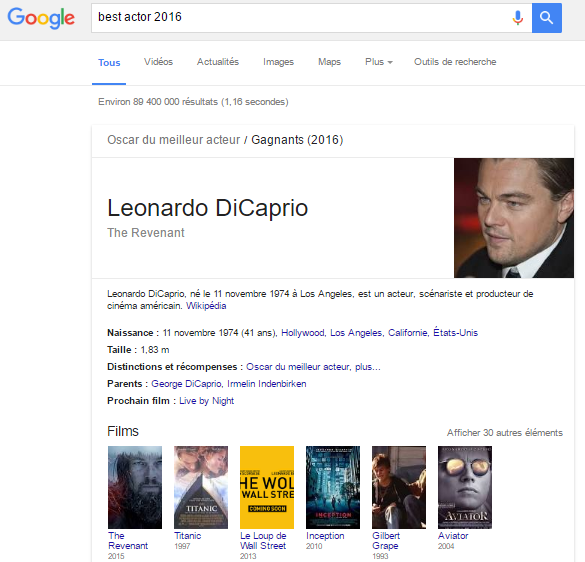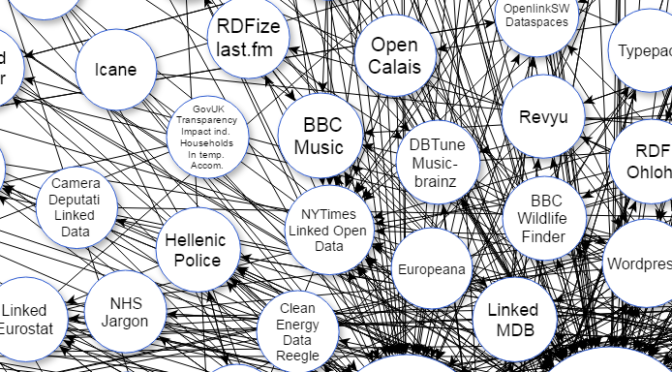
Tenter de concurrencer les géants des contenus numériques en proposant nos propres plateformes, comme le proposait Alexandre Taillefer, est une mauvaise bonne idée; surtout dans le domaine culturel. Voici pourquoi:
NON: centraliser l’information dans une base de données
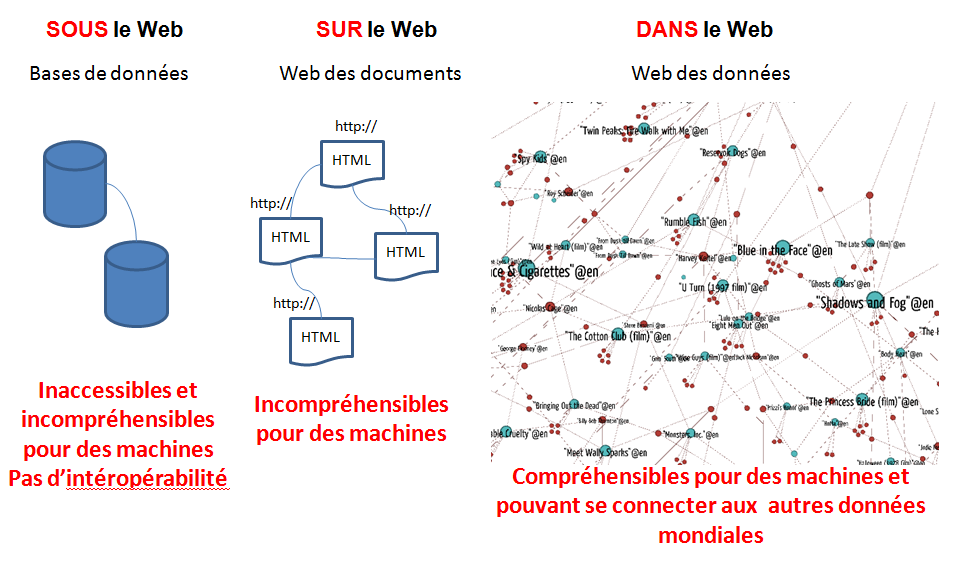
C’est une mauvaise idée, parce qu’il s’agit d’un concept qui va à contre-courant de l’Internet de Tim Berners-Lee: connaissances partagées, production de contenus décentralisée, modèles distributif et collaboratif, données ouvertes et liées, perspectives à la fois locale et globale. Développer une plateforme afin de centraliser dans une base de données l’information concernant des contenus culturels c’est soustraire ces derniers aux connexions potentielles avec d’autres données à travers le monde.
