Jeu de mikado, Heurtelions [CC BY-SA], Wikimedia CommonsLe recours au « tout numérique », dans les circonstances de la crise actuelle entraînée par la pandémie, révèle de nombreuses inégalités. Qu’il s’agisse de l’enseignement à distance, de la dématérialisation des services publics ou, même, du traçage des personnes, les propositions de « solutions » tiennent généralement pour acquis que l’informatique connectée est à la portée de tout le monde. Nous devons éviter les écueils de la transformation numériques que sont le solutionnisme et la création d’inégalités numériques.
Imaginer nos propres solutions
J’ai élaboré, dans un précédent billet, sur le piège du solutionnisme technologique: « Ce ne sont pas des plateformes numériques qui ont permis à Netflix et compagnie de bouleverser l’industrie. C’est d’avoir compris le potentiel du Web et pensé autrement l’accès, la distribution et la production de contenus audiovisuels, en osant remettre en question les modèles établis.»
Cette expression peut s’appliquer au sentiment d’urgence qui nous pousse vers le développement d’un outil avant même d’avoir défini le problème, exploré les causes possibles et analysé les systèmes sociaux et techniques.
Il ne faut pas tomber dans ce piège et nous contenter de reproduire des stratégies et des outils qui ont été conçus pour servir d’autres objectifs que les nôtres.
Internet pour réduire les inégalités
Voici quelques éléments qui favoriseraient la transformation numérique, en commençant par la condition de base:
Accès Internet sur tout le territoire.
Accès Internet à la maison (gratuit ou à coût modique).
Bande passante nécessaire pour l’accès de qualité à du contenu audiovisuel.
Ordinateur à la maison (échapper aux coûts de l’obsolescence programmée, promouvoir les logiciels libres). Équipement en nombre suffisant pour les besoins d’une famille confinée.
Connaissances informatiques et habiletés numériques suffisantes (autonomie des utilisateurs, sécurité informatique, protection de la vie privée).
Équipement adapté et logiciels et contenus web accessibles aux personnes en situation de handicap temporaire ou permanent.
Service de médiation: outils d’accès –et de contribution– à la connaissance et à la culture, littératie de l’information (bibliothèques publiques, initiatives citoyennes).
Commerçants, fonctionnaires, profs et professionnels ayant des compétences numériques suffisantes ou les ressources nécessaires pour offrir un bon niveau de services en ligne.
Amélioration du niveau d’alphabétisation (compréhension des consignes d’utilisation des services en ligne et des instructions techniques).
Technologies plus simples, accessibles et durables
Dans une tribune, Jean-François Marchandise, cofondateur de la Fondation Internet nouvelle génération, partage ce constat sur le besoin de médiation numérique :
Aujourd’hui, une grande partie de l’innovation numérique repose sur un numérique de luxe. Nous allons vers des « toujours plus », adaptés à un monde en croissance éternelle et en ressources infinies…
A contrario, il va davantage falloir composer avec un numérique moins high tech, qui puisse fonctionner avec trois bouts de ficelle, de manière plus décentralisée, avec une moindre dépendance au lointain, une relocalisation des savoir-faire.
De plus, si tous les citoyens sont égaux, ne devrions-nous pas élaborer des propositions numériques en fonction du plus bas dénominateur numérique commun ?
Pilotage d’initiatives et intelligence collective
Cette pandémie devrait nous faire réaliser que nous devons changer nos méthodes de travail et prendre garde aux inégalités numériques et au solutionnisme technologique.
Si nous souhaitons tirer des apprentissages constructifs de la complexité de cette situation, nos équipes de projets doivent être interdisciplinaires et nos analyses doivent tenir compte de l’interdépendance des systèmes. Les outils de communication et de travail collaboratif peuvent faciliter la circulation des idées. Cependant, seule une réelle transformation du pilotage des initiatives numériques, vers une forme d’intelligence collective, pourrait les rendre plus efficaces et accroître leurs bénéfices.
Pour que le Québec puisse se relever le plus rapidement de cette crise, l’ensemble de la société doit participer à la création de valeur (savoir, culture, industrie). Et pour cela, il faudrait d’abord réparer la fracture numérique, faire de l’accès Internet un service public essentiel et apprendre à piloter des projets dans la complexité.
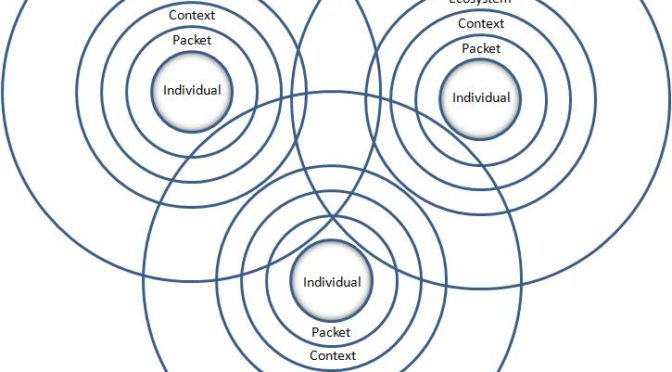
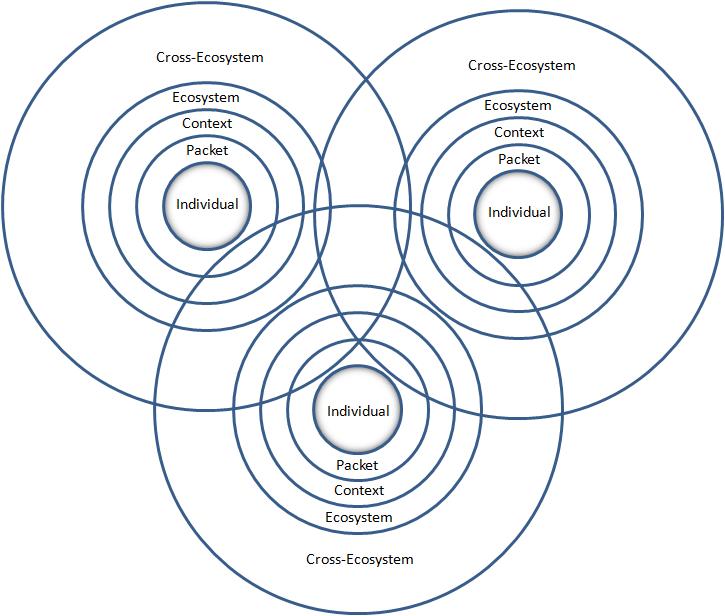
Concept de « pertinence », dans un écosystème numérique. GinsuText [CC BY-SA 3.0], Wikimedia CommonsFavoriser la visibilité des contenus culturels québécois en ligne n’est pas une question de technologie. Les solutions technologiques, quelles qu’elles soient, ne peuvent améliorer la qualité de l’information. À ce titre, je ne parle pas des bases de données. Leur absence de traitement documentaire adéquat est connue. Je parle du contenu de sites web que même la présence de balises Schema n’arrive pas à rendre plus exploitable par des moteurs de recherche.
Structurer l’information autour d’entités repérables
Pourtant, plus de vingt ans après la naissance du web, la conception de sites est encore largement influencée par la production de documents imprimés. Si la forme et le design se sont adaptés aux modes et aux supports, la structure et la conception de l’information n’ont pas bougé. Nos sites sont encore conçus pour être lus par des humains.
