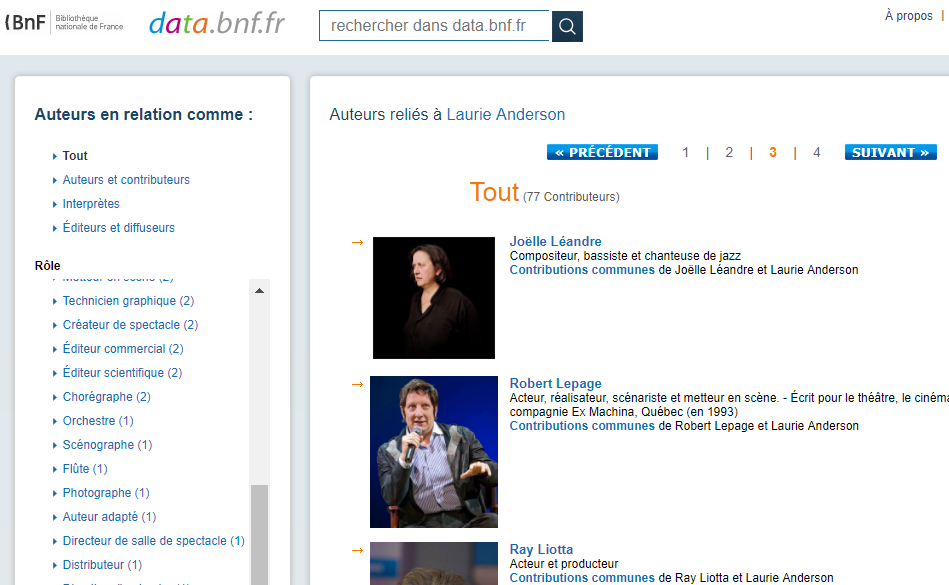
Plus concrètement, comment pourrions-nous entreprendre les démarches nécessaires à la réalisation d’objectifs similaires à ceux du projet DOREMUS qui réunit Radio France, Philharmonie de Paris et Bibliothèque nationale de France ?
«Permettre aux institutions culturelles, aux éditeurs
et distributeurs, aux communautés de passionnés
de disposer :
- de modèles de connaissance communs (ontologies)
- de référentiels partagés et multilingues
- de méthodes pour publier, partager, connecter, contextualiser, enrichir les catalogues d’œuvres et d’événements musicaux dans le web de données
Construire et valider les outils pédagogiques qui permettront le déploiement des standards, référentiels et technologies dans les institutions culturelles
Construire un outil d’assistance à la sélection d’œuvres
musicales.»
Il serait temps de moderniser les programmes de formation universitaire en bibliothéconomie et sciences de l’information et en technologies de l’information et d’encourager des intersections. Sans quoi, nous ne disposerons pas suffisamment de ressources compétentes pour passer du web des documents au web des données.
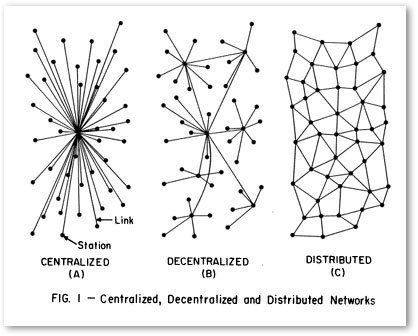
2. Décentralisation de la production de métadonnées
La centralisation de la production de métadonnées est contraire à la culture numérique car elle favorise généralement les perspectives et besoins d’une entité ou d’acteurs majoritaires. Les initiatives qui présentent le plus grand potentiel pour le développement de compétences en matière de production et réutilisation de données sont celles où les organismes sont appelés à participer activement à l’élaboration de leurs modèles de données, aux décisions en ce qui a trait à l’utilisation des données et à la conception de produits ou services. C’est par la pratique que les gestionnaires et entrepreneurs sont sensibilisés à l’utilité et à la valeur des données qu’ils produisent et qu’ils collectent.
Comme le signale Fred Cavazza, dans un récent billet, il nous faut réduire la dette numérique avant d’entreprendre une véritable transformation:
«Nommer un CDO, créer un incubateur, organiser un hackathon ou nouer un partenariat avec Google ou IBM ne vous aidera pas à vous transformer, au contraire, cela ne fera que reporter l’échéance. Il est donc essentiel de réduire la distance au numérique pour chaque collaborateur, et pas seulement les plus jeunes ou ceux qui sont directement impliqués dans un projet.»
À ce titre, externaliser l’indexation des ressources culturelles (production de métadonnées) ne saurait être considéré comme un choix stratégique dans une économie numérique puisqu’il éloigne les acteurs du traitement des données et les confine à des rôles de clients ou d’utilisateurs, sans opportunités d’apprentissage pratique. En effet, se pencher sur l’amélioration et la valorisation de données descriptives et de données d’usage est le meilleur moyen de développer une culture de la donnée et d’acquérir les connaissances qui permettent de transformer des pratiques et de se réinventer. En plus de responsabiliser les organismes et entreprises et d’assurer la découvrabilité numérique de leurs ressources, la décentralisation de la production de métadonnées renforce la résilience de l’écosystème; chacun des acteurs devenant un foyer potentiel de partage de connaissances et d’expérience.
3. Reconnaissance de la diversité des modèles de représentation
La centralisation de la production de métadonnées ne favorise pas la diversité des modèles de représentation et, plus spécifiquement, une réflexion post-colonialiste sur la description de productions culturelles et œuvres d’art, comme le lieu de fabrication ou la nationalité ou l’ethnie. Une démarche centralisée conduit à adopter un seul modèle de représentation des ressources, au détriment de la diversité des missions, des cultures, et des pratiques. Dans le domaine du patrimoine culturel, par exemple, il existe près d’une centaine de modèles de description différents. Tous ne conviennent pas à la production de données ouvertes et liées, mais il demeure que cette diversité des modèles est essentielle car elle répond à des besoins et contextes d’utilisation spécifiques.
C’est dans le même esprit, qui a permis au web de devenir ce qu’il est (voir « small pieces loosely joined » de David Weinberger, un des penseurs du web), qu’il faut s’entendre sur des principes et des éléments permettant de faire des relations entre différents modèles de métadonnées. Cette démarche comporte des enjeux de nature conceptuelle, technologique, voire même économiques et de politiques publiques. Face à un tel niveau de complexité, nous ne devrions pas tarder à rassembler, autour de ces enjeux, des spécialistes du développement d’ontologies et des questions d’interopérabilité des métadonnées.
*
Ce ne sont pas de nouveaux portails, plateformes et applications qui nous permettront de ne pas dépendre totalement d’entreprises se plaçant au-dessus des états eux-mêmes. Une « solution technologique » aussi extraordinaire soit-t-elle, ne remplace pas une vision et des stratégies. Surtout lorsque les modèles économiques, dont nous tentons d’imiter les interfaces sans en maîtriser le fonctionnement, reposent sur l’exploitation de données par des algorithmes et des technologies d’intelligence artificielle.