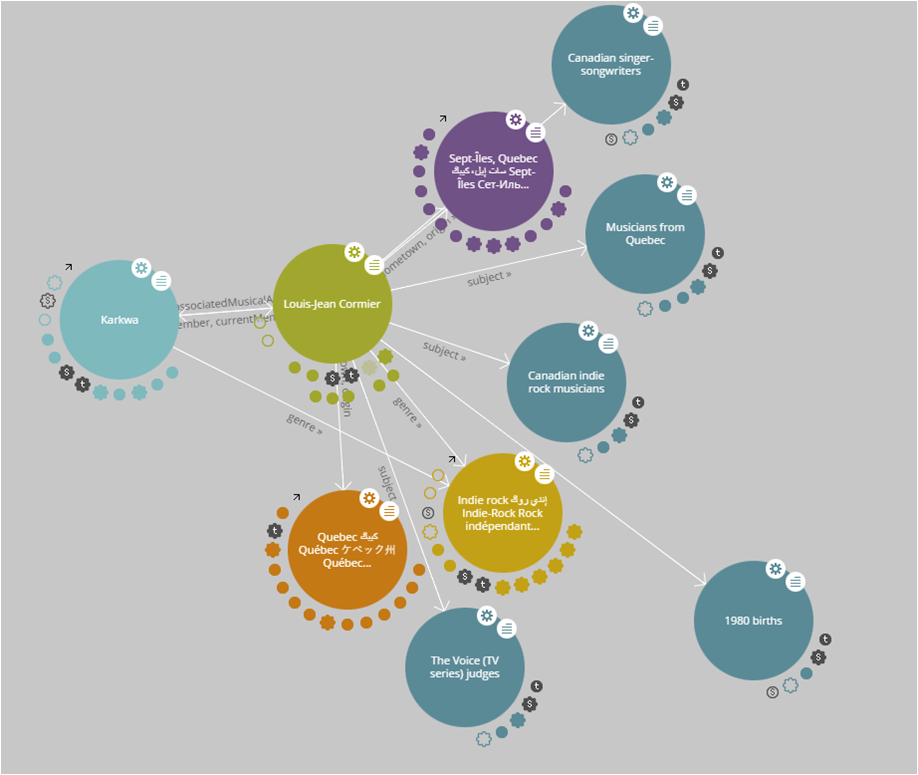
Le contenu des bases de données est « sous le web« , c’est à dire inaccessible et incompréhensible pour les moteurs de recherche et applications qui ratissent le web en quête de données qui font du sens. La transition d’un web des documents vers le web des données, et, par conséquent, de la préférence visible des moteurs de recherche pour le sémantique (Google et les données structurées), ne font plus de doute. S’exposer dans le web des données ouvertes et liées constitue une bien meilleure stratégie, pour la valorisation des contenus, le développement de modèles économiques et l’acquisition d’une culture de la donnée, que la reprise d’un concept datant du premier âge du web.
Alors, pourquoi continuer à financer des silos d’information qui interdisent toute possibilité de liens entre nos contenus et l’intention ou le parcours de consommateurs , où qu’ils se trouvent ?
OUI: mutualiser les ressources pour publier et agréger des données
La bonne idée est celle de la mutualisation d’équipement et de ressources pour réaliser un projet collectif. Là se trouve le véritable défi de la « révolution numérique »: apprendre à se faire confiance et à collaborer pour développer une valeur collective. Apprentissage d’autant plus difficile que l’offre culturelle est abondante et que notre attention, elle, est limitée.