Voici quelques éléments qui sont essentiels pour faciliter le repérage d’entités (personnes, organisations, œuvres, lieux, événements) par des moteurs de recherche et autres applications.
Un site pour être dans le web
Un site web est au centre d’un écosystème numérique. C’est une adresse où se trouve de l’information accessible selon des standards universels et ouverts. C’est également un espace de publication qui n’est pas assujetti à d’autres objectifs que ceux de son propriétaire. Constitué de pages et de documents reliés entre eux et à d’autres sites web par des hyperliens, il peut se trouver sur le parcours d’utilisateurs et de moteurs de recherche. Un site web marque l’existence d’une entité dans cette application qui opère sur l’Internet et qui s’appelle le Web.
Ne compter que sur des réseaux sociaux pour avoir une présence numérique est une pratique qui réduit le potentiel de rayonnement et de découverte de nos contenus culturels.
Une URL pour chaque offre
Le développement des moteurs évolue rapidement vers le repérage et l’interprétation d’entités nommées (noms propres ou expressions définies comme un événement) dans des données non structurées. Pour faciliter le repérage d’un événement ou d’une œuvre, il faut lui attribuer une page spécifique. Publier plusieurs offres dans la même page ne permet pas à une machine de traiter adéquatement l’information qui y est présente. L’unicité et la persistance de l’URL signalent la présence d’une entité «événement» ou «œuvre» qui est liée à l’entité organisation.
Des mots qui connectent avec des publics
L’intégration des balises du vocabulaire Schema.org permet d’identifier des types d’offres et de générer des aperçus, ou résultats enrichis, dans certains cas d’usage (expressément non garanti par Google). Celles-ci ne permettent cependant pas aux moteurs de recherche de différencier une offre d’autres offres similaires. Ce sont alors des mots (description, titre, caractéristiques) qui peuvent générer des liens entre l’information recherchée par des utilisateurs et les données non structurées qui sont présentes dans la page web.
Le choix des mots employés est stratégique parce que ceux-ci peuvent être utilisés pour fournir une réponse plus précise à une question (et cela, tant dans le contenu d’une page que dans le balisage qui est intégré dans son code HTML). Il s’agit d’établir des connexions avec les vocabulaires et intérêts des publics cibles et de rendre le contenu indexé unique ou le distinguer d’autres contenus similaires.
Des images qui parlent et font du lien
Parmi les conditions qui facilitent le traitement de l’information par les moteurs de recherche, on ignore trop souvent celles qui concernent les images. Une page qui comprend une image sera préférée à une autre qui n’en a pas. Si des liens, dans le code HTML de la page, fournissent un accès à des fichiers contenant trois résolutions de cette image (1X1, 4X3, 16X9), le contenu sera assurément exploitable. dans des résultats de recherche et sur de petits écrans. Notez que l’optimisation des images est automatiquement prise en charge par certains systèmes de gestion de contenu et certains thèmes de WordPress.
Nommer le fichier d’une image en utilisant des mots qui sont pertinents avec la description de son contenu en facilite l’exploitation et la gestion.
Des liens pour relier des entités nommées
Ne pas faire de liens, hors d’un site web, afin d’y retenir les internautes nuit au rayonnement. Le déploiement de liens entre les acteurs concernés par la création, production et diffusion d’un contenu culturel souligne la présence numérique de chacun. La simple présence de liens vers des sources d’information externes enrichit l’information tout en favorisant des découvertes. Par exemple, relier des entités nommées autour d’une production audiovisuelle (œuvres musicales, lieu historique, réalisatrice et d’acteurs) améliore leur potentiel d’être découvertes par des humains et des machines.
Des sites web pour construire un réseau d’hyperliens
Le rayonnement et la découverte de nos contenus culturels sur le web dépendent, avant tout, de l’organisation et de la structure de l’information sur nos sites web. Ne pas avoir son propre site, c’est ne pas faire partie du web ouvert, interopérable et de plus en plus interprétable par des machines. C’est également laisser à d’autres le soin de parler de vous. Mais, c’est surtout, renoncer aux moyens les plus simples et accessibles (vous rappellez-vous les blogolistes ou « blog roll » ?) que nous ayons pour relier les personnes, les organisations, les œuvres, les événements et les lieux, sur nos territoires et sur tout le Québec.
Mais si l’amélioration de la qualité de l’information numérique repose sur de meilleurs sites web, faudrait-il alors revoir les programmes de financement qui en excluent le développement ?
Les acteurs culturels doivent-ils devenir spécialistes de l’information numérique ?
Les fournisseurs de services web ne sont-ils pas en première ligne lorsqu’il s’agit de conseiller et de réaliser des projets pour les acteurs culturels ? La même question se pose concernant les exigences de découvrablité des programmes de financement. Où sont les compétences nécessaires pour offrir un accompagnent qui soit susceptible d’apporter des améliorations notables ?
Nécessaire mise à jour des connaissances et des programmes de formation
En l’absence de connaissances formalisées et de méthodes pédagogiques pour améliorer la littératie de l’information numérique (car c’est bien de cela dont il s’agit), le milieu culturel est laissé à lui-même. Il fait face à une variété d’interprétations, d’approches et de propositions stratégiques et technologiques dont il n’est pas en mesure d’évaluer l’exactitude, la pertinence ou le rendement potentiel.
Il serait donc urgent de réunir des représentants des domaines des sciences de l’information et des technologies numériques, des secteurs industriels et académiques, afin de proposer une mise à jour des compétences et des formations.
Les utilisateurs préfèreraient-ils une encyclopédie ou un répertoire commercial?
Notre focalisation sur le marketing et les solutions technologiques est-elle un risque pour la diversité culturelle ? L’absence de vision partagée et la course aux résultats peuvent-elles faire perdre aux acteurs de la culture la maîtrise stratégique des choix en matière de diffusion et d’accès ?
Nous espérons des solutions mécanistes qui accroîtront la consommation en imposant des offres culturelles à la façon des vieux modèles publicitaires. La mise en données de contenus culturels ne doit pas nous faire oublier qu’il appartient à chacun de réaliser la partie la plus stratégique d’un projet numérique : décider de la façon dont une chose (une œuvre, par exemple) doit être documentée et déterminer ce qui la relie à d’autres informations dans le web des données.
L’emploi du mot « initiative », de préférence à « projet », souligne l’importance de la démarche et des apprentissages, par rapport à la livraison d’un outil ou la modernisation d’un système. Voici comment nos initiatives pourraient être plus marquantes.
Miser sur l’éducation et l’accès à la culture
Le marketing peut entraîner la consommation de produits et services culturels, mais ce sont l’éducation et l’accès à la culture qui peuvent faire découvrir et apprécier la culture. Or, il faudrait une plus grande porosité entre les politiques et projets éducatifs et culturels pour miser sur l’environnement familial et social pour faire connaître la culture.
Il faudrait également donner un rôle plus actif, dans nos plans et initiatives numériques, aux médiateurs de proximité que sont les professionnels des bibliothèques publiques et scolaires.
Privilégier les initiatives qui favorisent la diversité
Nous cherchons, par tous les moyens, à ce que la culture locale soit vue et consommée, de préférence à d’autres offres. Nos propositions techniques partagent cependant les défauts des plateformes dominantes. Qu’il s’agisse de baliser des contenus pour les moteurs de recherche ou de créer de nouvelles bases de données interrogeables, la façon dont sont conçues ces « solutions » technologiques nuit à la diversité des offres culturelles.
