Mise à jour 2016-12-10: Clarifications suggérées par Christian Aubry. Illustration: substitution du terme « lisibles » par « compréhensibles ». Conclusion: clarification du sens du paragraphe.
Où en est le web ? Les signes d’une transformation importante sont bien présents, mais diffus et disséminés parmi les différentes facettes d’un amalgame de technologies, connaissances, modèles de pensée, industries, usages et comportements. L’annonce d’une initiative européenne de valorisation de la connaissance dans un web spatiotemporel, Time Machine, évoque une très proche discontinuité :
La seconde révolution de l’Internet commence maintenant, avec la mort annoncée des moteurs de recherche du présent et l’entrée en scène d’une manière d’indexer l’information.
Nous sommes entrés dans une ère où il ne sera plus nécessaire de quitter l’interface d’un moteur de recherche pour accéder à la connaissance et où les applications de recommandations s’alimentent à de larges ensembles de données structurées et signifiantes.
De moteurs de recherche à moteurs de réponses et de connaissances
La liste de résultats des moteurs de recherche fait graduellement une place de choix à une réponse ou une proposition. Bien que les machines ne parlent pas le langage des humains, elles peuvent interpréter la syntaxe et les marqueurs qui sont utilisés spécifiquement pour décrire une chose, une personne ou un concept abstrait.
La fiche qui apparaît dans le coin supérieur droit de l’écran du moteur de recherche Google tend à prendre plus d’espace alors que nous apprenons à publier l’information que nous souhaitons visible, persistante et connectée. Pour cela, il faut aller bien au-delà des techniques d’optimisation de pages web et apprendre à publier les données qui décrivent nos contenus selon des modèles normés. L’information représentée selon un modèle et des métadonnées standards devient alors compréhensible et exploitable pour les applications qui ratissent le web.
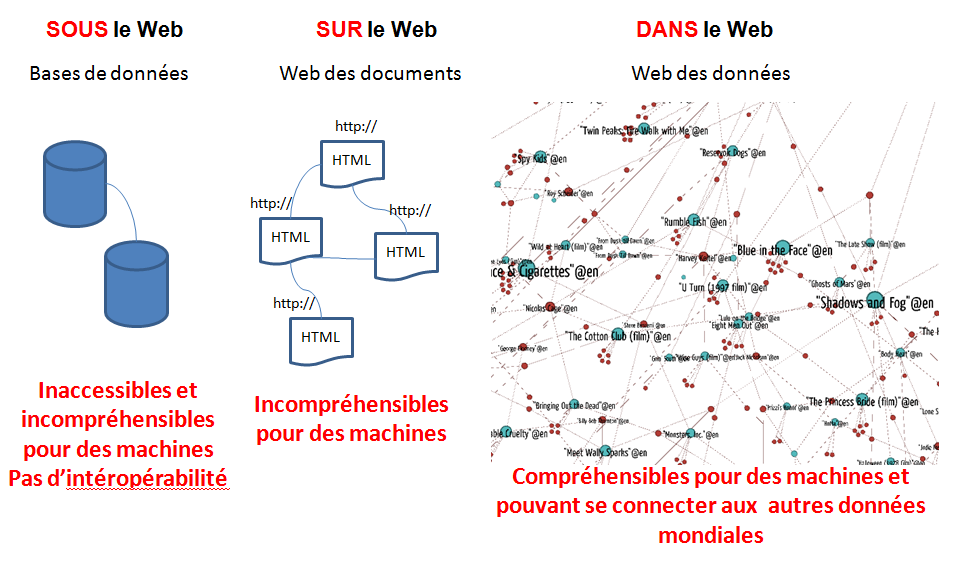
Du web des documents au web des données (et du sens)
Mais où sont les données qui décrivent nos contenus culturels ?Elles sont sous le web, malheureusement Les répertoires, collections, fonds et même, les calendriers de représentations et de tournées sont stockés sous forme de bases données. Celles-ci ne sont pas accessibles aux machines qui repèrent et collectent des données pour les moteurs de recherche, agrégateurs, systèmes automatiques d’archivage et autres moissonneurs de données qui s’activent dans le web. Même si ces machines avaient accès aux bases de données, elles ne disposeraient pas des clés nécessaires pour reconstituer et interpréter l’information.
Les modèles numériques carburent à la donnée
Au constat de l’absence de notre patrimoine et de nos productions artistiques et culturelles du web s’ajoute celui de l’absence d’une culture de la donnée. Comme je le partageais dans un mémoire sur le renouvellement de la politique culturelle, sans maîtrise de la donnée:
- Les tenants et aboutissants de la transition numérique accomplie par les précurseurs nous échappent et nous n’en retenons que les manifestations externes.
- Nous demeurons uniquement les fournisseurs de contenu des plateformes qui tirent dorénavant plus de valeur des données décrivant ces contenus et celles qui sont générées par leur utilisation que des contenus eux-mêmes.
- Nous ne pouvons pas repérer et interpréter les signaux faibles du changement et nos indicateurs de mesure ne permettent pas une lecture adéquate des multiples facettes de la vie culturelle dans nos univers physiques et numériques.
- Nous nous limitons à la promotion des nouveautés pendant que nos catalogues, répertoires et collections, échappent à la découverte et à la possible réutilisation qui leur donnera une seconde vie.
Afin d’illustrer mon propos, voici une anecdote: j’ai passé près de deux heures à explorer de nombreuses œuvres musicales en me renseignant sur la musique western. J’ai exploré les chansons des sœurs Boulay et je me suis éparpillée entre des productions commerciales et artisanales. Je n’ai pas quitté Google, en passant de vidéos à des listes de titres populaires.
C’est bien pour la découverte de la musique d’ici, mais:
- Qui a collecté mes données personnelles et d’usage ?
- Qui a accru sa connaissance d’un marché en analysant mon comportement et mes préférences ?
- Qui a engrangé la matière première qui fait de ses services, aussi efficaces qu’attractifs, un modèle d’affaires extrêmement profitable ?
Découvrabilité: pour développer une culture de la donnée
Ce n’est pas la découvrabilité numérique qui fait la réussite des modèles d’affaires des plateformes numériques, c’est ce qui lui permet de réaliser son potentiel: l’exploitation et la valorisation de l’information. Or, dans nos universités, nos programmes de sciences de l’information sont presqu’exclusivment orientés vers la gestion de collections de documents et, du côté des technologies de l’information, le web des données n’est qu’un sujet optionnel du programme de maîtrise. Il serait temps d’élaborer un programme universitaire de deuxième cycle pour allier les perspectives et connaissances en information (indexation et modélisation) et en informatique (web sémantique).
Si nous ne maîtrisons pas les principes et techniques nécessaires à l’exploitation de nos contenus culturels dans le web, comment pourrons-nous soutenir les nouveaux acteurs d’une économie numérique ? Comment répondrons-nous aux besoins d’expertise dans les créneaux émergents comme l’intelligence artificielle, les crypto monnaies (Bitcoin) ou les registres de transactions distribués (Blockchain) ?
6 réflexions sur « Contenus culturels: sous, sur ou dans le web ? »