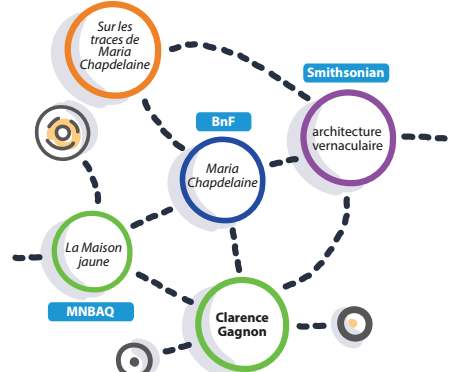
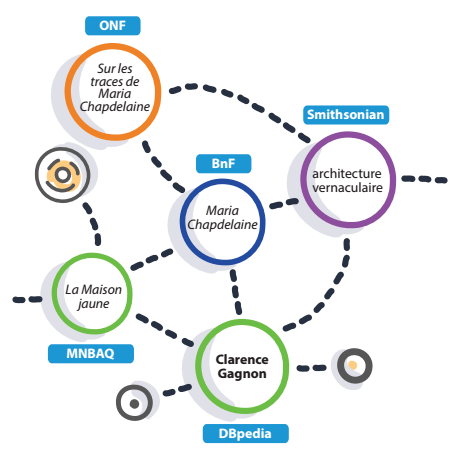
Publier des données dans le web, comme on le fait pour des pages de sites internet, permet d’éviter les problèmes d’interopérabilité des bases de données tout en préservant l’autonomie des producteurs de données. Il devient, par la suite, possible de collecter et d’agréger ces données afin de les exploiter pour les rendre réutilisables pour des organismes touristiques, pour créer des interfaces d’exploration et, même, pour concevoir des agents intelligents qui feront des suggestions de contenus personnalisées. Mieux que tout autre documentation, cette vidéo produite par la Fondation europeana, explique en 3 minutes ce qu’est le web des données ouvertes et liées et pourquoi il est devenu si important pour la diffusion de la culture.
Le développement de cette infrastructure commune peut être pris en charge par l’État, comme c’est le cas pour Europeana, où l’Union européenne et chacun des états contributeurs, soutiennent les infrastructures et ressources qui permettent aux institutions culturelles de publier leurs données collectivement. L’État peut également faire appel au milieu académique et au secteur de la recherche, à l’image de l’entente récemment conclue, en France, entre le Ministère de la Culture et de la Communication et l’Inria, afin de soutenir le projet SemanticPedia.
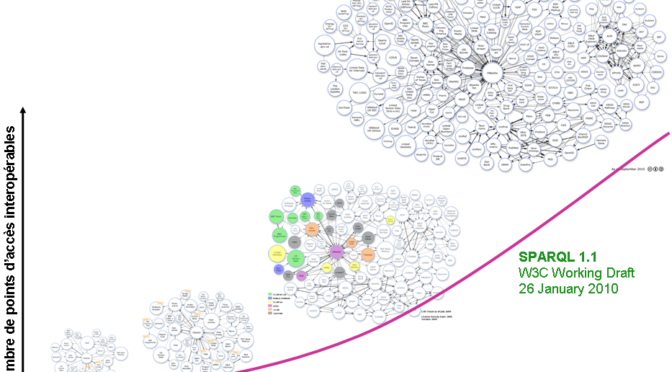
Bien que le web sémantique soit utilisé dans des domaines aussi divers que les services hydroélectriques (Hydro-Québec) et la radiodiffusion (BBCMusic), nous persistons à nous tourner vers des technologies conventionnelles pour diffuser nos contenus culturels. Passer de l’informatique au numérique est clairement un changement difficile à opérer, même dans une industrie de pointe.
Pour aller plus loin
Pour les technophiles: Le web sémantique en 10 minutes, vidéo produite lors de l’édition 2016 du colloque sur le web sémantique au Québec, dans le cadre du 84e congrès de l’ACFAS.