La centralisation des décisions et du traitement de l’information renforce l’uniformisation.
La popularité comme principal critère de sélection défavorise les contenus de niche, les cultures et langues en situation minoritaire dans un répertoire, sur un territoire ou par rapport au reste du monde.
L’uniformisation du traitement documentaire, par l’imposition d’une méthode de classification, de vocabulaires et de référentiels spécifiques, appauvrit la qualité de l’information. Par conséquent, elle en diminue l’intérêt et la valeur pour différents publics. Les initiatives de décolonisation des modèles descriptifs tentent de réparer les ravages du rouleau compresseur de l’uniformisation sur la citoyenneté culturelle des peuples autochtones.
Les systèmes de recommandations et de personnalisation des offres culturelles reposent sur la similarité des produits et services ou sur la similarité des profils des utilisateurs.
Ne pas céder des choix stratégiques
À l’arrivée de l’informatique, nous avons confié l’organisation de l’information à des systèmes de bases de données, selon les termes d’entreprises. Il est temps de remettre, selon nos propres termes, cette intelligence dans nos sites web et, plus spécifiquement, dans nos catalogues, collections, répertoires, fonds et archives. Nous ne devrions pas abandonner la création de sens et de liens à des opérateurs de plateformes et à des fournisseurs de services.
Être trouvé ou découvert et laisser des traces numériques sont les fruits d’un travail de documentation. Celui-ci est trop souvent escamoté par la recherche d’une solution technologique. De plus, les façons de décrire des productions ou des offres culturelles offrent peu de possibilité de mettre celles-ci en relation avec des intérêts et des passions.
Par exemple, les catalogues et répertoires en ligne pourraient grandement améliorer l’expérience des utilisateurs en devenant des bases de connaissances interactives et interconnectées. Il serait ainsi possible d’intégrer de nouvelles informations et des liens vers d’autres ressources grâce aux contributions de chercheurs et d’amateurs.
Documenter: laisser des traces, créer du lien et faire sa marque
Documenter la culture et rendre cette information pertinente, attrayante et utile pour divers publics et usages sont la responsabilité de tous les acteurs du milieu culturel. Il manque une méthode de travail et des outils faciles à utiliser pour réaliser, en équipe ou avec des partenaires, l’évaluation de l’information publiée sur le web et le choix des métadonnées qui feront des liens entre les offres culturelles et les publics cibles.
C’est dans cette perspective qu’a été conçu un guide destiné aux artistes et aux organisations du milieu de la danse. Cette approche, en trois étapes (stratégie, information, technologie) repousse les choix technologiques à la toute dernière étape afin de remettre la documentation de la danse à ceux et celles qui la font.
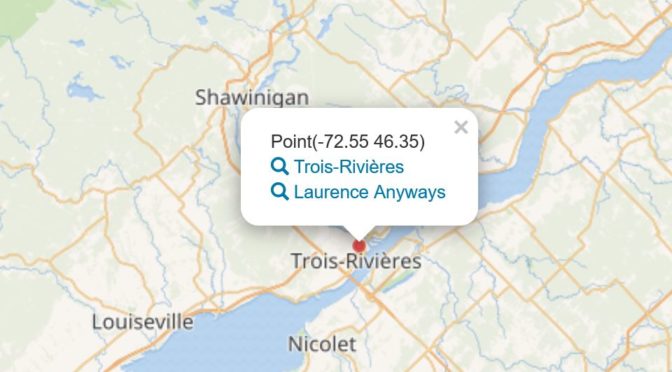
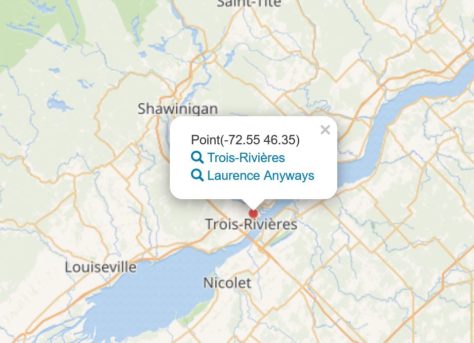
Wikidata, exemple de requête : cartographie des films et des lieux où se déroule l’action.
Mise à jour 2019-10-02: ajout d’un exemple récent d’initiative à fort potentiel transformateur.
La tendance zéro clic se confirme. Les moteurs de recherche fournissent dans leurs propres interfaces, des réponses, à partir de données collectées sur des sites web. Ils sont ainsi les principaux bénéficiaires de l’information que nous structurons afin de rendre nos offres plus visibles.
Partenariat inéquitable
De plus, en développant des interfaces d’information spécialisées (voyage, musique, musées, entre autres), ils se substituent aux agrégateurs et portails traditionnels. Cette désintermédiation est particulièrement dommageable pour les structures locales qui produisent de l’information. Celles-ci sont privées de données d’usage qui leur permettraient de mieux connaître leur marché et de s’ajuster à leurs publics.
Effacement de la diversité culturelle
Donc, lorsque nous décrivons nos offres à l’aide de données structurées, sur le modèle Schema.org, et de services comme Google Mon entreprise, nous travaillons pour des moteurs de recherche. De plus, nous nous conformons à un vocabulaire de description, une classification et une vision du monde uniques. Ce constat est un problème pour la diversité culturelle, surtout pour les groupes ethniques et linguistiques en situation minoritaire.
Que faire ? Fournir un service minimum
Cependant, ne pas décrire nos offres avec des balises sémantiques équivaut à refuser de faire indexer nos pages web par les robots des moteurs et, par conséquent, à rendre nos offres et nos contenus invisibles et incompréhensibles pour Google, Bing, Yahoo! et Yandex (moteur de recherche russe).
Tout d’abord, il faudrait donner un « service minimum » aux moteurs de recherche en fournissant uniquement l’information qui est exigée pour certaines offres. Google publie des instructions concernant les balises à renseigner, ainsi que les éléments de contenu à publier pour divers types d’offres.
Attention, Schema.org n’est qu’un vocabulaire. Ce n’est pas Google. Les moteurs de recherche exploitent les balises selon leurs propres règles. Celles-ci évoluent fréquemment, notamment, pour certains types de contenus. Par exemple, Google annonce clairement ses préférences, dans le domaine du livre, en réservant son attention aux distributeurs qui utilisent les balises selon ses instructions.
Que faire d’autre ? Aller vers le web des données
Nous mettons les moteurs de recherche et plateformes commerciales au centre de nos projets. Cependant, nous n’en maîtrisons pas le fonctionnement et nous n’avons aucun moyen de contrôle sur leur développement. Nous y investissons beaucoup d’efforts afin de positionner nos offres dans l’espoir d’accroître la consommation.
Et si nous élargissions notre définition de la découverte plutôt que de la centrer sur des activités de promotion? Ne pas nous limiter à la finalité économique de l’utilisation des données nous permettrait d’en embrasser le plein potentiel pour le développement de la culture et de l’éducation. Si nous choisissions de développer des initiatives en dehors des systèmes contrôlés par les acteurs dominants de l’économie numérique, nous pourrions être plus ingénieux et, finalement, créer plus de valeur pour nos propres écosystèmes.
