
Présentation donnée lors de la clinique d’information du Fonds Bell, le 17 octobre 2017, à la Cinémathèque (Montréal).
Mise à jour (16 février 2018): Cette présentation accompagnait le lancement du guide Êtes-vous repérables ? Guide pratique pour documenter vos contenus , réalisé pour le Fonds indépendant de production, avec la collaboration de TV5.ca et l’appui de la SODEC .
La découvrabilité qui devrait intéresser plus particulièrement tout créateur et producteur de contenus résulte de la présence, dans le web, de données descriptives qui sont intelligibles et manipulables par des machines. Il ne s’agit pas de campagnes de promotion, ni de référencement de pages web, mais de la documentation de contenus (textes, images, vidéo, enregistrements sonores et toutes autres types de ressources). Ces trois types d’activité visent des objectifs spécifiques et complémentaires.
Les changements qui affectent la visibilité et la découvrabilité
La plus grande proportion du trafic sur le web est portée par les petits écrans mobiles.

Liens utiles:
Smartphones are driving all growth in web traffic
Search engine market share – Mobile – Canada
Cahier de Tendances N°11 : au delà du mobile, France Télévisions
Les moteurs de recherche s’adaptent aux petits écrans.
Lorsque l’information qui décrit un contenu est disponible dans un format que les moteurs peuvent traiter, la liste des résultats de recherche passe au second plan.
Face à la surabondance d’information et de contenus, la pertinence de la recommandation devient un facteur important de fidélisation.
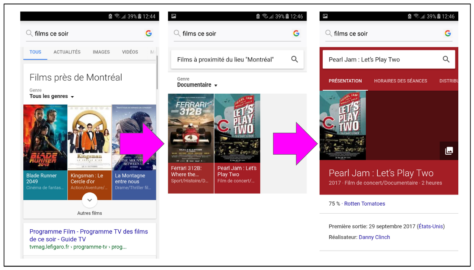
Recherche vocale et assistants virtuels: l’information sans écran.
Plus de 30 millions d’assistants vocaux dans les foyers, aux États-Unis, d’ici la fin de l’année