Accroître le potentiel de la découverte passe par la décentralisation de la gestion de l’information, le partage de connaissance sous forme de données ouvertes et liées, selon les standards du web et par une redistribution plus équitable du pouvoir décisionnel. Wikipédia, Wikicommons et Wikidata, qui sont des projets de la Wikimedia Foundation, exemplifient ce modèle contributif qui donne à chacun la possibilité de participer au contenu et à la gouvernance.
Inventer d’autres formes de découverte
Tous les acteurs du domaine culturel n’ont pas les compétences et les ressources requises pour évaluer, modéliser et connecter des données avec les technologies du web sémantique. Wikidata constitue une option plus accessible: le référentiel, le mode de gouvernance et l’infrastructure n’ont pas à être développés. Ceci a pour principal avantage d’expérimenter rapidement la production et l’utilisation de données liées.
Les requêtes préconstruites qui permettent d’interroger les données de Wikidata offrent un aperçu du potentiel d’un projet contributif pour la valorisation de l’information. Par exemple, la requête 6.16 qui permet de cartographier tous les films en fonction du lieu où se déroule l’action. Lancez la requête en cliquant sur le pictogramme (flèche blanche sur fond bleu) à la gauche de l’écran. Les données des films localisés au Québec ne sont pas exhaustives et sont souvent imprécises (information incomplète, lieu fictif).
Si d’autres sources d’information étaient disponibles sous forme de données liées, on pourrait imaginer une interface où se croiseraient des images des lieux, des biographies d’acteurs et actrices ou des titres de chansons.
*** Mise à jour 2019-10-02
Voici un autre exemple d’initiative qui prend sa source hors des règles imposées par les moteurs de recherche et plateformes. Il s’agit de projets réalisés avec Wikipédia par le Musée national des beaux-arts du Québec. Cette initiative est à la fois, une contribution du musée à la connaissance mondiale, tout en permettant à l’institution d’explorer le potentiel du liage de données, de rejoindre des publics qui ne fréquentent pas de musées et de donner prise à une culture du réseau dans l’organisation. Nathalie Thibault, archiviste au MNBAQ, en mentionne les effets marquants:
Un des impacts positifs de ce chantier a été de bonifier la présence d’œuvres dans des collections d’autres musées au Québec et au Canada dans les articles bonifiés et non pas juste le MNBAQ. Nous souhaitons collaborer avec les autres musées du Québec, car les articles améliorés sur les artistes du Québec serviront certainement à d’autres institutions muséales.
***
En conclusion, il est souhaitable que nous ayons une alternative aux grandes plateformes pour développer nos compétences et mettre en valeur nos collections, catalogues, fonds et portfolios. Il faut cependant favoriser les initiatives qui ciblent des résultats marquants et transmissibles tels que la décentralisation des prises de décision, l’abolition des silos organisationnels et la mise en commun de données.
Mais ceci servira surtout à améliorer la quantité de données contenues dans son graphe de connaissances (knowledge graph) et d’étendre son influence sur ce que nous voyons sur le web.
Intégration d’information collectée sur le web dans le graphe de connaissances de Google. Source: SEO by the Sea.
Bill Slawski est un spécialiste de l’optimisation pour moteurs de recherche. Sa formation de juriste lui permet de porte une attention particulière aux demandes de brevet. Il en commentait une, récemment, qui fait référence au développement du graphe de connaissances (knowledge graph) de Google. Elle concerne l’intégration, dans son graphe, d’information collectée sur le web, afin d’accroître la masse de données :
The patent points out at one place, that human evaluators may review additions to a knowledge graph. It is interesting seeing how it can use sources such as news sources to add new entities and facts about those entities.
Comme chez les autres entreprises dont le modèle d’affaires repose sur la donnée, une grande partie du traitement de l’information et de la production de données résulte du travail non rémunéré d’amateurs et passionnés:
How can you teach an algorithm to understand all these distinctions? Gingras said Google is doing so through its Quality Raters, a global network of more than 10,000 individuals who offer feedback on Google’s search results, which in turn is used to improve the company’s search algorithms.
Ceci sert-il les intérêts du journalisme ? Probablement, mais il est trop tôt pour le vérifier. Cela sert surtout à développer une connaissance très poussée de nos rapports à l’information et de permettre à d’autres d’influencer notre vision du monde et de fabriquer des opinions. S’informer sur le scandale Facebook – Cambridge Analytica devrait nous faire prendre la mesure de l’intervention de ces systèmes dans notre développement social, notamment, la fabrication d’opinions et d’antagonismes.
Dans un billet sur les enjeux des métadonnées, en culture, j’avais fait référence à la dette numérique. Fred Cavazza emploie cette expression pour qualifier les conséquences qui pèsent sur les organismes qui tardent à s’adapter adéquatement au changement.
Dette ou déficit numérique ? Cette question soulevée par un commentaire de Catalina Briceno, sur LinkedIn, est bien autre chose qu’un effet de style:
« notre dette numérique s’accroît »… j’espère que tu as raison. J’espère c’est bel et bien « une dette ». Cela sous-entendrait qu’il y a une capacité de « retour à niveau »… j’espère que ce n’est pas carrément un déficit… une perte pure… d’opportunités, de connaissances et de capacité d’action.
Elliott Brown [CC BY 2.0], Wikimedia CommonsL’observation de Catalina met au jour un ensemble de questions qui témoignent de la complexité d’une problématique qui fait pression sur la culture et les médias depuis plus de 10 ans. Pour preuve, le sujet de ce billet sur le renouvellement du journalisme au secours des médias, n’a pas pris de rides.
Face aux pressions du changement, nous produisons des rapports et nous consultons. Cependant, nous revenons invariablement aux solutions techniques et réglementaires qui font l’effet de la énième mise à jour d’un logiciel. Un logiciel qui ne serait plus ergonomique, et qui serait de moins en moins compatible avec de nouveaux usages et environnements.
Catalina faisait suite à ma publication, sur LinkedIn, concernant l’exploitation des données par les GAFA. Je souhaitais alors étayer un commentaire que j’avais partagé en appui à une perspective de Stéphane Ricoul, concernant la crise des médias. Nous avons de trop rares occasions d’échanger des points de vue, hors de nos milieux respectifs. Je consigne ici, ma réponse à Catalina et les préoccupations qui accompagnent la plupart de mes missions.
Catalina, ce sera très probablement un déficit si nous persistons à financer des solutions de marketing (tablette, portail) pour résoudre des problématiques qui sont complexes et tranversales.
Nous nous contentons actuellement d’imiter les outils des entreprises qui, elles, ont investi dans du capital intellectuel et mis des années à développer d’autres modes de fonctionnement et de création de valeur. Comment être aussi efficaces et attrayants (même pour nous, investisseurs boursiers), alors que notre compréhension du phénomène numérique est parcellaire et, trop souvent superficielle ?
Nous tentons de préserver une structure industrielle et des fonctionnements qui ne sont plus alignés sur nos propres ambitions économiques et sociales. Parvenir, un jour, à encaisser les taxes des GAFAM, ne compensera pas l’absence de vision et la perte de connaissances.
Nos propres concurrences internes jouent contre nous, alors que nous faisons face à des entités unicéphales. Il faudrait élever le niveau de connaissances et élaborer une vision globale (et non sectorielle) et des actions transversales sur l’ensemble de nos activités.
Nous risquons, effectivement de faire face à un déficit numérique. Nous vivons dans une économie qui repose sur notre capacité à consommer toujours plus, et donc, à nous endetter. La dette (ou le déficit) numérique devient-elle, à nous yeux, aussi normale et naturelle que l’usage d’une carte de crédit pour contenter notre désir de bien-être ?
Capture d’écran « gVIM with 42 help », Wikimedia Commons
Mise à jour 2019-09-07: ajout, à la fin du billet, d’information concernant les cas d’usage, suite à un commentaire exprimé sur Facebook.
Produire et réutiliser des données descriptives, ce n’est pas travailler sur une solution, mais sur des questions.
Quelle est la finalité du projet ?
Comment savoir si les données d’une organisation ou d’un collectif ont un fort potentiel informationnel ? Comment ces données peuvent-elles répondre à des questions qui demandent de faire des liens entre des entités et d’interpréter des relations ? Si ces données ne sont pas suffisamment riches en information, comment les lier avec celles provenant d’autres sources, ouvertes et privées, pour les valoriser ?
La finalité de projets de données est de générer l’information la plus riche afin de répondre à des questions à la satisfaction des publics cibles. Toute initiative devrait donc débuter par un diagnostic de la disponibilité et de la qualité des données. Cependant, comment effectuer un tel exercice sans savoir à quels besoins répondront-elles ou, plus exactement, à quelles questions devront-elles répondre ?
Trouver les bonnes questions: la dimension cognitive des projets
La dimension cognitive des projets numériques se rapporte à la sélection, l’organisation et le traitement de l’information. Ces activités doivent réunir des perspectives et compétences diversifiées: de la connaissance du domaine et des publics à la modélisation de l’information. Il s’agit d’un travail collaboratif qui doit être réalisé en amont de la conception technique. Cette étape est rarement bien planifiée et réalisée, faute de budget, ressources ou méthode de travail. Pourtant, elle constitue le coeur du projet. C’est, de plus, un processus qui permet d’améliorer la littératie numérique et développer des pratiques collaboratives au sein d’une organisation et d’un partenariat.
Interroger les données: repenser les vieilles interfaces
Les vieux modèles d’interfaces de recherche influencent notre conception des questions que nous posons aux ensembles de données. Elles forcent les utilisateurs à formuler leurs questions en fonction de critères limités. Ces interfaces pré web qui sont encore utilisées pour donner accès au contenu de catalogues en ligne sont nettement déclassées par la recherche en langage naturel.
Cocher des critères comme la date, l’auteur, le sujet ou le titre ont assez peu à voir avec les comportements et besoins des utilisateurs. L’indexation des contenus et le paramétrage du moteur de recherche des sites sont généralement peu élaborés. Par exemple, explorer les archives du journal Le Devoir est plus intéressant à partir de l’interface de Google. Il suffit de limiter la recherche au site et d’ajouter des expressions ou, même, des questions , comme ceci: « site:https://www.ledevoir.com/ causes du changement climatique ». On peut alors explorer les textes, images et vidéos. Les traces de nos usages ne serviront cependant pas les intérêts du média, mais le modèle économique du moteur de recherche.
Remplacer les cas d’usage par une approche narrative
Avant de développer de nouvelles plateformes, il y aurait place à amélioration pour répondre aux besoins d’information spécifiques des publics et accompagner le développement de services à valeur ajoutée.
Mais trouver les bonnes questions à poser requiert une connaissance des publics cibles et, pourquoi pas, leur participation. Pour cela, il convient de remplacer l’approche technologique (cas d’utilisation) par une approche narrative, plus concrète et plus proche du phénomène informationnel (lier des données pour raconter une histoire).
When we frame information about an object we focus attention on certain aspects of that object or its history. It’s just like choosing a new frame for a painting, which then highlights different qualities of the artwork. Framing is less about the information we feature in a label and more about how we present that information.
Notre relation aux contenus culturels est de l’ordre du ressenti, du goût et des intérêts. Cependant, nos bases de données et catalogues fournissent une information factuelle, organisée de façon uniforme et anodine, bien loin de la diversité des cultures et expériences humaines. D’autres métadonnées pourraient jouer un rôle aussi important que les métadonnées classiques de type catégorie-titre-auteur, pour la personnalisation des services et pour l’analyse des données d’usage.
Indexation – Émotions – Archives, la recherche menée par Laure Guitard, se rapporte plus spécifiquement à l’enrichissement des modèles de données par la représentation de la charge émotionnelle des contenus et objets (page 151).
l’indexation – professionnelle et collaborative – pourrait permettre d’inclure l’émotion dans la description des archives afin que cette dernière soit reconnue comme une clé d’accès aux documents
Je souligne, avec cette référence, l’importance de la recherche académique et des regards croisés entre domaines d’étude pour apporter de la profondeur à des idées. Les monocultures sectorielle, disciplinaire et technologique nuisent à nos ambitions numériques.
Renforcer le volet cognitif des projets
Il faut revoir des modèles d’indexation de contenu, ou de production de métadonnées. Disposer de données plus riches permet d’analyser la relation de l’utilisateur au contenu, de mieux connaître les publics, de développer des algorithmes de recommandation et, finalement, d’imaginer d’autres façons de valoriser des catalogues, fonds et répertoires.
Nous ne devons pas nous laisser démonter par la complexité des projets ou, pire: brûler de précieuses ressources en « coupant les coins ronds». Nous pouvons y faire face en mettant en commun des ressources et des expertises diversifiées et en élaborant d’autres méthodes de travail. Donnons-nous du temps, mais commençons dès maintenant.
Ajout d’information concernant les cas d’usage et l’approche narrative, à la suite d’une très bonne question posée par Frédéric Julien, sur Facebook.
Extrait du commentaire de Frédéric :
Je ne suis par contre pas certain de comprendre ce que tu entends par « remplacer les cas d’usage par une approche narrative ». Au cours de la dernière année, j’ai eu la précieuse occasion de participer à quelques exercices de consultation auprès de créateurs et usagers de données dans le cas du projet 3R. Ce que j’y entendu a énormément contribué à ma réflexion sur les cas d’usage dans le cadre de l’initiative ANL [Un avenir numérique lié]. Ces deux méthodologies ne me semblent pas du en contradiction l’une avec l’autre (ni avec ce que tu décris dans ton billet… à moins que certains détails ne m’échappent).
Réponse:
/…/ une approche narrative permet de réaliser des cas d’usage en les mettant en contexte (le « comment »). J’emploie un terme fort, « remplacer », pour attirer l’attention sur une étape du projet sur laquelle se fondent beaucoup d’objectifs (et d’espoirs). C’est une étape cruciale pour la mise en relation de l’information avec des utilisateurs. Elle est trop souvent escamotée ou sert uniquement à construire des exemples de requêtes. Suivre une approche narrative ne signifie pas raconter une histoire, mais analyser des comportements, des usages, des interfaces et des structures de données pour produire des exemples qui vont démontrer l’utilité ou la valeur ajoutée du système. Cependant, les cas d’usage réalisés de façon habituelle (comme en informatique), portent sur le « quoi » (les données, les étiquettes à mettre) alors que les éléments de la recherche et de la découverte ne sont plus les mêmes:
Interrogation de données liées conçue comme des requêtes sur des BD tabulaires (où est le potentiel du liage de données?)