Liens utiles:
More than 30 million ‘voice-first’ devices in US homes by year end [Report]
Report: 57% of smart speaker owners have bought something with their voice
Gartner Predicts 30% Of Searches Without A Screen In 4 Years
Ces nouvelles interfaces du web n’ont pas d’écran et ne peuvent dont nous répondre en nous fournissant une liste de résultats.
« Enfin et c’est cela qui pose à mon sens le plus gros problème dès que l’on sort de la seule sphère « commerciale », il y a … « le choix d’Alexa », c’est à dire l’idée que bien sûr Amazon / Alexa ne va pas nous « lire » une série de réponses suite à notre requête mais nous en proposer une seule, mettant naturellement en évidence des produits vendus par la marque hôte.» (La voix et l’ordre, billet d’Olivier Ertzscheid).
Moteurs de réponses et de suggestions
Lorsque les données qui décrivent un contenu sont accessibles, intelligibles et manipulables par des applications, elles peuvent être triées par des algorithmes et liées à d’autres données qui décrivent un même auteur, lieu, création, objet, producteur, etc. Un contenu peut se trouver sur la parcours d’un internaute des décennies après sa création.
Liens utiles:
Les sites web sont-ils en voie de disparition ?
#DIVERTISSEMENT Les algorithmes vont-ils mettre fin à la tyrannie du choix ?
How Netflix will someday know exactly what you want to watch as soon as you turn your TV on
Les moteurs de recherche comprennent-ils nos contenus?
Les pages web sont faites pour être lues par des humains. Les machines ne comprennent pas le contenu de la page, mais elles peuvent manipuler des données qui s’y trouvent lorsque celles-ci sont mises en contexte grâce à des métadonnées et sont dans un format qu’elles reconnaissent.
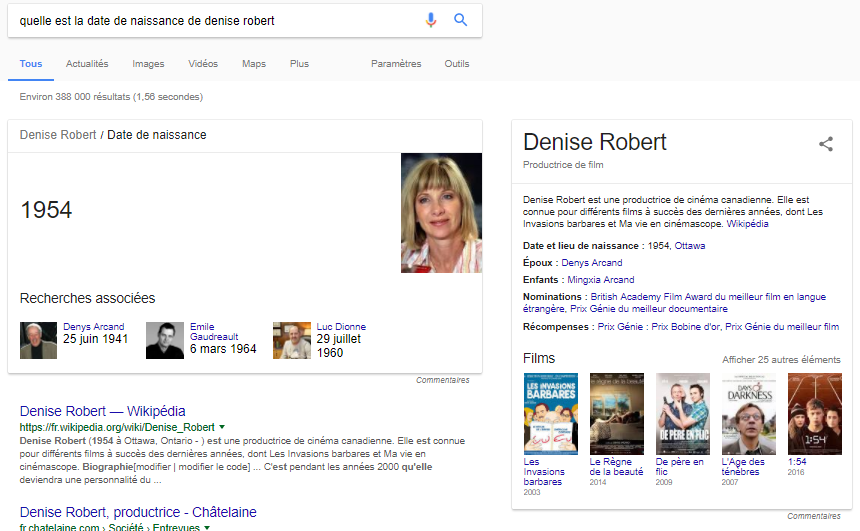
Pour savoir si un moteur de recherche peut faire des liens entre votre websérie et d’autres informations disponibles dans le web, il suffit de chercher celle-ci afin de voir si une fiche d’information est produite.
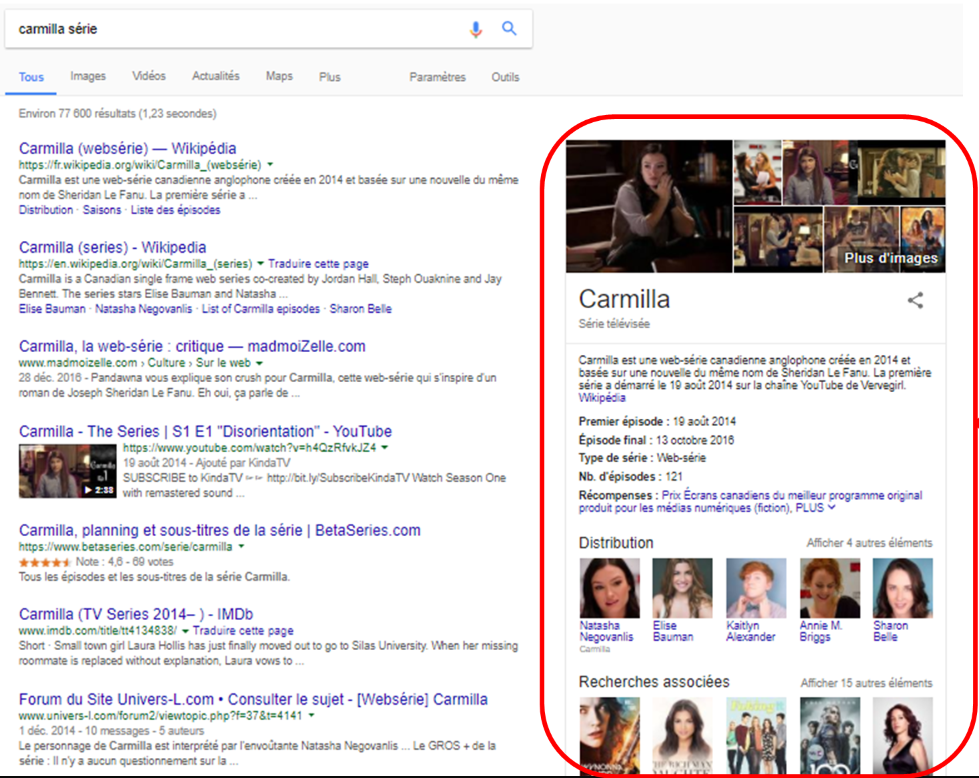
Chez Google, la fiche d’information, appelée Knowledge card, est générée grâce à la mise en contexte des données qui décrivent le contenu avec son modèle de classification des connaissances (Knowledge graph). Ces mêmes données descriptives sont mises en relation avec celles d’autres plateformes comme Wikidata (les données structurées de Wikipédia) et, selon le contexte, avec les données de plateformes spécialisées.
Dans le domaine du cinéma, de la vidéo et de la télévision, nous pouvons retrouver les données issues des agrégateurs IMDb (Internet Movie Database, propriété d’Amazon), AlloCiné et Rotten Tomatoes. Notez que le contenu de ces plateformes n’est pas produit par une seule organisation, mais par des utilisateurs et/ou des producteurs de contenus.
Ce sont des données structurées qui, chez les moteurs de recherche comme Google et Bing , permettent de faire des liens sémantiques qui fournissent une description succincte ou détaillée d’un contenu dans une fiche d’information. C’est cette fiche qui tend à occuper un espace de plus en plus important sur nos écrans.
De la même manière qu’il a fourni aux développeurs des instructions pour faciliter le référencement de sites web, Google fournit désormais des instructions et des outils pour encourager la production de données structurées. L’outil de test des données structurées détecte la présence de ces données dans une page web et, le cas échéant, signale les erreurs à corriger et les améliorations possibles.
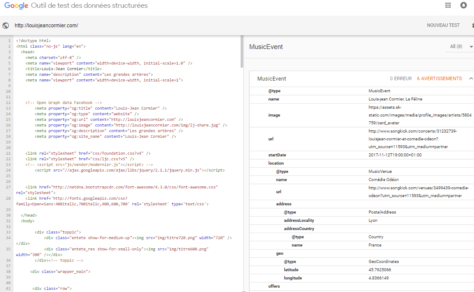
Il est également possible de produire des métadonnées pour décrire un contenu qui est présent dans une page web sans connaître le modèle de métadonnées Schema et sans programmation. L’outil d’aide au balisage des données structurées qui est proposé par Google permet de copier les données qui sont encodées en JSON-LD, un format pour les données liées, et de les coller dans le code HTML de la page web où se trouve le contenu.

Cet outil présente un intérêt supplémentaire: il indique les informations qui devraient apparaître dans la page de présentation d’un contenu. De trop nombreuses pages web où sont présentés des films, spectacles, livres, pièces musicales ou œuvres d’art ne contiennent pas le minimum d’information qui permettrait aux moteurs de recherche de les lier à d’autres informations dans le web.
Plus l’information qui décrit le contenu est détaillée et riche, plus grand est le potentiel de celui-ci d’être lié à d’autres contenus et donc, d’être découvert.
Documenter nos contenus, n’est-ce pas travailler pour Google et cie?
Documenter (ou indexer) un contenu, tout comme faire du référencement de pages web, c’est normaliser et organiser la représentation de celui-ci. C’est, effectivement, contribuer à l’amélioration continue des applications et des algorithmes des moteurs de recherche.
Mais c’est également une étape nécessaire pour apprendre à nous servir de nos données et, par la suite, développer nos propres outils de découverte, de recommandation et de reconnaissance de ceux qui ont contribué à la création et à la production d’œuvres.
3 réflexions sur « Découvrabilité : quand les écrans ne sont plus nécessaires »