Travail de terrain très rarement réalisé avec des utilisateurs finaux, dont des non-usagers (ex: non-visiteurs de musées) et des non-amateurs de certains type d’offres (ex: films québécois).
Confusion entre parcours de recherche et de découverte (qu’est-ce que chercher? découvrir? comment cela se produit-il dans des contextes spécifiques, avec certains supports et chez certains types d’utilisateurs ?)
La découverte optimisée pour les moteurs de recherche est-elle la seule solution pour accroître la consommation de contenus culturels locaux ? Sommes-nous à la recherche de nouveaux outils de marketing ou souhaitons-nous développer des bases de connaissances communes ? Les résultats attendus à court terme, par nos programmes et partenaires sectoriels, pèsent sur les choix qui orientent nos actions.
La découverte optimisée pour les moteurs de recherche
Alors, est-il stratégique de baliser nos pages web avec des métadonnées (aussi appelées données structurées) pour que des machines comprennent et utilisent nos contenus dans leurs fiches de réponse ?
Améliorer le potentiel d’une information d’être repérée et interprétée par un agent automatisé est une bonne pratique à intégrer dans toute conception web, au même titre que le référencement de site web. Mais se contenter de baliser des pages pour les seules fins de marketing et de visibilité n’est pas stratégique. Voici pourquoi:
Architecture de l’information conçue pour servir des intérêts économiques et culturels spécifiques.
Aucun contrôle sur le développement de la base de connaissances.
Uniformité de la présentation de l’information, quel que soit le pays ou la culture.
Modèle et vocabulaire descriptifs simples, mais adaptés à des offres commerciales (une bibliothèque publique est une entreprise locale).
Le moteur de recherche n’utilise que certains éléments du vocabulaire Schema.org et modifie son traitement des balises au gré de ses objectifs commerciaux (voir ce billet sur les mythes et réalité de la découvrabilité).
Des données pour générer de la connaissance
Les plans de marketing et de promotion ont des effets à court terme, mais ponctuels, sur la découverte. Cependant, nous devons parallèlement développer les expertises nécessaires pour concevoir de nouveaux systèmes de mise en valeur des offres culturelles et de recommandation qui répondent à nos propres objectifs. Ne pas également prioriser cette avenue, c’est accumuler une dette numérique et accroître notre dépendance envers les plateformes et tout promoteur de solution.
Comme je l’ai souligné en conclusion d’un billet rédigé lors de recherches sur la découvrabilité et la « knowledge card » de Google, « , apprendre à documenter des contenus sous forme de données est une étape vers le dévelopement de « nos propres outils de découverte, de recommandation et de reconnaissance de ceux qui ont contribué à la création et à la production d’œuvres. »
Pour cela, il faut élaborer collectivement nos propres stratégies pour faire connaître le contenu de répertoires et rejoindre de nouveaux publics. Nous serions, alors, en mesure de concevoir des moyens non intrusifs pour collecter l’information qui permet de comprendre la consommation culturelle.
Adopter une méthode de travail pour une réflexion stratégique
Concevoir et réaliser des projets autour de données liées (ouvertes ou non) demande un long temps de réflexion et d’échanges de connaissances entre des acteurs qui ont des perspectives différentes. L’initiative de la Cinémathèque québécoise peut être citée comme un excellent exemple de transformation organisationnelle par l’adoption d’une nouvelle méthode de travail. Marina Gallet pilote ce projet qui vise à formaliser les savoirs communs du cinéma en données ouvertes et liées. Elle a gracieusement partagé cette expérience lors de la dernière édition du Colloque sur le web sémantique.
Représentation de la diversité culturelle et linguistique
Il existe de nombreuses façons de décrire les oeuvres d’un album de musique ou un spectacle de danse. Pour représenter ces descriptions sous forme de données, il existe des modèles et vocabulaires pour différentes missions et utilisateurs. Une part grandissante de ces vocabulaires est en données ouvertes et liées. Ces descriptions ne sont pas toujours structurées ou conformes aux standards du web, mais leur diversité est essentielle à la richesse de l’information. Il est vital que les vocabulaires utilisés pour décrire des offres et des contenus soient en français pour que la francophonie soit présente dans le web des données et qu’elle soit prise en compte par les systèmes intelligents.
Le Réseau canadien d’information sur le patrimoine annonçait ce printemps, la réalisation de la version française de référentiels en données ouvertes et liées. Philippe Michon, analyse pour le RCIP, explique comment ces référentiels essentiels au patrimoine culturel seront rendus disponibles en données ouvertes et liées.
Recherche augmentée: découverte selon les goût et l’expérience recherchée
Il faut cesser de reproduire des interfaces et modes d’accès aux répertoires qui sont dépassés. On ne peut cependant améliorer la découverte sans investir le temps et les efforts nécessaires pour sortir de nos vieilles habitudes de conception.
Nos interfaces de recherche sont devenues obsolètes dès l’arrivée du champ unique des premiers moteurs de recherche. Nos stratégies de marketing de contenu pour le référencement de pages web aident les moteurs de recherche à répondre à des questions, mais effacent les spécificités en uniformisant l’architecture de l’information.
L’information qui décrit nos productions culturelles et artistiques est trop souvent limitée à des données factuelles. Il faut annoter des descriptions avec des attributs et caractéristiques riches et orientés vers divers publics et usages. Des outils d’analyse et de recommandation peuvent ainsi fournir de l’information ayant une plus grande valeur. Il ne faudrait pas espérer refiler ce travail à des intelligences artificielles: l’indexation automatique ne produira pas nécessairement des métadonnées utiles et pertinentes pour une stratégie de valorisation. De plus, il ne faut pas sous estimer la valeur que l’expérience humaine (éditorialisation, sélection, critique, mise en contexte) apporte à des services qui jouent un rôle prescripteur.
Soutenir le dévelopement de bases de données en graphes
La mise en valeur de répertoires et collections, ainsi que des actifs informationnels (textes, images, sons) d’organisations ne devrait plus reposer sur des bases de données classiques. Les bases de données en graphes permettent de raisonner sur des données et de générer de la connaissance , en faisant des liens, à l’image de la pensée humaine:
Quelle est le parfum de glace préféré des personnes [qui] dégustent régulièrement des expresso, mais [qui] détestent les choux de Bruxelles ? Une base de donnée Graph peut vous le dire. Comment ? Avec des données de qualité, les bases de données Graph permettent de modéliser les données et de les stocker de la manière dont nous pensons et raisonnons dans le monde réel.
Choisir des méthodes de travail adaptées aux projets collectifs
Pour qu’un écosystème diversifié de connaissances (multidisciplinaire, multi acteurs) soit durable, il doit reposer sur la distribution des fonctions de production et de réutilisation des données entre des partenaires. Il faut aussi réunir des initiatives collectives dans une démarche où le développement de connaissances et l’expérimentation ne sont pas relégués au second plan par des intérêts individuels ou commerciaux. Enfin, il faut élaborer et adopter de nouvelles méthodes de travail pour des projets collectifs.
Je reviendrai bientôt sur les éléments nécessaire pour la gestion participative d’une base de connaissances commune.
Architectures et bases de connaissances
Définir les finalités et les modalités des projets de liage de données est un long cheminement qui demande des apprentissages, des efforts concertés et du temps. Nos programmes devraient être revus. Mettre en place les conditions de réussite d’un projet collectif est un projet en soi. Il faut tenir compte d’un cadre de formation, d’une nouvelle méthode de travail et d’une progression dans la durée. Exiger des résultats à court terme oriente les projets vers des « solutions » et laisse peu de place à la remise en question des habitudes.
Nos initiatives doivent être conjuguées pour élaborer une architecture commune de la connaissance. Parce qu’elle sort du cadre de nos actions habituelles, c’est une avenue qui offre plus de potentiel, à plusieurs titres, que des stratégies de visibilité et de marketing.
Alan Chia [CC BY-SA 2.0], Wikimedia CommonsImiter des géants de l’économie numérique en développant une plateforme peut-il apporter des solutions aux problématiques complexes de la diffusion de contenus francophones dans une industrie traversée par de profonds changements ?
Tout récemment, une solution simple à une problématique complexe a refait surface dans le milieu culturel canadien.
Mettre en avant une « solution » technologique permet trop souvent d’éviter d’épineux questionnements. Cependant, alors que les règles du jeu et les usages changent, nous ne devrions pas nous soustraire à un examen des conditions de création et de production qui sont soutenues par nos législations et programmes. Nous finissons par maintenir, tant bien que mal, des modèles qui fonctionnent de moins en moins.
Ce ne sont pas des plateformes numériques qui ont permis à Netflix et compagnie de bouleverser l’industrie. C’est d’avoir compris le potentiel du Web et pensé autrement l’accès, la distribution et la production de contenus audiovisuels, en osant remettre en question les modèles établis. Revoir des modèles et des programmes qui demeurent encore très « télévision » demande évidemment beaucoup d’ouverture, de courage et de vision, mais il faut espérer que ce soit encore possible.
Une proposition de plateforme de diffusion de contenus culturels québécois, avait émergée, en 2017. En évitant de remettre en question les façons de faire, ce type de projet ne fait que reporter les nécessaires adaptations qu’une industrie doit entreprendre pour durer et prospérer.
Il semble que nous ayons encore beaucoup de difficulté à appréhender les problématiques de la production et de la consommation de contenus culturels dans un monde numérique. Ne serait-il pas temps d’adopter, pour les analyser, d’autres méthodes que celles qui nous font tomber le piège des solutions simplistes ?
Mise à jour 2019-05-24: ajout d’une question et sa référence, en conclusion.
La recherche du Graal de la découvrabilité, ce moyen qui accroîtra la «consommation» de nos produits culturels, peut-elle nous faire tomber dans le piège de la solution technologique qui nous fait oublier le problème ?
Solution simple et problématique complexe
Appelé « solutionnisme » par l’historien des sciences Evgeny Morozov, c’est la proposition d’une solution technologique à un problème d’origine complexe. Ceci a pour effet d’escamoter les débats qui sont essentiels à la recherche de solutions pour le bien commun.
Moins de quatre ans se sont écoulés depuis le sommet qui a propulsé le terme « découvrabilité » jusque dans les hautes sphères décisionnelles, en culture. Depuis lors, des événements et programmes de financement de la culture ont intégré cette thématique ou certains de ces éléments les plus emblématiques, comme les métadonnées.
Je réalise, depuis quelques années, des ateliers sur la découvrabilité et les métadonnées, avec les Fonds Bell et Fonds indépendant de production. Une collaboration avec Marie-Ève Berlinger apporte à ma démarche exploratoire la dimension stratégique de la promotion numérique. C’est dans ce contexte que nous avions échangé sur les mythes de la découvrabilité, au cours du Forum avantage numérique.
Voici quelques constats qui se rapportent aux mythes qui sont spécifiques à la production de métadonnées pour les moteurs de recherche.
La découvrabilité n’est pas une finalité
La finalité d’un plan de découvrabilité est le fruit d’une réflexion stratégique. Celui-ci fournit les questions, le contexte et le cadre sans lesquels la découvrabilité n’aurait pas d’autre objectif que de fournir des données à un moteur de recherche. Ce sont les activités de marketing et de promotion qui produisent des résultats mesurables.
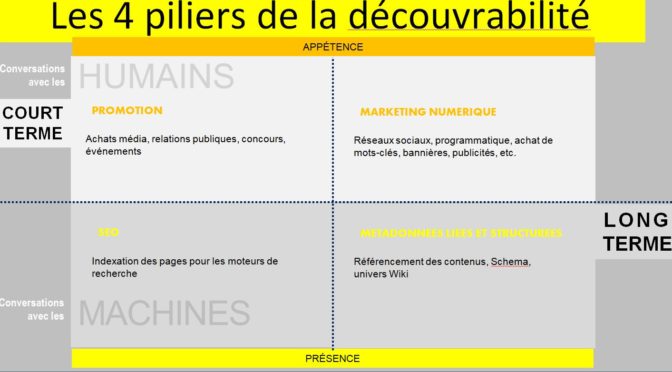
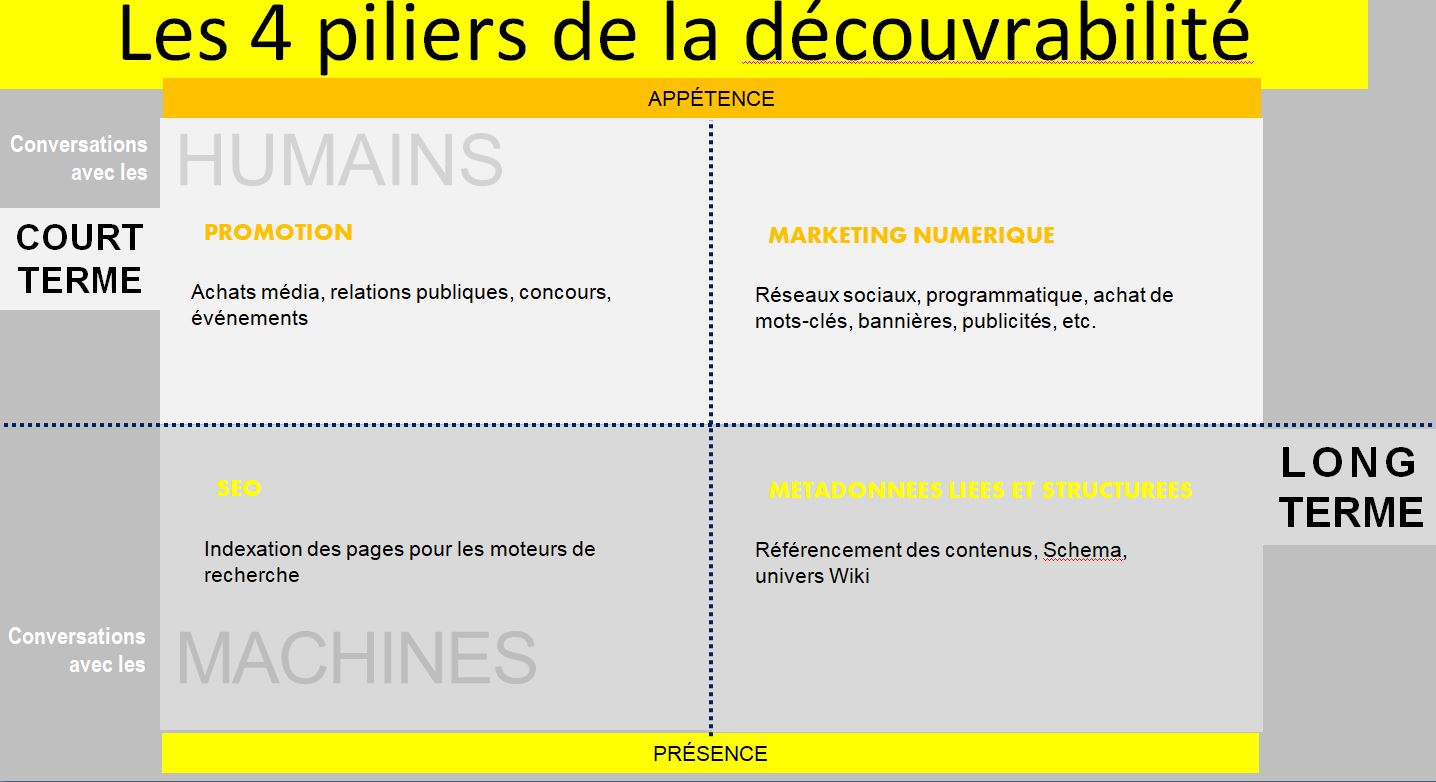
L’exploitation des métadonnées par les moteurs de recherche n’est qu’un des piliers de la découvrabilité. Cette approche a été illustrée dansle cadre d’un projet auquel je collabore, avec Véronique Marino et Andrée Harvey (La Cogency).
Illustration tirée d’un projet de découvrabilité numérique de LaCogency.
Il est surprenant de constater que la stratégie et les moyens techniques ne sont pas intimement intégrés dans des projets numériques. Il y a une importante mise à jour des connaissances conceptuelles et techniques à opérer au sein des agences qui conseillent et accompagnent les organismes et entreprises.
La réponse n’est pas une page web
La fiche d’information qui constitue la réponse du moteur de recherche (à la droite de la liste de résultats) n’a pas pour objectif de diriger l’utilisateur vers une page web spécifique. Elle rassemble différents éléments d’information afin de fournir la réponse la plus précise possible. Il faut donc sortir de la logique de la liste de résultats et ne pas penser l’usage des métadonnées en fonction d’une destination.
Les liens entre les éléments d’information qui composent la fiche de réponse construisent des parcours qui orientent la recherche de l’utilisateur, sans nécessairement aboutir sur un site web. Par exemple, chercher une oeuvre de VanGogh, comme la Nuit étoilée, permet de mesurer la distance et les clics qui nous séparent du site web du Museum of Modern Art.
Ceci accroît la collecte des données d’usage qui permettent d’analyser l’intention, le comportement et la consommation de l’utilisateur. Plus les fonctions et choix offerts sont utiles, plus l’utilisateur demeure dans l’interface du moteur de recherche. Les agrégateurs d’information, qui font face à la désintermédiation de leur services, constateront probablement une diminution progressive du volume de données qui sont collectées sur leurs pages.
L’effet des métadonnées est dans la durée
Les résultats de l’utilisation de métadonnées pour décrire des contenus ne sont pas mesurables, au sens strict.
La qualité de l’encodage des métadonnées peut être validée, mais l’outil de test ne peut juger la logique de la description (interprétation des balises uniquement). Une validation que peu de producteurs de métadonnées semblent se donner la peine de faire. Il est également possible d’attribuer un indice de découvrabilité à une information en fonction de critères spécifiques.
L’effet des métadonnées peut être observé sur un temps long. L’enrichissement progressif de la fiche de réponse illustre le potentiel qu’a une offre d’être liée par le moteur de recherche à d’autres informations. Il n’est pas possible de fournir des résulats immédiats et quantifiables, de façon similaire aux stratégies de référencement organique et payant de pages web.
Schema.org n’est pas le moteur de recherche
Schema est un vocabulaire commun de métadonnées qui a été développé pour les moteurs de recherche. Google recommande l’intégration des métadonnées sous forme de balises dans le code HTML d’une page afin de décrire l’offre qui y est présente. Cependant, les règles de l’algorithme évoluent au fil des expérimentations du moteur de recherche. Les métadonnées Schema qui étaient recommandées pour décrire des offres de type Movie, TVSeries et Music existent toujours. Cependant, Google n’en recommande plus l’usage et invite les entreprises concernées à faire une demande pour devenir des partenaires médias. Jusqu’où, alors, faut-il investir pour indexer une offre si le fonctionnement de l’algorithme et l’évolution du moteur de recherche nous sont inconnus ?
Une réflexion stratégique est nécessaire pour répondre à cette question. Deux avenues s’ouvrent:
1. Rendre des offres interprétables pour les moteurs de recherche (indexation) et appuyer la stratégie de référencement du site
Fournir uniquement les métadonnées Schema qui sont obligatoirement requises par le moteur de recherche. Ceci fait partie des bonnes pratiques du développement de sites web.
Tout comme pour le référencement, il est important d’assurer une veille sur l’évolution des fonctions analytiques et techniques des moteurs de recherche.
2. Valoriser les éléments d’un catalogue ou d’une collection en produisant un graphe de données liées
Fournir des métadonnées très riches selon le vocabulaire Schema.
Prévoir un important travail de modélisation (de préférence, par une personne compétente) afin de mettre en valeur des attributs et des liens, en travaillant sur les propriétés et les niveaux hiérarchiques.
Enjeux d’importance pour une stratégie numérique:
Aucun résultat garanti sur le traitement des métadonnées par le moteur de recherche. Ceci ne doit donc pas être l’unique objectif d’un tel projet.
Vocabulaire et modèle de représentation uniques: uniformisation de la représentation répondant aux objectifs d’affaires des moteurs de recherche.
Précision 2019-05-25: ce billet concerne uniquement le langage de balisage pour moteurs de recherche (métadonnées Schema) et non la représentation des connaissances avec les standards du web sémantique.
Pas de solution, mais quelques questions
L’uniformisation des modèles descriptifs est-elle un risque pour la diversité culturelle ?
La problématique de la «consommation culturelle» ne devrait-elle pas être abordée dans les deux sens ? En orientant nos projets sur la promotion, nous oublions la relation au public et l’analyse de ce qui rend une oeuvre de création attractive. Ce rapport sur les pratiques culturelles numériques et plateformes participatives, piloté par la chercheuse Nathalie Casemajor, contient des pistes de réflexion à ne pas négliger, dont cellec-ci:
Les efforts de découvrabilité ne suffisent pas à eux seuls à créer l’appétence culturelle, et l’analyse des données consommatoires et comportementales n’est pas la panacée pour agir sur le développement des goûts et des dispositions culturelles en amont.
Nous devrions nous donner des moyens pour définir les modalités et conditions de la découvrabilité que nous souhaitons. Celles-ce se trouvent quelque part, entre le monde vu par une entreprise et celui que nous voyons au travers du prisme de nos cultures et sensibilités, d’une part, et, d’autre part, entre lier des données pour un objectif de marketing et faire du lien social autour d’objectifs communs.







{kind=link}
![Elliott Brown [CC BY 2.0], Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Perry_Barr_Station_-_Mind_the_Gap_(7851041352).jpg){kind=link}